一、情感分析简述
情感分析(sentiment analysis),又叫意见抽取(opinion extraction),意见挖掘(opinion mining),情感挖掘(sentiment mining)以及主观分析(subjectivity analysis)。
- 情感分析的应用领域非常广泛
- 情感分析是对态度的研究,具体可以分解为:
- 按照复杂程度,可以把情感分类分为三类
- 简单任务:判断文本的任务是消极的还是积极的
- 更复杂:把对文本的态度按1-5打分
- 进阶:研究来源(source)、对象(target)以及复杂的态度类型


二、一个基本算法
1、一个情感分类任务
- 判断IMDB的电影评论是积极的还是消极的
- 数据:Polarity Data 2.0 http://www.cs.cornell.edu/people/pabo/movie-review-data
- 基本步骤
- 分词(tokenizaiton)
- 特征抽取
- 利用分类模型分类(朴素贝叶斯,SVM,MaxEnt)
2、情感分词(tokenizaiton)问题
- 处理HTML和XML的标记
- Twitter的标记(名字,tags)
- 大写(保留全部大写的单词)
- 电话和日期
- 表情(下面是一些正则表达)
- 一些有用的代码
http://sentiment.christopherpotts.net/code-data/happyfuntokenizing.py

3、特征抽取
- 否定的抽取: I didn‘ t like this movie vs I really like this movie
- 解决方案:在否定词和接下来的标点之间的每个词都加上NOT_,形如下面
- 解决方案:在否定词和接下来的标点之间的每个词都加上NOT_,形如下面
- 抽取哪些单词?
- 只使用形容词
- 还是使用全部单词?
- 全部的单词表现更好,至少在这个数据集上是这样

4、分类:二值化(binarized (Boolean feature))多元朴素贝叶斯
- 基本思想:主要针对情感(或者可能是其他文本分类领域)。单词是否出现比单词出现的频率更为重要,所以这个算法的特别之处在于对出现的单词都记为1。
- 具体算法和朴素贝叶斯一致,唯一的变动是在计算P(w|c)的时候,先删除每篇文档里的重复的单词,只保留一个。
- 这种算法会比原来的朴素贝叶斯效果更好(这个算法和Mutivariate Bernoulli Naive Bayes是不一样的,后者在文本问题上效果不好)
- 也可以使用其他的改进:log(freq(w))(单词的count取对数以后就会小很多)

5、交叉检验(cross-validation)
- 把数据集分成十份fold(每一份中类别比例相同)
- 对每一份(fold),选择这一份作为临时的测试集,在另外九份上训练模型,并在测试集上计算模型效果。
- 给出十份效果的平均数
6、评论难以分类的原因


三、情感词典(sentiment Lexicons)
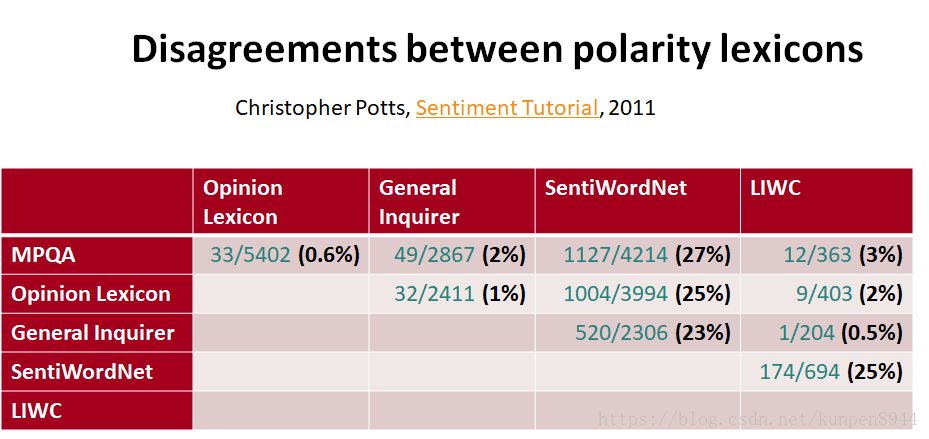
1、一些可用的情感词典





- 根据相关的研究,我们发现除了sentiword,其他情感词典的相似度都很高。
2、 分析IMDB中每个词的极性(polarity)
比较单词和电影打分之间的相关性,考虑到可比性,计算的公式如下:
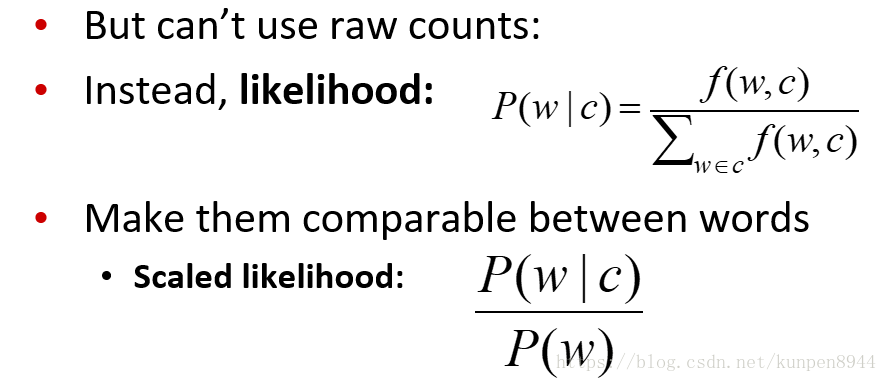
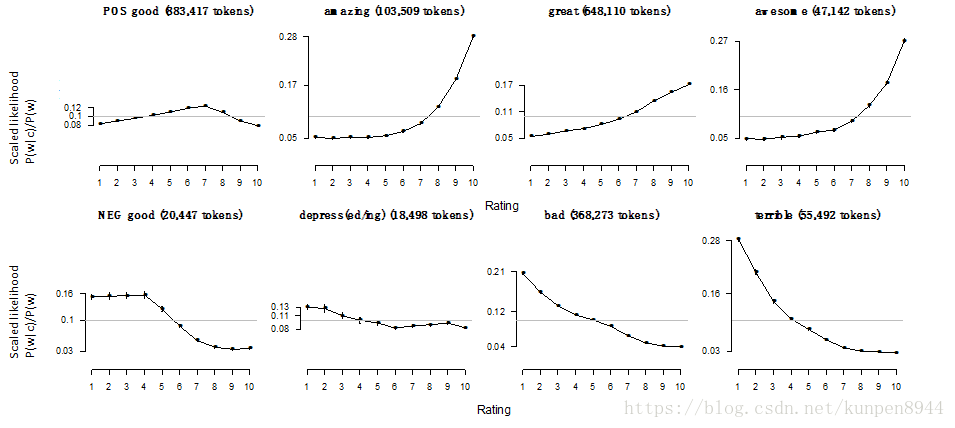
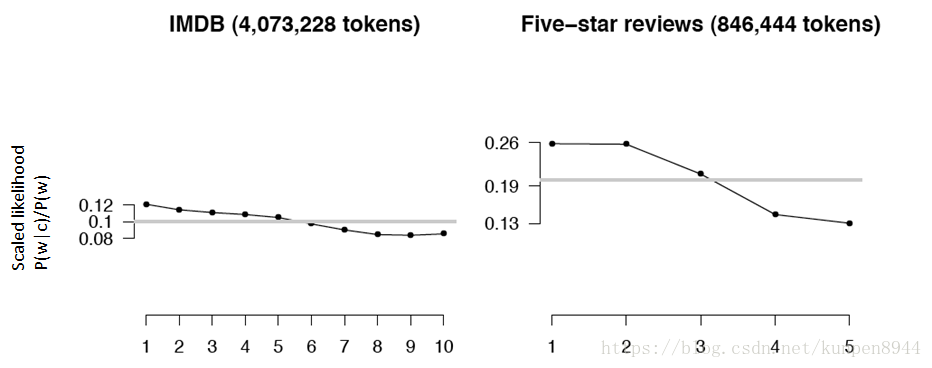
3、逻辑否定词
根据pott的研究,更多的否定词会出现在消极情绪中
四、情感词典训练
1、利用半监督学习词典
使用少量的信息,包括一些标注的样本和一些人工建立的模式(pattern),通过bootstrap的方法来训练词典。
2、Hatzivassiloglou和Mckeown的算法(用于单词词典的构造)
- 关键思想:用and相连的两个词,极性相同;用but相连的两个词,则反之。
- 第一步:标记种子集(seed set)
- 1336个形容词,657个正向词,679个负向词
- 第二步:利用关键思想拓展种子集
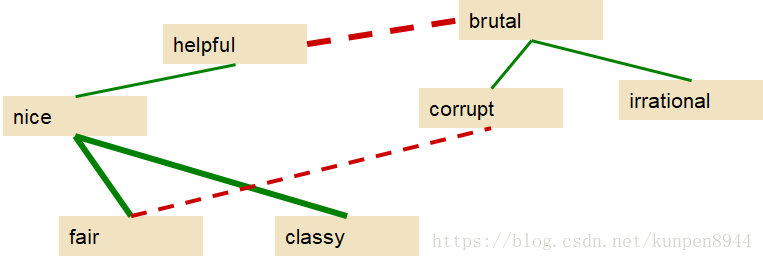
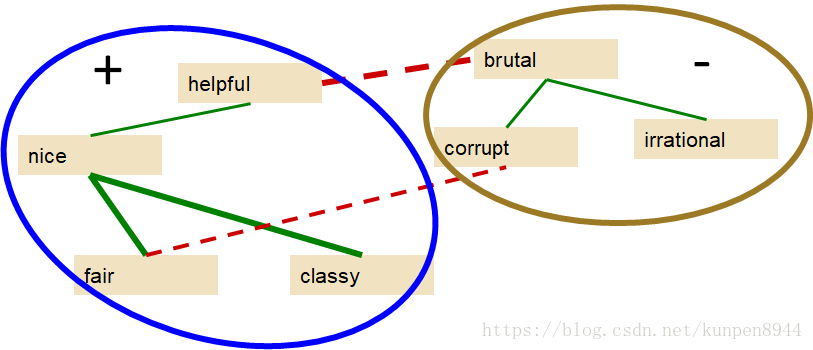
- 第三步:利用监督分类算法计算单词对的极性相似程度(polarity similarity),结果如下图。
- 第四步:利用聚类方法把图分为两个部分
- 最终的结果:确实会出现不准确的情况
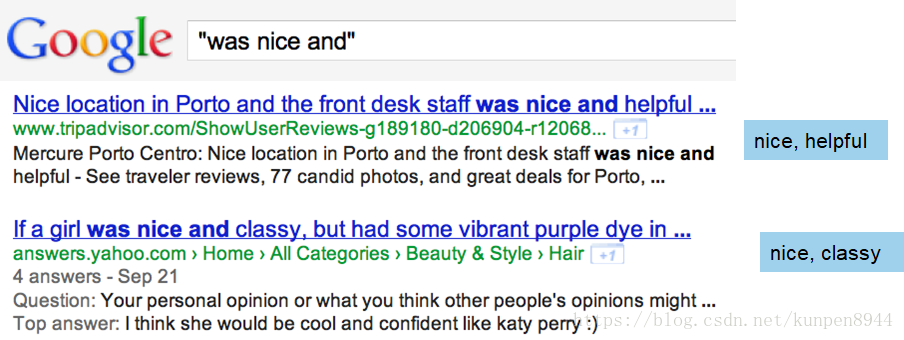

3、Turney算法(用于词组词典的构造)
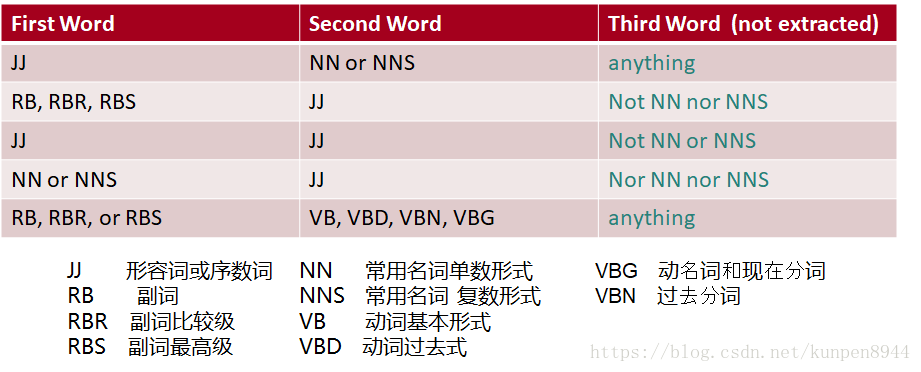
- 第一步:根据下面的规则,抽取两字词组
- 第二步:学习每个词组的词性
- 基本思想:积极词组会和“excellent”更多的一起出现;消极词组会和“poor”更多的一起出现
- 度量一起出现的指标:PMI(pointwise mutual information),表示x和y同时出现的概率,比上他们如果独立的时候同时出现的概率。
- 两个单词之间的PMI可以写成如下的形式:
- 具体到概率的计算如下:P(word)是word出现的次数/总单词数,P(word1,word2)是word1和word2同时出现的次数/总单词数的平方
- 极性的度量=和excellent的PMI-和poor的PMI
- 两个单词之间的PMI可以写成如下的形式:
- 例子
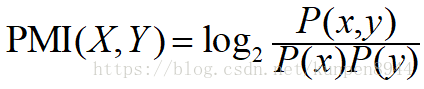
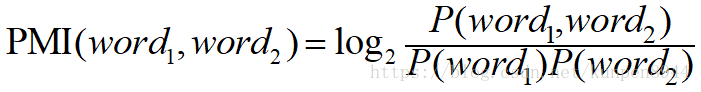


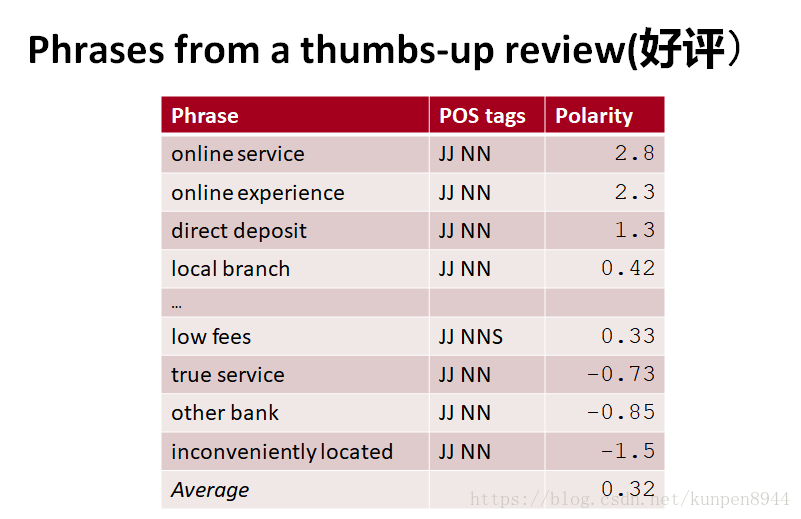
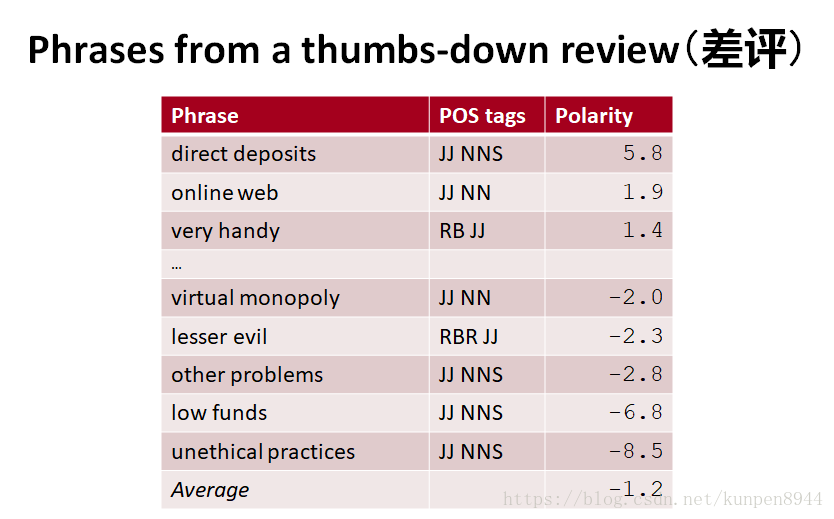
4、使用wordnet学习极性
- wordnet:线上分类词典(thesaurus)
- 种子词:积极(good),消极(terrible)
- 找同义词和反义词
- 积极方面:加入积极的同义词(well)和消极的反义词
- 消极方面:加入消极的同义词(awful)和积极的反义词(evil)
5、训练词典的总结
- 优点
- 有领域针对性(demain-specific)
- 可以有更多单词,因此更稳健
- 主要解决思想
- 开始找一系列种子词(good,bad)
- 找到其他有相同词性的词(利用and/but,利用在同一篇文档中附近出现的单词,利用wordnet的同义词和反义词)
五、其他情感任务
1、研究情感的方面(aspect)、对象(target)以及态度(attribute)
- 如何选取方面(aspect)?
- 有些可以事先确定,比如我们要研究酒店的话,方面就是食物、交通、设备等等
- 有些则利用出现的频率和规则确定
- 找到在评论中经常出现的词组(fish tacos)
- 利用一些规则进行筛选,比如在情感词后面出现的词,比如great fish tacos可以提取fish tacos
- 接下来,进行有监督学习
- 对一小部分的语料进行关于方面(aspect)的人工标注
- 训练一个分类器,将其他没标注的句子分到对应的方面(aspect)中
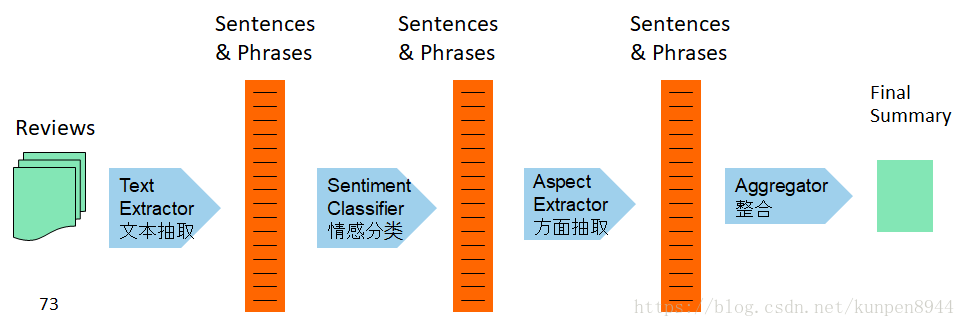
- 步骤图示
- 训练结果

2、不均衡类别问题
- 基本模型假设类别的频率是均衡的,但是在现实生活中的大部分问题,类别都是不均衡的(类别发生的概率是不一样的)
- 非均衡问题的评价标准:用准确率不适合来进行评价,应该使用F值
- 严重的非均衡问题甚至会降低分类表现
- 两个常见的解决方案
- 训练样本重抽样:随机欠拟合
- 代价损失函数:svm,当对较少的类错误分类的时候会进行惩罚
3、七星问题的处理
- 转化为二分类问题
- 用线性或者有序回归,或者是特定的模型,比如metric labeling
4、关于情绪(sentiment)的总结
- 通常会构建分类或者是回归模型
- 特征构建上的一些要点
- 否定(negation)是很重要的
- 使用所有的单词(朴素贝叶斯)做特征,在某些任务中表现很好
- 在其他任务中,使用单词的子集会更好
- 手工建立的极性词典
- 种子和半监督方法生成词典
5、除了态度以外,还可以进行其他类型的分析



,