一、最大熵模型
1、模型介绍
- 基本思想:我们希望数据是均匀分布的,除非我们有其他的限制条件让给我们相信数据不是均匀分布的。均匀分布代表高熵(high entropy)。所以,最大熵模型的基本思想就是我们要找的分布是满足我们限制条件下,同时熵最高的分布。
- 熵:表示分布的不确定性的度量。就算公式如下:
- 举例而言:抛一枚硬币的熵如下图,横轴表示抛到正面的概率
- 特征限制:放到实际场景来考虑这个问题的话,我们所找的分布是在满足特征限制的情况下的最大熵分布。特征限制公式如下:
- 添加特征限制会导致:得到的分布有更低的最大熵,但是提升它对数据的最大似然(likelihood);使得分布离均匀分布更远,但是会更接近数据的实际分布。
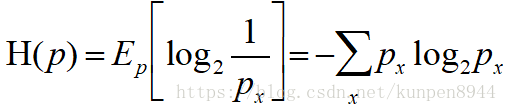

2、例子介绍
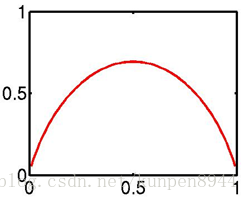
- 例子1:抛硬币问题,限制一是:P(抛正面)+P(抛反面)=1,限制二:P(抛正面)=0.3
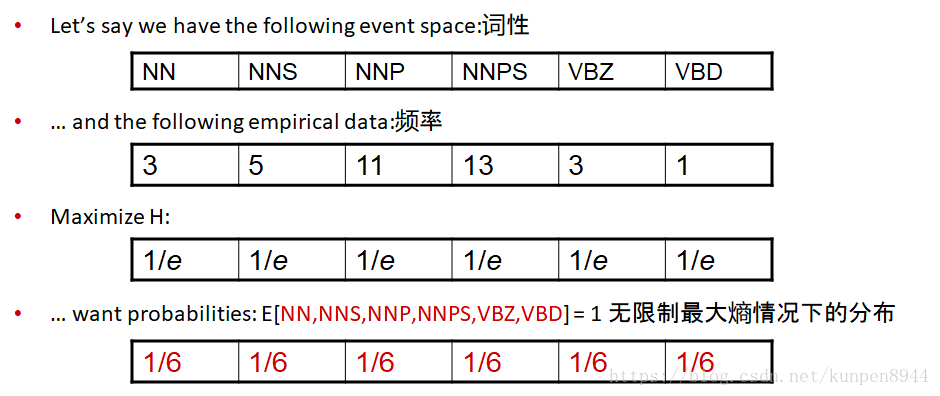
- 例子2:已知一段文本中的元素的词性以及对应的频率,这个是我们的数据。基于此我们来寻找最大熵模型。

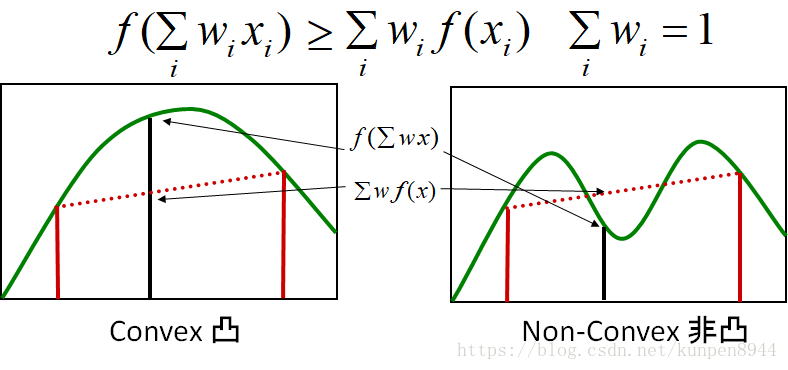
3、凸性
- 凸的定义,满足如下公式的函数就表示该函数有凸性,凸性保证函数只有一个单独的全局最大值。
- 基于凸的推导可得:有限制条件的熵是凸函数
- -xlog(x)是凸函数;因为凸函数的和也是凸函数,所以-∑xlog(x)是凸函数;限制条件是一个线性子空间,也是凸函数;所以有限制的熵就是凸函数。因此指数模型的最大似然也是凸的。
二、最大熵模型中的特征重叠(overlap)
1、特征重叠(overlap)
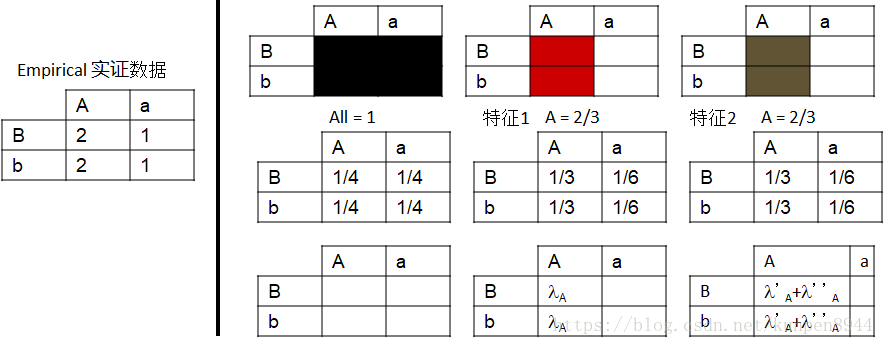
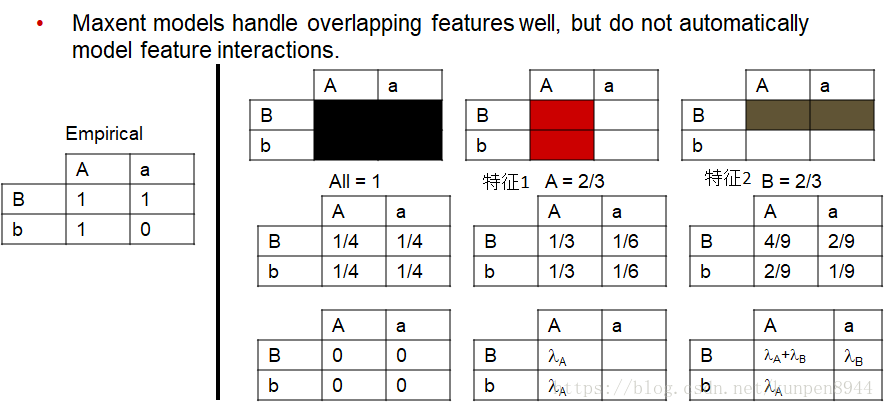
- 正如我们在之前论述的那样( Introduction to NLP by Chris & Dan翻译 第八课 最大熵模型与判别模型 的第五节),重复的特征对最大熵模型没有影响,但是会对朴素贝叶斯产生影响。可以看到下面的例子中,两个特征都是A=2/3,对估计的结果没有影响。
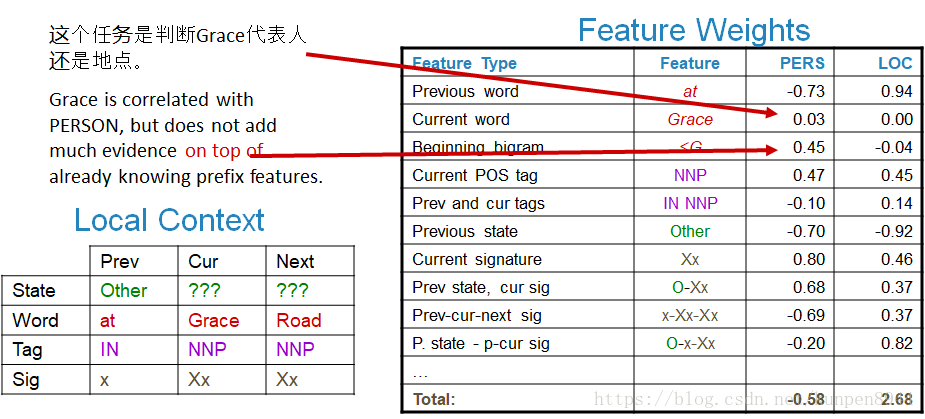
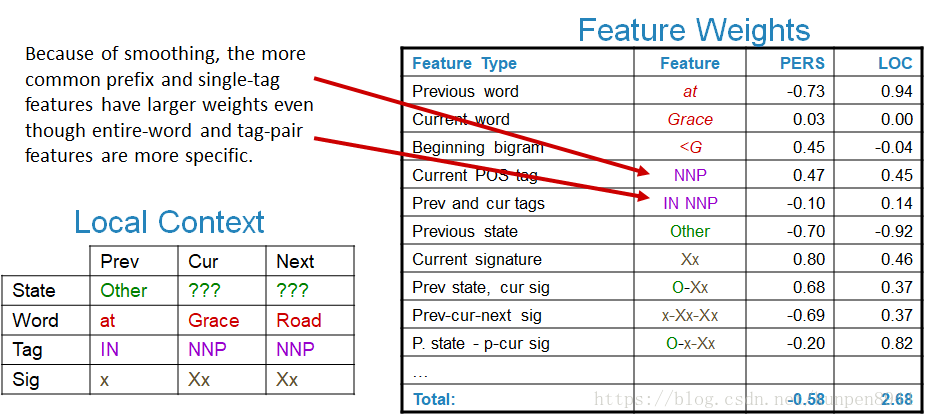
从下面的例子中,我们也可以看到:Grace和<G这两个特征(用箭头指的特征)存在着一定程度的重叠,因此特征Grace的权重就接近于0。
2、特征交互(interaction)
- 如果想在最大熵模型中构建特征交互项,我们就需要直接加入交互项特征。例子如下:
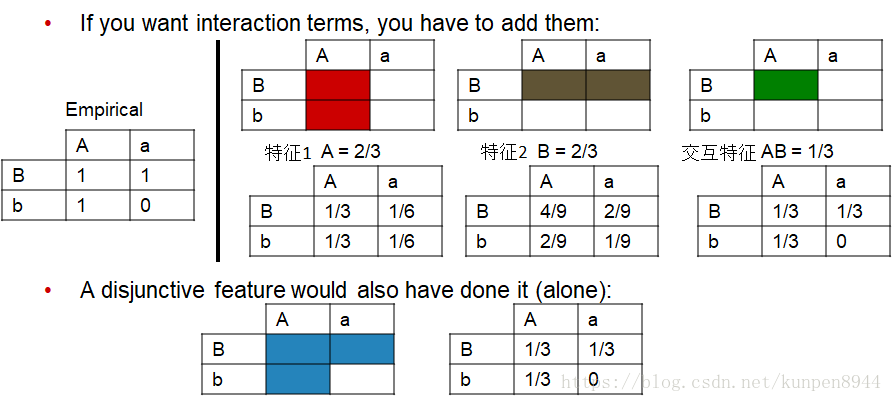
3、特征选择
- 逻辑回归中的交互特征选择是用贪婪逐步搜索(greedy stepwise search)
- 但是随着本身的特征增长,可能有效的交互特征是指数型增长的,所以这种选择只在有4-8个特征的时候是有效的。
- 在自然语言处理中,我们经常会使用到成百上千的特征,所以我们不能使用这样的选择方法。
- 一般而言,交叉项是基于语言直觉(linguistic intuitions)直接选择的。
三、条件和联合指数模型的关联
- 对联合模型P(X)和条件模型P(C|D)而言,我们可以认为C×D是一个复杂的X,其中
- C比较小:2-100个种类
- D非常巨大:文档空间是很巨大的
- 我们构建模型P(C,D),基于此我们计算特征的期望
- D是无限的,但是就我们的数据而言,d是有限的。所以我们可以在这个模型 中加入一个特征,并且对它进行限制以匹配我们的实证数据。
- 这样大部分的P(c,d)就是0,这样我们就可以把期望改写成
- 这个改写的途径就是把P(c,d)改写成下面的公式,也就是包含P(c|d)的模式
- 因此,实际上这两个模型的关联在于,条件模型实际上就是有边界限制的联合模型(这个限制是对观察到的数据分布的匹配)。
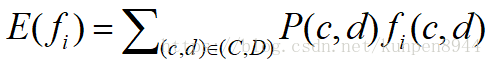
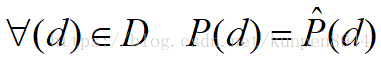
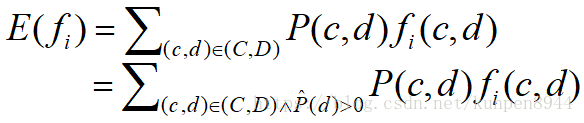
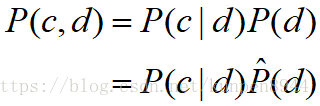
四、最大熵模型的平滑
1、为什么要进行平滑?
- 特征很多:NLP最大熵模型有超过一百万的特征,即使对这些参数进行简单的存储都会导致很大的内存负担。
- 稀疏很多:很容易导致过拟合,很多在训练的时候用到的特征可能在测试的时候不会再出现了。
- 优化问题:特征的权重可能是无穷大,迭代去需要花很多时间才能到无穷大
- 举例而言
在上面的第三种情况中,会出现λ无穷大的情况,导致优化过程会非常漫长;并且它假设一直会出现正面,本身就没意义。


2、平滑方法一:早停(early stopping)
- 在进行几轮的迭代之后,停止优化。
- λ值就不会无穷大(但是会很大)
- 优化不会无穷无尽地进行下去了
- 经常被用在早期的最大熵模型中
3、平滑方法二:先验(priors( MAP))
- 设定存在一个先验期望:参数值不会很大。这样我们就可以利用先验(priors)来平衡实证导致的无穷大的参数,使其平滑。
- 实现方法:把优化目标改为最大后验似然
- 先验(prior)项:高斯/二次/L2先验
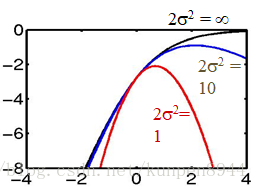
- 基本思想:先验期望是每个参数都遵循平均数为μ方差为σ²的高斯分布。如果参数离他们的平均先验值(通常μ=0)很远的话就会对他们进行惩罚。
对于σ²而言,它的作用是调节参数离开μ的容易程度,如果很小的话,会使得参数更容易接近0。一开始的时候,比较合适的值是σ²=1/2,后期可以再调整。
我们可以把高斯先验的优化目标写为:
它的导数是:
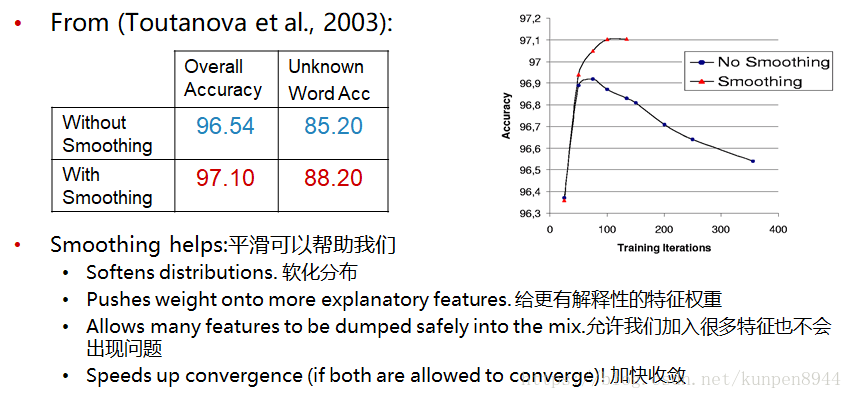
- 高斯先验牺牲了一部分的期望匹配来获得更小的参数。也就是那些有更多数据符合的特征会有更高的权重。如下面的训练数据所示,符合NNP特征的数据比符合IN NNP特征的数据多,因此NNP特征的权重也更高。同时正确率也会提升。
- 基本思想:先验期望是每个参数都遵循平均数为μ方差为σ²的高斯分布。如果参数离他们的平均先验值(通常μ=0)很远的话就会对他们进行惩罚。
- 例子:词性标注
- 关于称呼:在贝叶斯语境中我们一般称之为prior或者MAP估计。人们更常见的称呼是正则,高斯先验对应的称呼是L₂正则。但是实际上这几种称呼对应的方法在数学上没有区别。

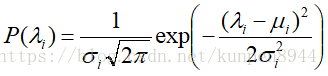
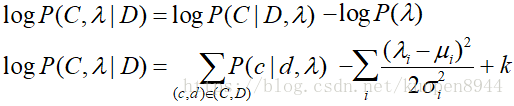
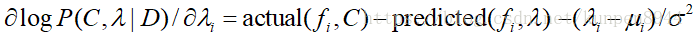
4、平滑方法三:虚构数据(virtual data)
- 基本思想:平滑数据而不是平滑参数。这个方法和生成模型的加一平滑非常相似。
- 主要的问题是当特征很多的时候,虚构数据会非常困难。
- 例子如下:
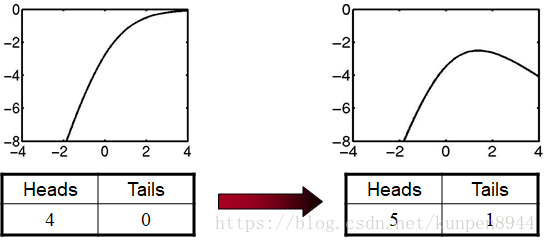
5、平滑方法四:计数切断(count cutoff)
- 主要的想法就是直接把那些实证计数比较少的特征丢掉
- 非常弱和不直接的平滑方法
- 相当于把这些特征的权重改为0
- 相当于加入了一个平均值为0方差为0的高斯先验
- 丢掉的那些计数很少的特征确实大部分是需要平滑的 ,同时它也降低了模型的规模加速了估计,但是和平滑相比它会伤害一定的准确性。
- 我们认为尽量不要使用计数切断,除非是基于内存的原因。