Support Vector Machines 支持向量机
Large Margin Classification大间距分类器
Optimization Objective优化目标
到目前为止 你已经见过一系列不同的学习算法 在监督学习中 许多学习算法的性能 都非常类似 因此 重要的不是 你该选择使用 学习算法A还是学习算法B 而更重要的是 应用这些算法时 所创建的 大量数据 在应用这些算法时 表现情况通常依赖于你的水平 比如 你为学习算法 所设计的 特征量的选择 以及如何选择正则化参数 诸如此类的事 还有一个 更加强大的算法 广泛的应用于 工业界和学术界 它被称为支持向量机(Support Vector Machine) 简称SVM
在逻辑回归中 如果有一个 y=1 的样本 我们希望 h(x) 趋近1 这就意味着 当 h(x) 趋近于1时 θ 转置乘以 x 应当 远大于0 此时逻辑回归的输出将趋近于1
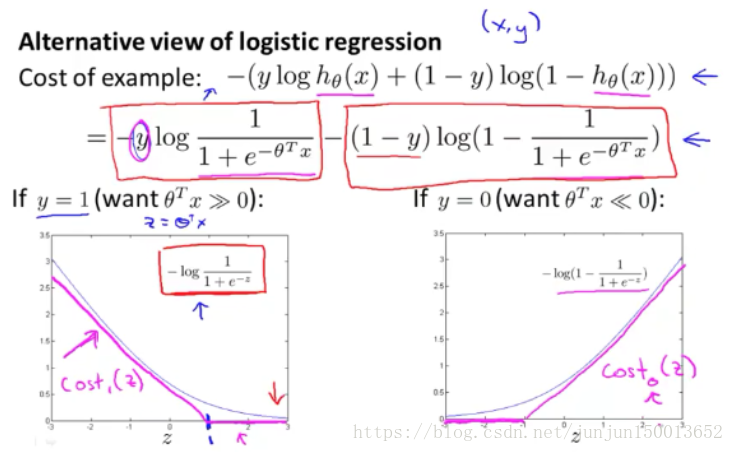
逻辑回归的代价函数中 每个样本 (x, y) 都会为总代价函数 增加这里的一项
现在 开始建立支持向量机 将原曲线用紫红色曲线替代 我们将使用的新的代价函数 左边的函数 为 cost1(z) 右边为 cost0(z) 这里的下标是指 在代价函数中 对应的 y=1 和 y=0 的情况
拥有了这些定义后 现在 我们就开始构建支持向量机 这是我们在逻辑回归中使用 代价函数 J(θ)

对于逻辑回归 在目标函数中 我们不是 优化这里的 A+λ×B 我们所做的 是通过设置 不同正则参数 λ 达到优化目的 这样 我们就能够权衡 对应的项 是使得训练样本拟合的更好 即最小化 A 还是保证正则参数足够小 也即是 对于B项而言
但对于支持向量机 我们 依照惯例使用 一个不同的参数 称为C(类似于1/λ的作用) 同时改为优化目标 C×A+B 因此 在逻辑回归中 如果给定 λ 一个非常大的值 意味着给予B更大的权重 而这里 就对应于将C 设定为非常小的值 那么 相应的将会给 B 比给 A 更大的权重 因此 这只是 一种不同的方式来控制这种权衡 或者一种不同的方法 即用参数来决定 是更关心第一项的优化 还是更关心第二项的优化
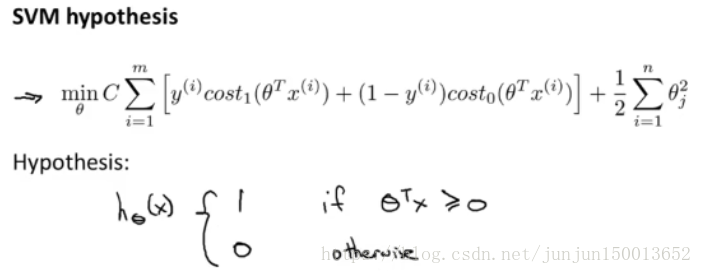
这个目标函数 得到 SVM 学习到的 参数C 最后 有别于逻辑回归 输出的概率 当最小化代价函数 获得参数θ时 支持向量机所做的是 它来直接预测 y的值等于1 还是等于0 (逻辑回归需要自己手动判断θ^T*x > 0.5时,预测为1...) 因此 这个假设函数 会预测1 当 θ^T*x 大于 或者等于0时 或者等于0时 所以学习 参数 θ 就是支持向量机假设函数的形式 那么 这就是 支持向量机 数学上的定义

Large Margin Intuition大间距分类器
人们有时将支持向量机 看做是大间距分类器 这一部分 将介绍其中的含义 这有助于我们 直观理解 SVM模型的 假设是什么样的 这是我的支持向量机模型的代价函数

如果你有一个正样本 y等于1 则其实我们仅仅要求 θ 转置乘以 x 大于等于0 就能将该样本恰当分出 这是因为如果 θ 转置乘以 x 比0大的话 我们的模型代价函数值为0 类似地 如果你有一个负样本 则仅需要 θ 转置乘以x 小于等于0 就会将负例正确分离 但是 支持向量机的要求更高 不仅仅要能正确分开输入的样本 即不仅仅 要求 θ 转置乘以 x 大于0 我们需要的是 比0值大很多 比如 大于等于1 我也想这个比0小很多 比如我希望它 小于等于-1 这就相当于在支持向量机中嵌入了 一个额外的安全因子 或者说安全的间距因子 当然 逻辑回归 做了类似的事情 但是让我们看一下 在支持向量机中 这个因子会 导致什么结果
具体而言 我接下来 会考虑一个特例 我们将这个常数 C 设置成 一个非常大的值 比如我们假设 C的值为100000 或者其它非常大的数 然后来观察支持向量机会给出什么结果

如果 C 非常大 则最小化代价函数的时候 我们将会很希望 找到一个 使第一项为0的 最优解 因此 输入一个训练样本 标签为 y=1 你想令第一项为0 你需要做的是 找到一个 θ 使得 θ 转置乘以 x 大于等于1 类似地 对于一个训练样本 标签为 y=0 为了使 cost0(z) 值为0 我们需要 θ 转置 乘以x 的值 小于等于-1 因为我们将 选择参数使第一项为0 我们的优化问题变成如图右下角所示这样 求解这个优化问题的时候 当你最小化这个关于变量 θ 的函数的时候 你会得到一个非常有趣的决策边界

具体而言 如果你考察 这样一个线性可分的数据集 红色和绿色的角色边界很明显不是好的选择,支持向量机将会选择 这个黑色的决策边界 看起来 这是更稳健更好的决策界 它有更大的距离 这个距离叫做间距 (margin) 而这是支持向量机 具有鲁棒性的原因 因为它努力 用一个最大间距来分离样本 因此支持向量机 有时被称为 大间距分类器 而这其实是 求解上一页幻灯片上优化问题的结果
记得这个例子的前提时正则化因子 常数C 设置的非常大 事实上 支持向量机现在 要比这个大间距分类器所体现的 更成熟
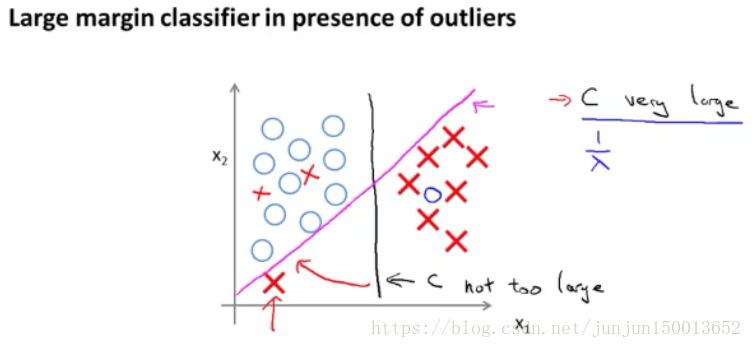
如图这样一个样本集 左下角有个异常值 当正则化参数 C 设置的非常大的时候,支持向量机最终会得到那条粉色的线 仅仅基于 一个异常值 就将 我的决策界 从这条黑线变到这条粉线 这实在是不明智的
但是如果 C 设置的小一点 则你最终会得到 这条黑线 也就是说C取值合适时,支持向量机是可以忽略掉一些异常点的影响 得到更好的决策界 因此 大间距分类器的描述 真的 仅仅是从直观上给出了 正则化参数 C 非常大的情形
Mathematics Behind Large Margin Classification大间隔分类背后的数学原理
首先 复习一下 关于向量内积的知识 u 转置乘以 v 的结果 向量 u 和 v 之间的内积

u.*v = ||u||*||v||*cosθ = p*||u|| (其中p = ||v||*cosθ,也就是v在u上的投影,它是有正负的,由夹脚θ决定)
这就是关于向量内积的知识 我们接下来将会 使用这些关于向量内积的 性质 试图来 理解支持向量机 中的目标函数 这就是我们先前给出的 支持向量机模型中的目标函数(当C非常大的时候) 为了讲解方便 忽略掉截距 令 θ0 等于 0 特征数 n 置为2


现在 我们来看一下目标函数 支持向量机的优化目标函数 当我们仅有两个特征 即 n=2 时 这个式子可以写作 二分之一 θ1 平方加上 θ2 平方 我们只有两个参数 θ1 和θ2 目标函数可以简化成右图所示,抉择边界和θ向量是垂直的(因为抉择边界θ1*x1+θ2*x2=0的斜率-θ1/θ2,向量θ=(θ1,θ2)的斜率是θ2/θ1)
先看右图左边的决策边界,我们分析支持向量机为什么不会选它而选择右边的这个有最大间隔的决策边界
jun:因为支持向量机 做的全部事情就是 极小化参数向量 θ 范数的平方,在p*||θ||>=1 if y=1且p*||θ||<=-1 if y=0时,先考虑y=1的情况 使得θ 范数最小,即||θ||最小,而p*||θ||>=1,则p要尽可能的大才行,p 是 x 在 θ上的投影,那么就是要这个投影越大越好,前面说过θ和决策边界是垂直的,那么x 在 θ上的投影也就是x到决策边界的垂直距离,最后问题就简化到要x到决策边界的垂直距离越大越好了 也就是支持向量机会选择最大间隔的那个决策边界 y=0的情况同上分析
Kernels核函数
Kernels I核函数
我们对支持向量机算法做一些改变 以构造复杂的非线性分类器 我们用"kernels(核函数)"来达到此目的

我们来看看核函数是什么 以及如何使用 如果你有一个训练集 像这个样子 然后你希望拟合一个 非线性的判别边界 来区别正负样本 一种办法 是构造 多项式特征变量 如果θ0加上θ1*x1 加上其他的多项式特征变量 之和大于0 那么就预测为1 反之 则预测为0
这种方法 的另一种写法 θ0+θ1×f1+ θ2×f2+θ3×f3 那么 f1就等于x1 f2就等于x2 f3等于这个 x1x2 f4等于x1的平方 f5等于x2的平方 等等 我们之前看到 通过加入这些 高阶项 我们可以得到更多特征变量
问题是 如何构造这些高阶项来最好的拟合我们的数据

这里有一个可以构造 新特征f1 f2 f3的想法 手动选取一些点 分别定义为第一个标记l(1) 第二个标记l(2) 第三个标记l(3) 将第n个特征变量fn 定义为 一种相似度的度量 度量样本 x 与 第n个标记的相似度 度量相似度的公式如上图 这个相似度函数就是 核函数 这里用的是高斯核函数 假设x与其中一个标记点l(n)非常接近 fn就越接近于1 相反地 fn就接近于0
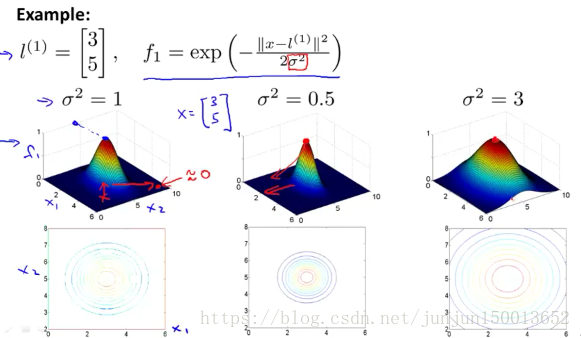
σ平方是高斯核函数的参数 当你改变它的值的时 你会得到略微不同的结果 σ平方越小 突起的宽度越窄 等值线图也收缩了一些 特征变量的值减小的速度 会变得比较快
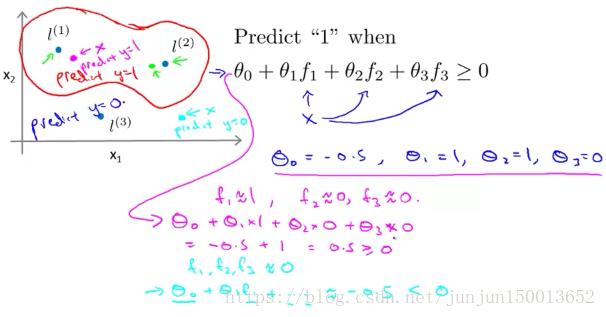
假设我们已经找到了一个学习算法 并且假设 我已经得到了 这些参数的值 因此如果θ0等于-0.5 θ1等于1 θ2等于1 θ3等于0 如图所示 假设我们有一个训练样本x 接近于l(1) 那么f1 就接近于1 又因为训练样本x 离l(2) l(3) 都很远 所以 f2就接近于0 f3也接近于0 另一个不同的点 x 如果进行和之前相同的计算 你发现f1 f2 f3都接近于0 因此 通过计算 我们预测的y值是0 然后对大量的点 进行这样相应的处理 我们最后会得到 这个预测函数的 判别边界 这个红色的判别边界里面 预测的y值等于1 在这外面预测的y值 等于0
这就是核函数这部分 的概念 以及我们如何 在支持向量机中使用它们 我们通过标记点和相似性函数 来定义新的特征变量 从而训练复杂的非线性分类器
Kernels II核函数
上一节遗留问题 我们如何得到这些标记点?
我们直接 将训练样本 作为标记点 整个过程的大纲如下


两个细节是 n=m 特征个数 等于样本数 优化函数的第二项 θj从1到m的平方和 可以被重写为 θ的转置 乘以θ 记得先忽略θ0
大多数支持向量机 在实现的时候 其实是替换掉 θ 的转置乘以 θ 用 θ 的转置乘以 某个矩阵 这依赖于你采用的核函数 再乘以 θ 这其实是另一种略有区别的距离度量方法 我们用一种略有变化的 度量来取代 不直接用 θ 的模的平方进行最小化 而是最小化了另一种类似的度量 这是参数向量θ的变尺度形式 这种变化和核函数相关 这个数学细节 使得支持向量机 能够更有效率的运行
支持向量机做这种修改的 理由是 这么做可以适应 超大的训练集 例如 当你的训练集有10000个样本时
顺便说一下 你可能会想为什么我们不将 核函数这个想法 应用到其他算法 比如逻辑回归上 事实证明 如果愿意的话 确实可以将核函数 这个想法用于定义特征向量 将标记点之类的技术用于逻辑回归算法 但是用于支持向量机 的计算技巧 不能较好的推广到其他算法诸如逻辑回归上 所以 将核函数用于 逻辑回归时 会变得非常的慢 相比之下 这些计算技巧 比如具体化技术 对这些细节的修改 以及支持向量软件的实现细节 使得支持向量机 可以和核函数相得益彰 而逻辑回归和核函数 则运行得十分缓慢 更何况它们还不能 使用那些高级优化技巧 因为这些技巧 是人们专门为 使用核函数的支持向量机开发的
在使用支持向量机时的 偏差-方差折中 在使用支持向量机时 其中一个要选择的事情是 目标函数中的 参数C 大的C对应着 逻辑回归 问题中的小的λ 这意味着不使用正则化 如果你这么做 就有可能得到一个低偏差但高方差更倾向于过拟合 的模型 如果你使用了 较小的C 这对应着 在逻辑回归问题中 使用较大的 λ 对应着一个高偏差 但是低方差更倾向于欠拟合的模型 另外一个要选择的参数是 高斯核函数中的σ^2 当高斯核函数中的 σ^2偏大时 那么高斯核函数 倾向于变得相对平滑 这会给你的模型 带来较高的偏差和较低的方差 反之 如果σ^2很小 高斯核函数 即相似度函数会变化的很剧烈 最终得到的模型会 是低偏差和高方差
SVMs in Practice练习SVMs
Using An SVM使用SVM
对于应用支持向量机 我们需要做的首先是 要选择参数C 其次 选择核函数
其中一个选择是 我们选择不用任何核函数 不用核函数这个作法 也叫线性核函数 这种用法的 SVM 只使用了 θ 转置乘以x 当 θ0 + θ1x1 + ... + θnxn 大于等于0时 预测 y=1 对线性核函数这个术语 你可以把它理解为 这个版本的 SVM 它只是给你一个标准的线性分类器 (什么时候不用核函数?)因此对某些问题来说 它是一个合理的选择 而且你知道 有许多软件库 比如 liblinear 就是众多软件库 中的一个例子 它们可以用来训练的 SVM 是没有核函数的 那么你为什么想要做这样一件事儿呢? 如果你有大量的特征变量 如果 n 很大 而训练集的样本数 m 很小 那么 你知道 你有大量的特征变量 x 是一个 n+1 维向量 x 是一个 n+1 维向量 那么如果你已经有 大量的特征值 和很小的训练数据集 也许你应该拟合 一个线性的判定边界 不要拟合非常复杂的非线性函数 因为没有足够的数据 如果你想在一个高维特征空间 试着拟合非常复杂的函数 而你的训练集又很小的话 你可能会过度拟合 因此 这应该是 你可能决定不适用核函数 或者等价地说使用线性核函数 的一个合理情况
当你选择高斯核函数为核函数时 你要做的另外一个选择是 选择一个参数σ的平方
那么什么时候选择高斯核函数呢? 如果你原来的特征变量 x 是 n 维的 如果 n 很小 并且 理想情况下 如果 m 很大
那么如果我们有 一个二维的训练集 就像我前面讲到的例子一样 那么n等于2 但是我们有相当大的训练集 我已经画出了 大量的训练样本 那么可能你需要用 一个核函数去拟合一个 更复杂的非线性判定边界 那么高斯核函数会是不错的选择
如果你用 Octave 或者 Matlab 来实现 支持向量机的话 它会要求你提供一个函数 来计算核函数的特定特征 它将自动地生成所有特征变量 它自动地 用你写的这个函数 将 x 映射到对应的 f1 f2 一直到 fm 生成所有的特征值 并从这儿开始训练支持向量机 但是有些时候你却一定要 自己提供这个函数 如果你使用高斯核函数 一些SVM的实现也会包括高斯核函数 和一些其他的核函数 因为高斯核函数可能是最常见的核函数
如果你有大小很不一样 的特征变量 在使用高斯核函数之前 对它们进行归一化是很重要的
现在如果你的特征变量 取值范围很不一样 就拿房价预测来举例 如果你的数据 是一些关于房子的数据 如果 x1 的取值 在上千平方英尺 的范围内 但是 x2 是卧室的数量 且如果它在 一到五个卧室范围内
那么 x1-l1 将会很大 这有可能上千数值的平方 然而 x2-l2 将会变得很小 在这样的情况下的话 那么在这个式子中 这些间距将几乎 都是由 房子的大小来决定的 从而忽略了卧室的数量 为了避免这种情况 让向量机得以很好地工作 确实需要对特征变量进行归一化 这将会保证SVM 能够同等地关注到 所有不同的特征变量 而不是像例子中那样 只关注到房子的大小 而忽略了其他的特征变量
不是所有你可能提出来 的相似度函数 都是有效的核函数 高斯核函数 线性核函数 以及其他人有时会用到的 另外的核函数 它们全部需要满足一个技术条件 它叫作默塞尔定理 (Mercer's Theorem) 需要满足这个条件的原因是 因为支持向量机算法 或者 SVM 的实现 有许多巧妙的 数值优化技巧 为了有效地求解 参数 θ 在最初的设想里 有一个这样的决定 将我们的注意力仅仅限制在 可以满足默塞尔定理的核函数上 这个定理所做的是 确保所有的SVM包 所有的SVM软件包 能够使用 大量的优化方法 并且快速地得到参数 θ
一些其他的核函数:多项式核函数 字符串核函数 卡方核函数 直方图交叉核函数 等等

讨论最后两个细节 一个是在多类分类中 你有4个类别 或者更一般地说是 K 个类别 怎样让 SVM 输出各个类别间合适的判定边界? 大部分 SVM 许多 SVM 包已经内置了 多类分类的函数了 因此如果你用的是那种软件包 你可以直接用内置函数 你可以直接用内置函数 应该可以工作得很好 不然的话 另一个方式是 一对多 (one-vs.-all) 方法 这个我们在 讲解逻辑回归的时候讨论过 所以你要做的是 要训练 K 个 SVM 如果你有 K 个类别的话 每一个 SVM 把一个类同其他类区分开 这会给你 K 个参数向量 它们是 θ(1) 它把 y=1 这类 θ(1) 它把 y=1 这类 和所有其他类别区分开 和所有其他类别区分开 然后得到第二个参数向量 θ(2) 然后得到第二个参数向量 θ(2) 它是在 y=2 为正类 它是在 y=2 为正类 其他类为负类时得到的 以此类推 一直到参数向量θ(K) 是用于 区分最后一个类别 类别 K 和其他类别的参数向量 那么我们什么时候用哪一个呢?
如果 特征变量的数量 n 相对于你的训练集大小来说较大时 通常会使用逻辑回归 或者使用 没有核函数的 SVM 或者叫线性核函数
如果 n 较小 而 m 是中等大小 我的意思是 n 可以取 1 - 1000之间的任何数 如果训练样本的数量 可能是从 10 也许是到10,000个样本之间的任何一个值 也许多达5万个样本 那么通常高斯核函数的SVM会工作得很好
第三种值得关注的情况是 如果 n 很小 但是 m 很大 那么高斯核函数的支持向量机 运行起来就会很慢 如今的 SVM 包 如果使用高斯核函数的话 会很慢 如果你有5万 那还可以 但是如果你有 一百万个训练样本 或者是十万个 m 的值很大 如今的 SVM 包很好 但是如果你对一个 很大很大的训练集 使用高斯核函数的话 它们还是会有些慢 在这种情况下 我经常会做的是 尝试手动地创建 更多的特征变量 然后使用逻辑回归 或者不带核函数的 SVM
你看这张幻灯片 你看到了逻辑回归 或者不带核函数的 SVM 在这个两个地方都出现了 我把它们放在一起 是有原因的 逻辑回归和不带核函数的 SVM 它们都是非常 相似的算法 它们会做相似的事情 并且表现也相似 但是根据你实现的具体情况 其中一个可能会比另一个更加有效 但是如果其中一个算法适用的话 那么另一个算法 也很有可能工作得很好 但是 SVM 的威力 随着你用不同的核函数学习 复杂的非线性函数 而发挥出来
最后 神经网络应该在什么时候使用呢? 对于所有的这些问题 对于所有这些区间 一个设计得很好的神经网络也很可能会非常有效
它的一个缺点是 或者说有时可能不会使用 神经网络的原因是 对于许多这样的问题 神经网络训练起来可能会很慢 但是如果你有一个非常好的 SVM实现包 它会运行得比较快 比神经网络快很多 尽管我们在此之前没有证明过 实际上 SVM 的优化问题 是一种凸优化问题 因此好的 SVM 优化软件包 总是会找到 全局最小值 或者接近它的值
在实际应用中 局部最优 对神经网络来说不是非常大 但是也不小 根据你的问题 神经网络可能会比 SVM 慢
算法确实很重要 但是通常更重要的是 你有多少数据 你有多熟练 是否擅长做误差分析 和调试学习算法 想出如何设计新的特征变量 以及找出应该输入给学习算法的其它特征变量等方面 通常这些方面会比 你使用逻辑回归 还是 SVM 这方面更加重要 但是 已经说过了 SVM 仍然被广泛认为是 最强大的学习算法之一 而且 SVM 在一个区间内 是一个非常有效地学习复杂非线性函数的方法 因此 我实际上 逻辑回归 神经网络 SVM 加在一起 有了这三个学习算法 我想你已经具备了 在广泛的应用里 构建最前沿的 机器学习系统的能力 它是你的武器库中的另一个非常强大的工具 它被广泛地应用在很多地方
参考资料