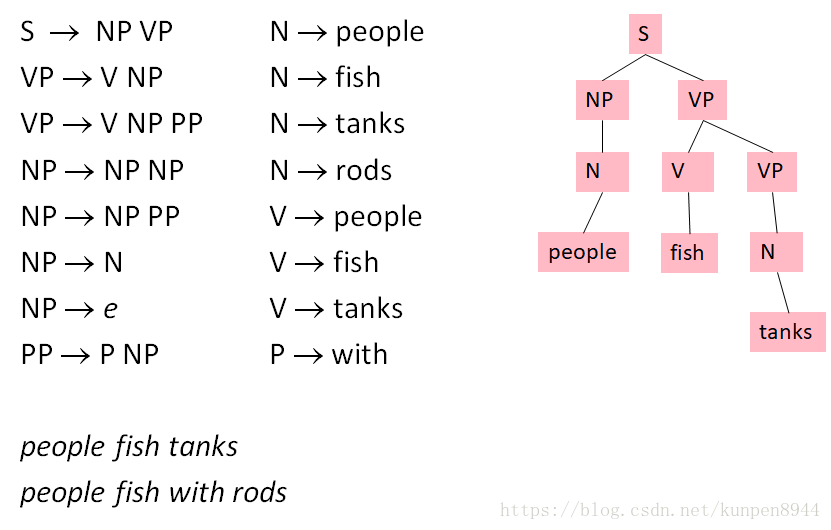
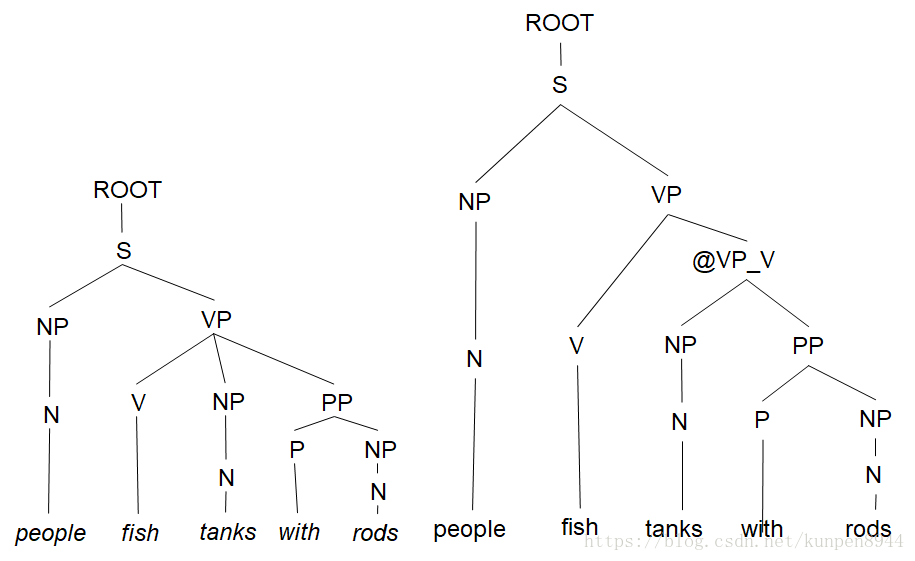
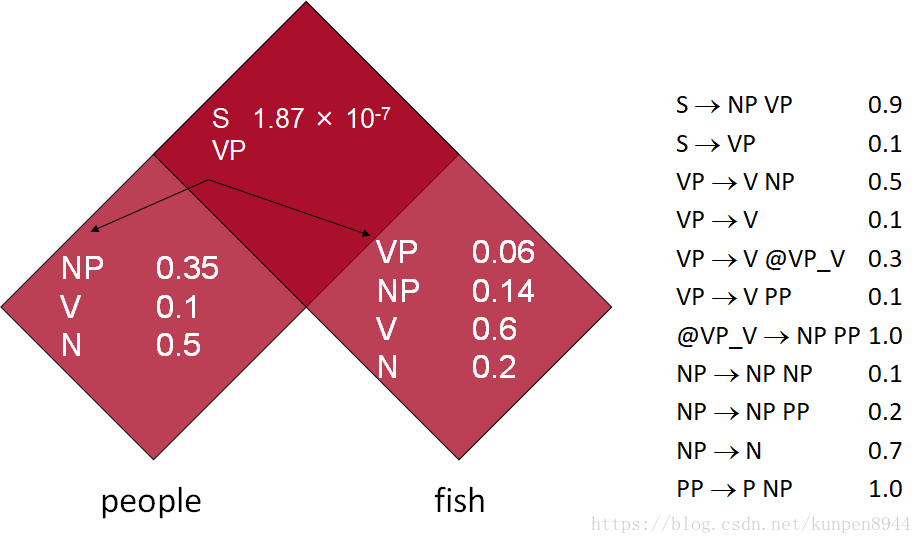
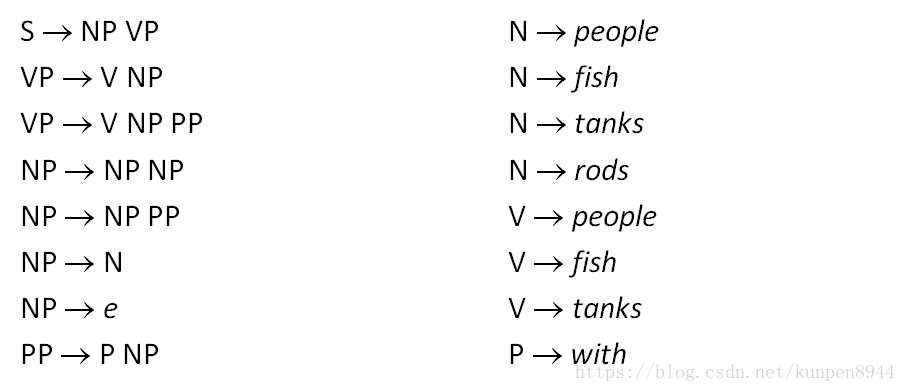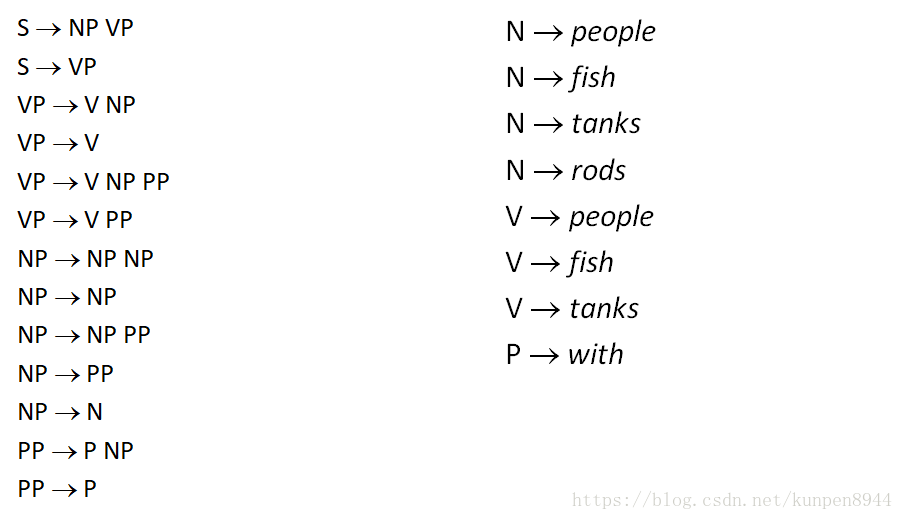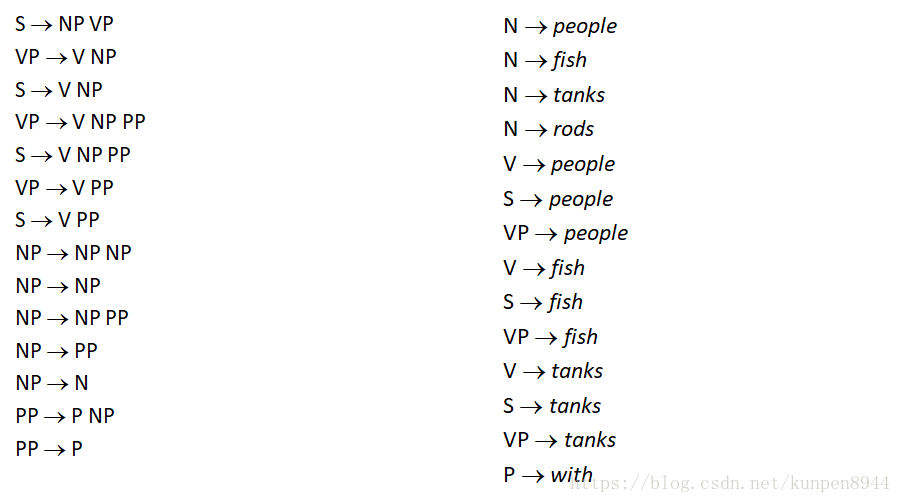第三步:一对N的规则拆成一对二的规则,比如VP→V NP PP拆成两个规则VP → V @VP_V,@VP_V →NP PP
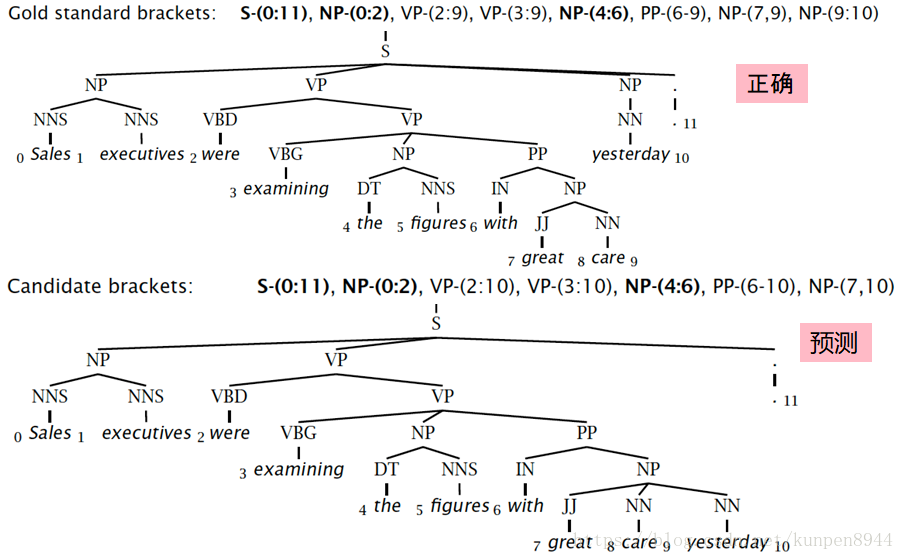
在实践中,完整的Chomsky Normal Form转换是很痛苦的,一对N的规则拆分是很容易的,但是空(e)和一对一规则的消除非常麻烦。对于上下文无关文法(CFG)句法分析而言,一对N的规则拆分可以帮助建立二叉树,可以有效降低复杂度。而其他操作不是必要的,充其量就是会使得算法更干净更快而已。下图右边就是一对N的规则拆分的句法分析树。 下图有颜色的部分表示了同一个短语的不同的四个句法结构树,第一个是初始,第二个是去掉了空,第三个是去掉了一对一保留了最高的父节点,第四个是去掉了一对一保留了最低的父节点(三四比起来我们更倾向于四,因为可以保留完整的字典)
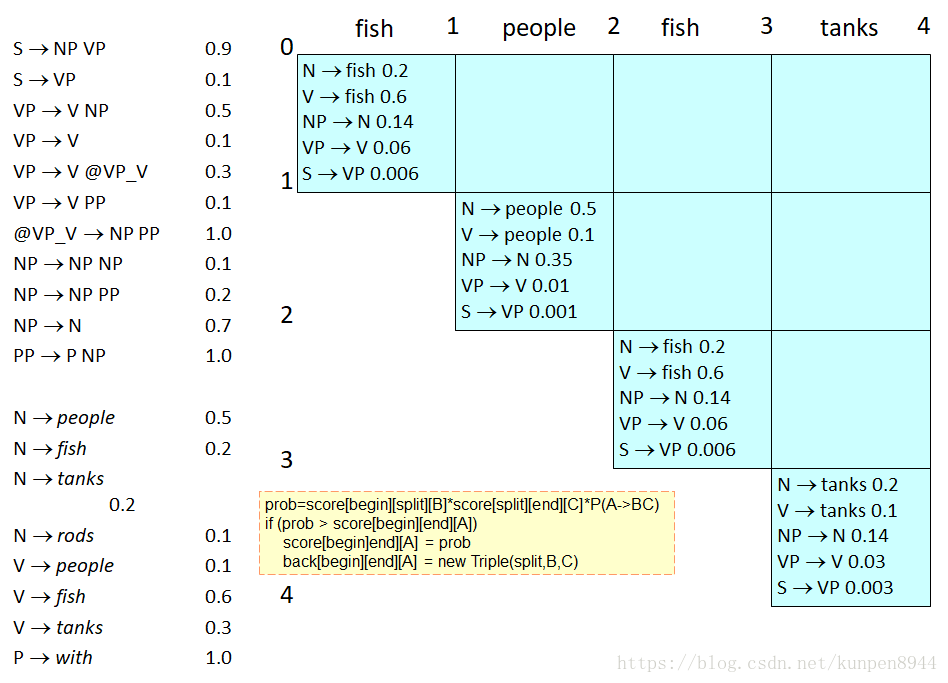
function CKY(words, grammar) returns [most_probable_parse,prob]
score = new double[#(words)+1][#(words)+1][#(nonterms)] //存储格子中所有可能成分和对应的概率
back = new Pair[#(words)+1][#(words)+1][#nonterms]] //指针,指出最佳的成分
****接下来主要处理字典lexicon*****
for i=0; i<#(words); i++ 对每个单词
for A in nonterms 对每个非终端
if A -> words[i] in grammar 如果A指向对应的单词的话,就在score中存储
score[i][i+1][A] = P(A -> words[i])
//handle unaries 下面部分处理一对一规则
boolean added = true
while added
added = false
for A, B in nonterms
if score[i][i+1][B] > 0 && A->B in grammar 一对一规则搜寻
prob = P(A->B)*score[i][i+1][B]
if prob > score[i][i+1][A] 判断一对一的概率是否会比原来的大,如果是的话就覆盖原来的概率
score[i][i+1][A] = prob
back[i][i+1][A] = B
added = true
****接下来主要处理语法规则*****
for span = 2 to #(words)
for begin = 0 to #(words)- span
end = begin + span
for split = begin+1 to end-1 对一串语句而言,选择二分的节点
for A,B,C in nonterms
prob=score[begin][split][B]*score[split][end][C]*P(A->BC) 计算对应的概率
if prob > score[begin][end][A] 如果概率大于原来的概率就覆盖,修改back指针
score[begin]end][A] = prob
back[begin][end][A] = new Triple(split,B,C)
//handle unaries 下面部分处理一对一规则
boolean added = true
while added
added = false
for A, B in nonterms
prob = P(A->B)*score[begin][end][B];
if prob > score[begin][end][A] 判断一对一的概率是否会比原来的大,如果是的话就覆盖原来的概率
score[begin][end][A] = prob
back[begin][end][A] = B
added = true
return buildTree(score, back)