一、介绍
- 信息检索(information retrieval)是从海量集合体(一般是存储在计算机中的文本)中找到满足信息需求(information need)的材料(一般是文档)
- 信息检索的应用领域:网页搜索,邮件搜索,电脑内部搜索,法律信息检索等等
- 信息检索的基本假设:
- 集合体(collection):一组假设为静态(static)的文档
- 目标:抽取和用户信息需求相关的文档,并帮助他们完成任务
- 一个经典的搜索模型
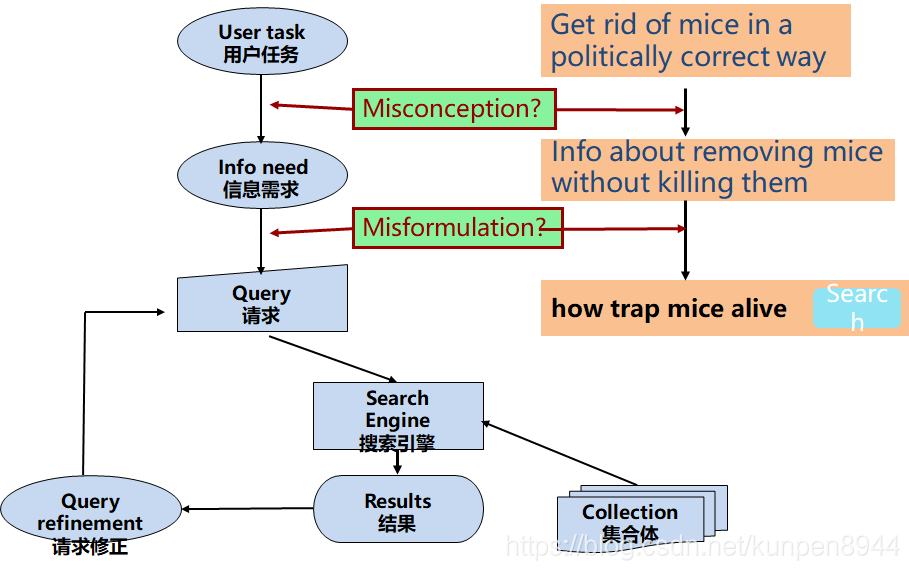
- 模型评估
- precision:检索的文档与用户的信息需求(注意这里不是请求)相关的比例
- recall:在集合体中相关的文档被检索到的比例
二、项-文档关联矩阵(Term-document incidence matrices)
- 假设我们现在面临一个任务:找到莎士比亚戏剧之中,含有Brutus和Caesar但是却没有Calpurnia的那部。
- 方法一:直接全文搜索含有Brutus和Caesar的戏剧,然后去掉没有Calpurnia的那一部
- 存在的问题
- 对于一个更大的语料集合体而言,这个计算的速度会很慢,特别是对于判断没有Calpurnia的任务而言(因为这个任务必须必须要扫描全文)
- 对于其他的操作而言,比如找countrymen边上的Romans,这种方法不够灵活
- 不能进行检索排名
- 存在的问题
- 方法二:构建一个项-文档关联矩阵:行表示单词,列表示文档;如果单词在这个文档中出现了,就标1;如果没有出现,就标0。
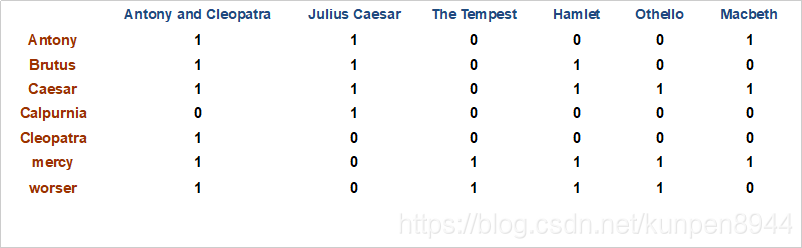 运算方法:位运算:Brutus行 AND Caesar行 AND (NOT Calpurnia)
运算方法:位运算:Brutus行 AND Caesar行 AND (NOT Calpurnia) - 上面两种方法对于集合体更大的情况是不适用的,因为这个时候矩阵的规模已经大到不能接受了。但是这个矩阵的一个特征是非常稀疏,因此我们可以只记录1的位置。
三、倒排索引(Inverted Index)
- 对文档进行索引,对于每个项(term)t,我们存储那些有这个项的文档的索引。
- 我们需要可变大小的倒排表(posting lists)
- 我们一般不会用固定大小的数组来存储,因为会面临溢出的问题
- 在内存中的话,倒排表一般会使用链表或者可变长度的数组
- 在硬盘中的话,就需要一个连续运作(continuous run)的倒排表
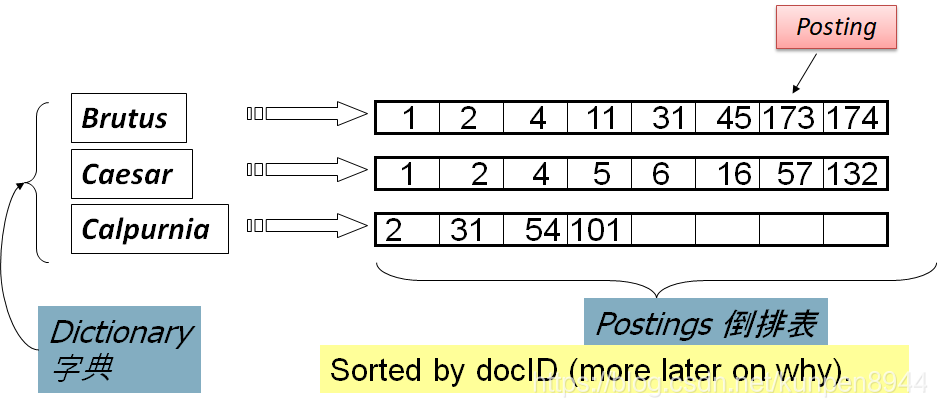
- 倒排索引的流程
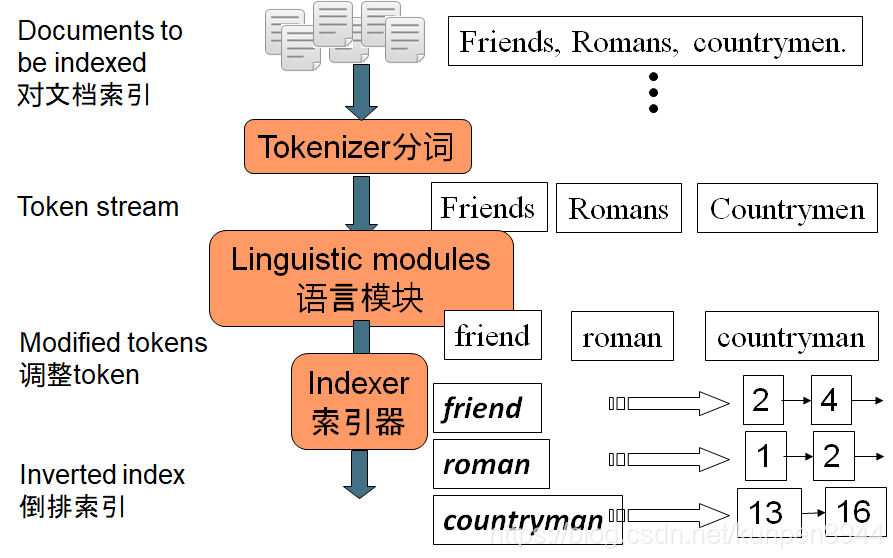
- 倒排索引前的预处理

- 索引流程
- 先把调整后的token展开成序列
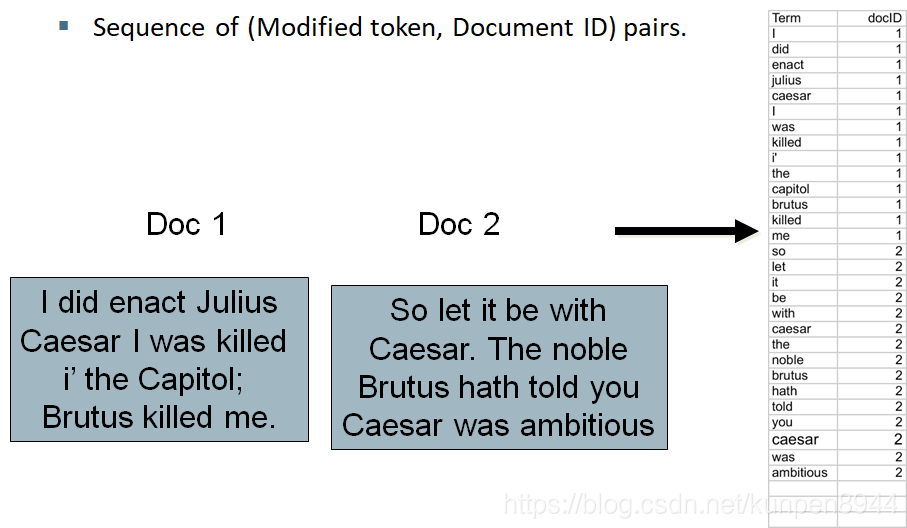
- 先根据token本身,然后根据文档ID进行排序
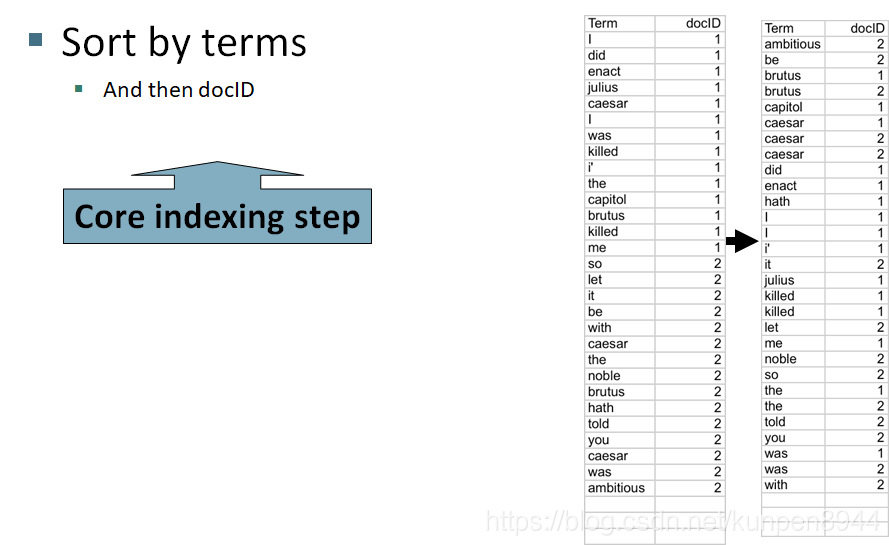
- 把同一个文档中相同的term进行合并,如caesar
- 拆分成字典和倒排表
- 加入文档频率信息
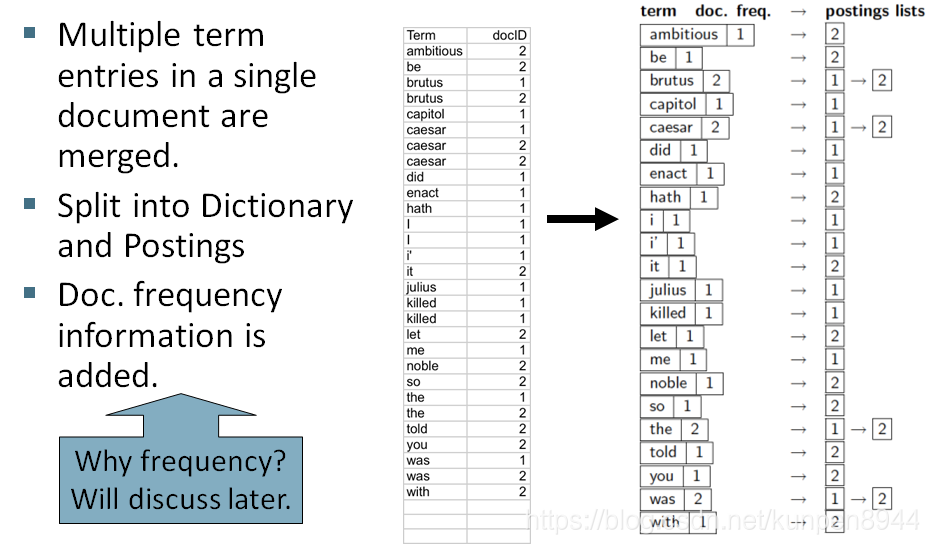
- 对于一个信息检索系统而言,它的存储是由这些组成的:项和对应的频率构成的字典,包含文档序号的链表以及链表和字典元素之间的指针。所以一个信息检索系统比较关注的两个问题是:我们怎么有效地进行检索?我们需要多少存储空间?
- 先把调整后的token展开成序列
四、在倒排表中如何处理请求
- 这里讲一下对AND的请求的处理
比如我们要找同时含有Brutus和Caesar的文档。我们的处理方法是在字典中找到Brutus和Caesar的位置,然后找到两者对应的链表,对这两个链表进行合并。

合并的主要想法是找两个指针从这两个链表的头节点开始向后进行循环,如果两者指针指向的空间的值相同则存储该索引,两个指针都前进一个指针;如果两个指针指向的空间的值不同,就让小的那个指针前进一步,然后进行比较;如此循环,知道一个指针指向了链表的尾巴为止。这种算法的时间复杂度是O(x+y),其中x和y分别表示两条链表的长度。
代码如下:

五、词组请求与位置索引
- 问题:如果我们想要处理一个词组的请求应该如何处理?
- 方法一:双单词索引
- 对文档中出现的连续单词都进行双单词索引,比如出现friends,Romans,Countryman,就有两个双单词:friends Romans以及Romans Countryman。接着对双单词构建倒排表和字典。这样的话,我们就可以解决双单词的词组的查找问题。如果是要查找三单词的话,只需要找到对应的两个双单词的倒排链表,然后在进行AND操作就可以了。
- 这种方法可能存在的问题是:1)对于两个以上的单词词组可能会搜索到含有对应的双单词,但是实际上这些双单词并不相连的问题。2)双单词会导致字典的规模很大
- 因此,一般双单词索引不是这种问题的标准解决方法,但是可以作为一种补充手段。
- 方法二:位置索引(positional index)
- 具体方法是在构建倒排表的时候不仅仅记录项(term)出现的文档序号,也记录在对应文档中的位置。

- 具体算法:上一节的算法的拓展,在比对到文档的序号相同的时候,再进行一次类似的算法,判断两个指针指向的单词位置是否是相邻的。当然基于这个算法我们也可以进一步拓展到临近请求(proximity queries),比如索引A在B的三个单词距离内的文档。
- 空间复杂度:这种方法会大大增加存储所需的空间,但是由于其对临近请求与词组请求的有效性,所以我们一般标准处理方法还是位置索引。索引的规模适合文档的平均规模有关系的,平均网页的项(term)个数小于1000,如果是书籍的话很容易就超过100000项(term)。假设每个项(term)出现频率是0.1%,那么对于有100000项(term)的文档而言,位置索引就会导致倒排表比原来增加100倍。这里有一个比较粗略的估算规则:在和英语比较类似的语言中,网页的位置索引要比非位置索引大2-4倍,和原文档的规模比起来大概是35%-50%。
- 具体方法是在构建倒排表的时候不仅仅记录项(term)出现的文档序号,也记录在对应文档中的位置。
- 把上面两种方法结合起来构成的信息搜索模型会更有效。对于一些特定的经常搜索的词,比如“michael jackson”,采用位置索引的效率是很低的,我们可以直接采用双单词索引。其他的则使用位置索引。比如根据Williams et al(2004)的论文,他采用了这样的算法,可以使得算法时间是原来纯位置索引的1/4,但是空间需求只增加了26%。