一、介绍
1、信息抽取(information extraction)
- 信息抽取(IE)系统
- 找到并理解文本中的有限的相关性
- 从很多的文档之中收集信息
- 产生一个相关信息的结构化的表征
- 目的:
- 进行信息的组织使之对人有用
- 以相对精确的语义形式存放信息方便计算机算法后续的查找
- 信息抽取(IE)系统一般会抽取清晰的实际的信息(谁对谁做了什么在什么时候)
- 低程度的信息抽取
- 一般被用在苹果或者是谷歌的邮件上,或者是web索引。通常是基于正则表达和名字列表。
- 一般被用在苹果或者是谷歌的邮件上,或者是web索引。通常是基于正则表达和名字列表。

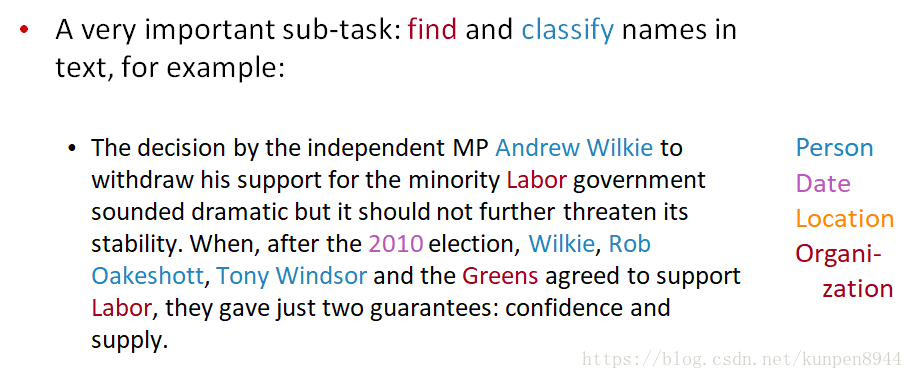
2、命名实体识别(named entity recognition)
- 这是在信息抽取中十分重要的一个分支:找到并识别文档中的名字
- 主要用途:
- 命名实体的索引(index)和链接(link off)
- 分析情感指向的公司或者产品
- 很多信息抽取的关系都是和命名实体相关
- 在问题回答(question answer)领域,答案往往是命名实体。
二、命名实体识别的评估
- 正确识别一个命名实体,需要包含两个方面,一方面需要找到表示命名实体的词组,另一方面对命名实体正确归类,如果下图所示:
- 对命名实体识别(NER)或者信息抽取(IE)而言,用之前介绍的recall和precision来进行评估会存在一个问题:没有办法定义边界错误(boundary error)。举例子而言:
对于句子:First Bank of Chicago announced earnings…而言,机器识别Bank of Chicago作为实体,但实际First Bank of Chicago才是命名实体。对于这样的错误,我们在归类的时候即可以归到FN也可以归到FP。所以,基于这样的度量标准,实际上边界错误比无法识别(只会归类到FN)更严重。 - 其他度量,比如MUC得分会好一些

三、命名实体识别的序列模型(sequence model)
1、命名实体识别(NER)的机器学习序列模型
- 训练
- 收集一系列有代表性的训练文档
- 给每个token标注它的类别,如果不是命名实体的话就标注other(O)
- 设计适合文档和类别的特征抽取机制
- 训练一个序列分类来预测数据的类别
- 测试
- 一系列的测试文档
- 运行序列模型来给每个token进行标注
- 输出识别出的实体
2、对序列标注进行类别编码
这里有两种可以使用的编码方式:
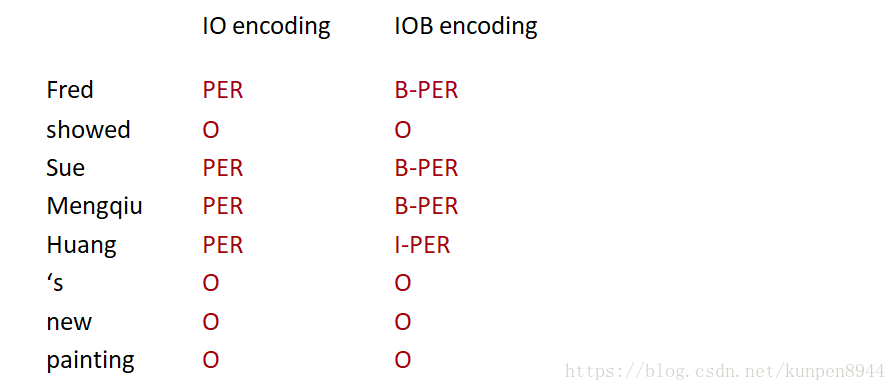
- IO编码,只标记每个词的类别。这里需要的标注个数是C+1。
- IOB编码,除了标记每个词的类别之外,标记还会表示出这个类别的开始和结束,如下图B-PER表示Person类别的开始,I-PER表示person类别的结束。这样的话,当几个相同的命名实体是连在一起的时候,我们可以区分出有几个命名实体。这里需要的标注个数是2C+1。
- 在实际应用中,IO编码效果可能会更好。(在Stanford的姓名粗识别中使用IO编码)
- 一方面是IO编码的速度更快,标注数量更少
- 另一方面,几个相同的命名实体是连在一起的情况很少,而且在这个情况下IOB编码也很难正确识别出命名实体的开始和结束。
3、序列标记的特征
- 单词
- 目前的单词
- 前一个/后一个单词(上下文)
- 其他推论型的语言分类
- 词类标记
- 上下文的标签(label)
- 前一个(或者后一个)词的标签
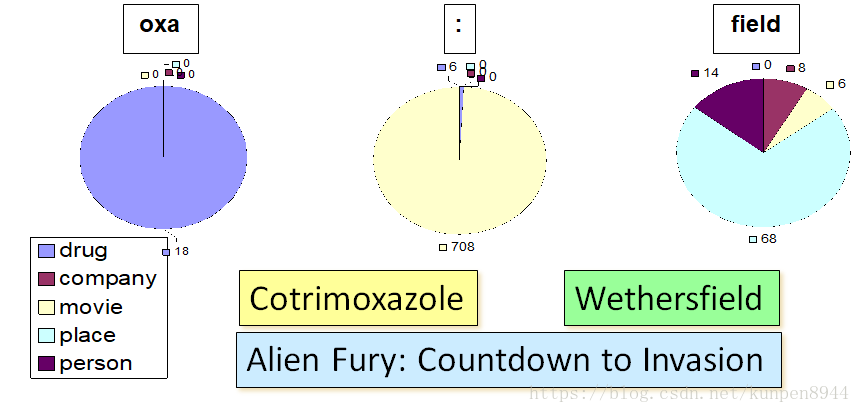
- 单词的子字符串:我们可以利用单词中的某些字符来进行判别,比如含有oxa子字符串的单词都是drug。
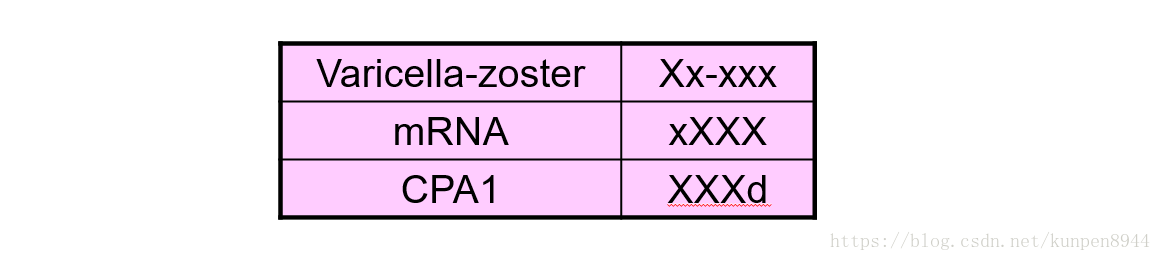
- 单词的形状:包括单词的长度、大小写、是否含有数字、是否含有希腊字母、连词符。利用下面的规则,我们将其抽取成特征。
- A,B,C…→X
- a,b,c→x
- 1,2,3…→d
- - → -
- . → .
- 对于长过四个字母的单词,我们取前两个和后两个;如果单词小于四个的话,我们就按照原来的长度转化。
- 例子如下:
四、最大熵马尔可夫模型(MEMMs)/条件马尔可夫模型
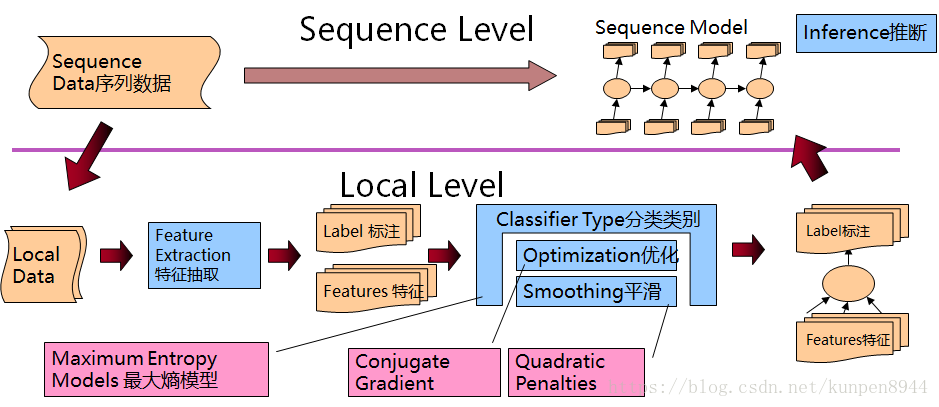
很多在NLP领域的问题的数据都是序列数据(单词序列,方块字序列,行序列,句子序列等等)。而我们的任务则是对每一项都进行标注。

1、最大熵马尔可夫模型(MEMMs)/条件马尔可夫模型
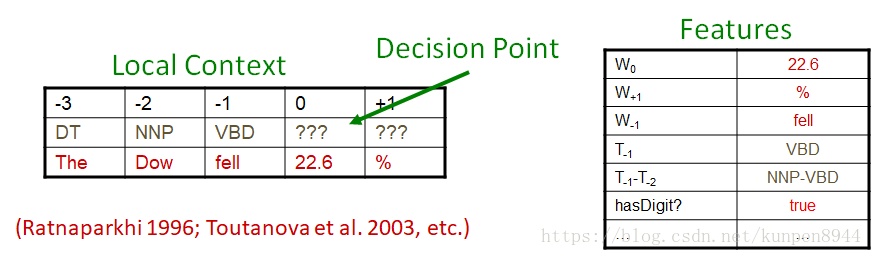
- 最大熵马尔可夫模型(MEMMs)/条件马尔可夫模型,这两个分类器都是每次做一个决定,基于目前的观测和过去的决定(decision)。
- 每一次进行分类,目的是对目前的单词进行标注,该分类器的计算和标准分类器是类似的。
- 所使用的特征包括单词(之前,目前,之后),标注(之前的单词),还有其他的单词特征(单词类型、后缀、-等等)
- 整体的推断系统如下
2、三种推断
- 贪婪推断(greedy inference)
- 从左边开始,用分类器依次给每个位置标记(label),分类器可以依靠之前的标记结果以及观测数据。
- 优点:
- 快,没有额外的空间存储要求
- 非常容易实施
- 当特征很多的时候效果很好
- 缺点
- 因为使用的是贪婪算法,所以可能会发生标记错误
- 束推断(beam inference)
- 这个方法不会简单标记每个单词,相反它会保留下一些可能,在每个位置都保持前k个序列(束),每次完成一个标记就滑动前进一个序列。
- 优点
- 快,3-5个单词的束就可以得到比较好的效果
- 很容易实施(不需要进行动态规划)
- 缺点
- 对有些标记而言,可能在表现出比较好的概率之前,就已经离开波束了
- 维特比推断(Viterbi Inference)
- 动态规划,需要关于状态影响的滑动窗口(比如,过去的两个状态是相关的)
- 优点:精确
- 缺点:对长距离的单词与单词之间的影响很难应用(束推断也不允许长距离的序列)。
3、条件随机场(CRFs)
这也是一个整个序列的条件模型,而不是链式的模型(local model)。模型形如下图,只不过c和d是序列。但是如果特征f是当前(local)的,条件序列似然可以用动态规划来计算。
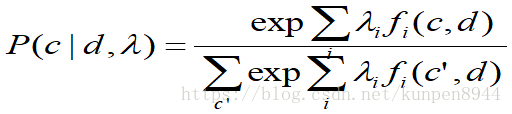
- 条件随机场的训练是很慢的,但是可以避免causal-competition偏误
- 有一些比较先进的方法都在被广泛的应用:比如a variant using a max margin criterion