Unsupervised Learning非监督学习
Clustering聚类
K-Means Algorithm K均值算法
在聚类问题中 我们有未加标签的数据 我们希望有一个算法 能够自动的 把这些数据分成 有紧密关系的子集或是簇 K均值 (K-means) 算法是现在最为广泛使用的聚类方法
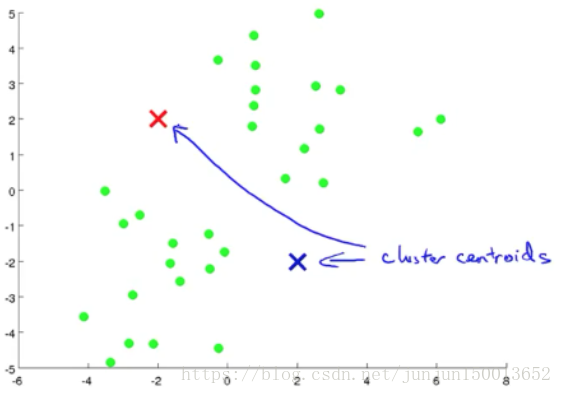
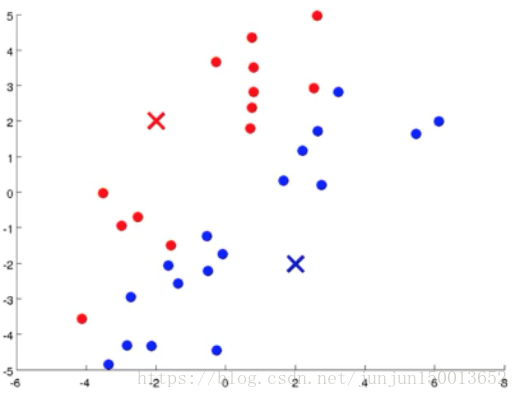
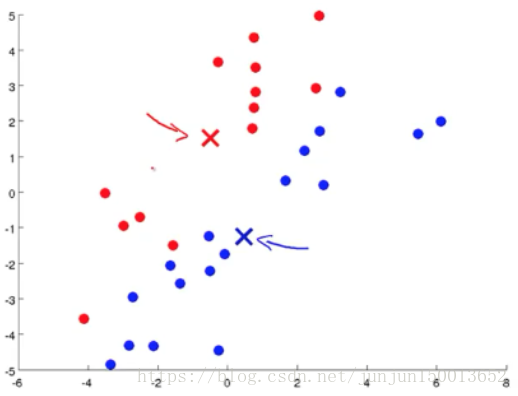
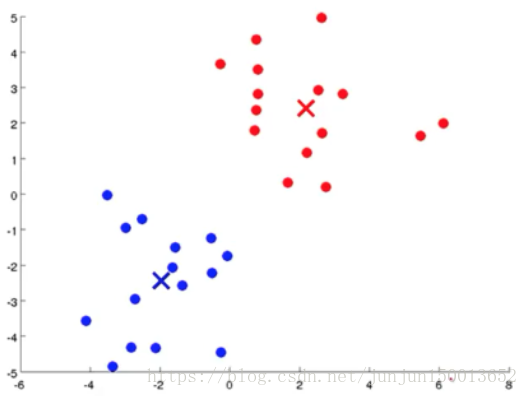
如图所示 现在我有一些没加标签的数据 而我想将这些数据分成两个簇 现在我执行K均值算法 方法是这样的 首先我随机选择两个点 这两个点叫做聚类中心 (cluster centroids) 就是图上边的两个叉这两个就是聚类中心 为什么要两个点呢 因为我希望聚出两个类 K均值是一个迭代方法 它要做两件事情 第一个是簇分配 第二个是移动聚类中心
图一:随机选择两个点,这两个点就是聚类中心(红叉和蓝叉)
图二:遍历所有的样本 然后依据每一个样本是更接近红叉还是蓝叉 来将每个样本点分配到两个不同的聚类中心中
图三:移动聚类中心 到 和它一样颜色的那堆点的均值处
图四:重复迭代图一到图三,直到聚类中心的位置不再变化 表示K均值方法已经收敛了
K均值算法接受两个输入 第一个是参数K 表示你想从数据中 聚类出的簇的个数 另一个是只有 x 的 没有标签 y 的训练集
在非监督学习的 K均值算法里 我们约定 x(i) 是一个n维向量 这就是 训练样本是 n 维而不是 n+1 维

K均值算法

第一步 随机初始化 K 个聚类中心 记作 μ1, μ2 一直到 μk
第二步 K均值的内部循环
首先 对于每个训练样本 我们用变量 c(i) 表示 K个聚类中心中最接近 x(i) 的 那个中心的下标 这就是簇分配 所以 c(i) 是一个 在1到 K 之间的数 小写的 k 则是 不同的中心的下标
其次 计算分配给每个聚类中心的那些点的均值(如果聚类中心没有分配到任何样本点,就将它移除,则K减小)将K个聚类中心μk分别移动到分配给它的那些点的均值处
第三步 迭代第二步直到收敛
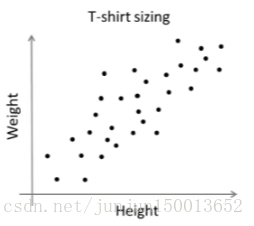
事实是 K均值经常会用于 一些这样的数据 看起来并没有 很好的分来的 几个簇 这是一个应用的例子 关于T恤的大小
Optimization Objective优化目标
事实上 K均值也有 一个优化目标函数或者 需要最小化的代价函数
首先 了解什么是 K均值的优化目标函数 这将能帮助我们 调试学习算法 确保K均值算法 是在正确运行中 第二个也是最重要的一个目的是 我们该怎样运用这个来 帮助K均值找到更好的簇 并且避免局部最优解
当K均值正在运行时 我们将对两组变量进行跟踪 c(i) 和 μk
以下便是 K均值算法需要 最小化的代价函数 J 参数是 c(1) 到 c(m) 以及 μ1 到 μk 随着算法的执行过程 这些参数将不断变化

K均值算法 要做的事情就是 找到能够最小化 代价函数 J 的 c 和 μ 这个代价函数 在K均值算法中 有时候也叫做 失真代价函数(distortion cost function)

第一步要做的 其实不是改变 聚类中心的位置 而是选择 c(1) c(2) 一直到 c(m) 来最小化这个代价函数 J
第二步 聚类中心的的移动 这一步 是选择了能够 最小化 J 的 μ 的值
因此 K均值算法 实际上是把这两组变量 在这两部分中 分割开来考虑 分别最小化 J 首先是 c 作为变量 然后是 μ 作为变量 那么 K均值的工作就是 首先关于 c 求 J 的最小值 然后关于 μ 求 J 的最小值 然后反复循环 这就是 K均值算法
Random Initialization随机初始化
如何初始化 K均值聚类方法
如何避开局部最优来构建K均值聚类方法
效果最好的一种方法是 随机挑选K个训练 样本 然后 设定μ1 到μk让它们等于这个K个样本
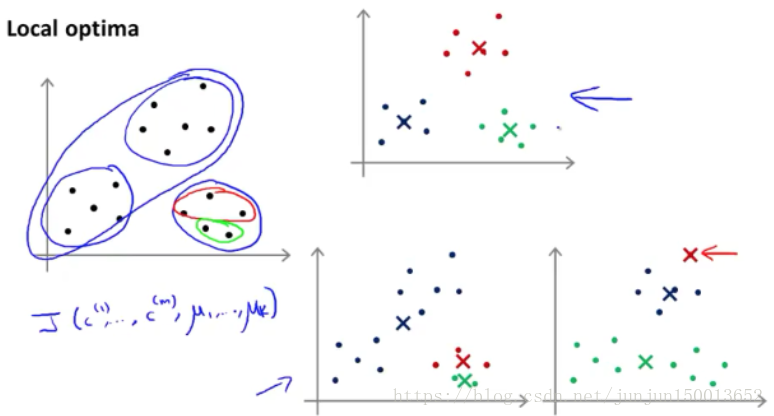
通过上图 发现 μk选择不同时 最终可能会得到 不同的结果 还有可能落在局部最优解
对于上面的问题我们能做的 是尝试多次 随机的初始化 而不是仅仅初始化一次K均值方法 就希望它会得到 很好的结果
假如我决定运行 K均值方法一百次 这是一个相当典型的次数数字 有时会是 从50到1000之间 在所有这100种 用于聚类的方法中 选取能够给我们代价最小的一个 给我们最低畸变值的一个
事实证明 如果你运行K均值方法时 所用的聚类数相当小 从 2到10之间的任何数的话 做多次的随机初始化 通常能够保证 你能有一个较好的局部最优解 保证你能找到更好的聚类数据 但是如果K非常大的话 如果 K比10大很多 比如成百上千个聚类 那么 多种随机初始化就 不太可能会有太大的影响 但是 尽管你有很多聚类数目 随机初始化还是会给K均值方法一个 合理的起始点来开始 并找到一个好的聚类结果
Choosing the Number of Clusters选择聚类的个数
关于选择聚类数目其实并没有非常标准的解答 最常用的方法 仍然是通过看可视化的图 或者看聚类算法的输出结果 或者其他一些东西来手动地决定聚类的数目
对于同一个数据集,每个人看到的聚类数目会不一样,而且并没有标准的答案
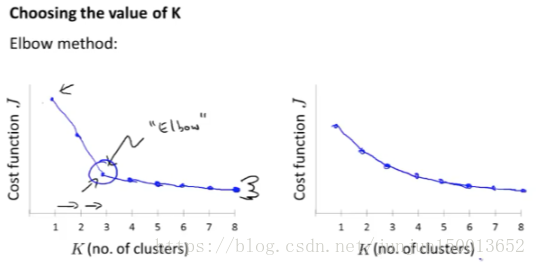
一个叫做 肘部法则 (Elbow Method) 的方法 我们所需要做的是改变K的值 也就是聚类类别的总数 然后计算代价函数 J 并将其画在出来,计算不同的K值时的代价函数J时我们可以用多个随机的初始聚类中心计算
这里看起来是一个很清楚的肘点 你会发现这样一种模式 K从1变化到2 再从2到3时 畸变值迅速下降 然后在3的时候 到达一个肘点 此后畸变值就下降得非常慢 这样看起来 也许使用3个类 是聚类数目的正确选择 那么我们就选K等于3
事实上肘部法则 并不那么常用 其中一个原因是 如果你把这种方法 用到一个聚类问题上 你最后得到的曲线 类似于右边这样 没有一个清晰的肘点 而畸变值像是连续下降的 因此你还是没法很好的选择K值 但是肘部法则 还是一个值得尝试的方法 但是不要抱太多的期待
最后 决定聚类数量的 更好的办法是 看不同的聚类数量能为 后续下游的目的提供多好的结果 比如选择T恤尺寸,是K=3(大中小号)还是K=5(加小,小,中,大,特大号),就看你是出于什么目的,比如想满足更多用户的需求,还是盈利更多,还是...
总结:大部分时候 聚类数目仍然是通过 手动 人工输入或我们的洞察力来决定 一种可以尝试的方法是 使用肘部法则 使用肘部法则 但是我不会总是 期望它能表现得好 我想选择聚类数目的更好方法是 去问一下你运行K-均值聚类 是为了什么目的?
Motivation
Motivation I: Data Compression
第二种无监督学习问题 它叫维数约减 (dimensionality reduction)
使用维数约简 的原因有以下几个
数据压缩 占用更少的计算机 内存和硬盘空间 还能给算法提速
什么是维数约减
举一个例子 假如我们有一个有很多很多很多 特征变量的数据集 我在这里只画了其中两个 假设我们不知道 这两个特征量 一个某个物体的长度 以厘米为单位 另一个 x2 是它以英寸为单位的长度 所以这是一个 非常冗余的数据 我们应该把 这个数据降到一维 这些样本 没有完美地在一条直线上 就是因为取整 所造成的误差
如果你有上百 或者上千的特征变量 很容易就会忘记 你到底有什么特征变量 而且有时候可能有 几个不同的工程师团队 一队工程师可能给你 200个特征变量 第二队工程师可能再给你 300个特征变量 然后第三队工程师给你 五百个特征变量 所以你一共有1000个特征变量 这样就很难搞清 哪个队给了你 什么特征变量 实际上得到这样冗余的特征变量并不难

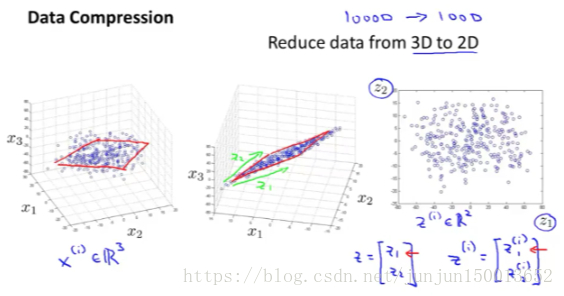
左图展示了一个 把数据从 2D 降到 1D 的例子 右图是把数据从三维 3D 降到二维 2D 的例子
我们通过把所有原始的样本 映射到这条绿线上 来近似原始的数据集 那么我就 只需要一个数字 来确定这条线上 一个点的位置 这样一来 在把所有训练样本 映射到这条绿线上之后 我就能只用一个数字来表示 每个训练样本的位置
在更典型的维数约减例子中 我们可能有1000维 的数据 想降低到100维 但是因为能画的图是有限制的 所以用 3D 到 2D 来讲述
Jun:如果数据能从3D 降到 2D,那么从某一个角度去看,所有的点都会在一个平面上,而这个平面就是我们要得的2D平面
Motivation II: Visualization
通过数据降维来可视化数据
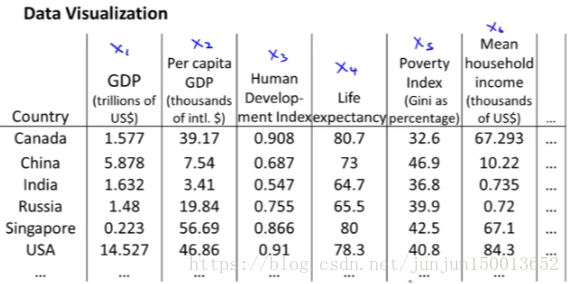
假如我们已经收集了大量的 统计数据集 有关全世界不同国家的 或许第一个特征x1 国内生产总值 x2是一个百分比 每人占有GDP x3 人类发展指数 x4 预期寿命 x5 x6 等其它特征 我们也许会有大量的数据集 像这里这样的数据 对于每个国家可能有50个特征 我们有这样的众多国家的数据集
那么有没有办法 使得我们能更好地来理解数据 这里我给出了一张有数字的表格 你怎样将这些数据可视化 如果有50个特征 绘制一幅50维度的图 是异常困难的 那有没有观察数据的好办法呢 ?
使用降维的方法 那么应该怎么做呢 ?我们可以提出一种不同的 特征表示方法 使用一个二维的向量z来代替x 从某种程度来说 这两个数总结了50个数
也许 我们可以 使用这两个数来绘制出这些国家的二维图 使用这样的方法尝试去 理解二维空间下 不同国家在不同特征的差异 更容易 所以 这里你能做的是 将数据降维 从50维度 的数据 降维到2维度 这样你就可以绘制出 2D的图像了
当你这么做时 你会发现如果 你仔细观察降维算法的输出结果 它通常不能赋予 你想要的这些二维新特征一个物理含义 你应该能想来 这经常取决于我们计算出的特征含义
Principal Component Analysis
Principal Component Analysis Problem Formulation
对于降维问题来说 目前 最流行 最常用的算法是 主成分分析法 (Principal Componet Analysis, PCA)
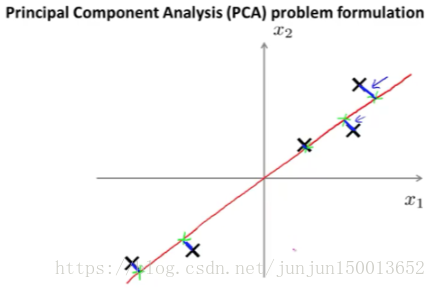
假设 我们有这样的一个数据集 这个数据集含有 二维实数空间内的样本X 假设我想 对数据进行降维 从二维降到一维 也就是说 我想找到 一条直线 将数据投影到这条直线上 那怎么找到一条好的直线来投影这些数据呢?
PCA 所做的就是 寻找一个低维的面 数据投射在上面 使得 这些蓝色小线段的平方和 达到最小值 这些蓝色线段的长度 时常被叫做 投影误差 在应用PCA之前 通常的做法是 先进行均值归一化和 特征规范化
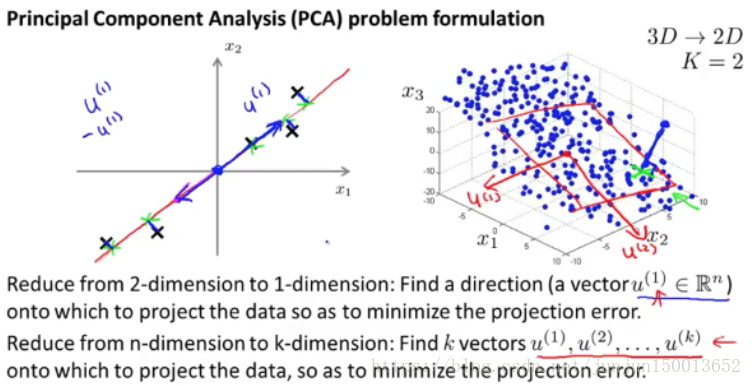
PCA 的目标是 如果我们将数据从二维 降到一维的话 我们将试着寻找 一个属于n维空间中的向量u(i) 在这个例子我们将寻找一个对数据进行投影的方向 使得投影误差能够最小 我将它叫做 u(1) 无论它是正的 还是负的都没关系 (Jun:因为之前进行了归一化,那么这个向量是经过远点的,它主要是代表一个方向)
更一般的情况是 我们有 n 维的数据 想降到 k 维 在这种情况下 我们不仅仅只寻找单个的向量 来对数据进行投影 我们要找到 k 个方向 来对数据进行投影 从而最小化投影误差
右图显示了三维的情况 那么我们要找的就是一个用两个向量u(1)和u(2) 确定的平面
Principal Component Analysis Algorithm
要点:主成成分分析(PCA)的算法 实现过程 应用 PCA 来给数据降维
均值归一:首先计算出 每个特征的均值 μ 然后我们用 x - μ 来替换掉 x 这样就使得 所有特征的均值为0
特征缩放:把每个特征 进行缩放 使其处于同一可比的范围内 用 x(i)j 减去平均值 μj 除以 sj 来替换掉第 j 个特征 x(i)j 这里的 sj 表示特征 j 的某个量度范围 因此它可以表示最大值减最小值 或者更普遍地 它可以表示特征 j 的标准差
进行完以上这些数据预处理后 接下来就正式进入 PCA 的算法部分
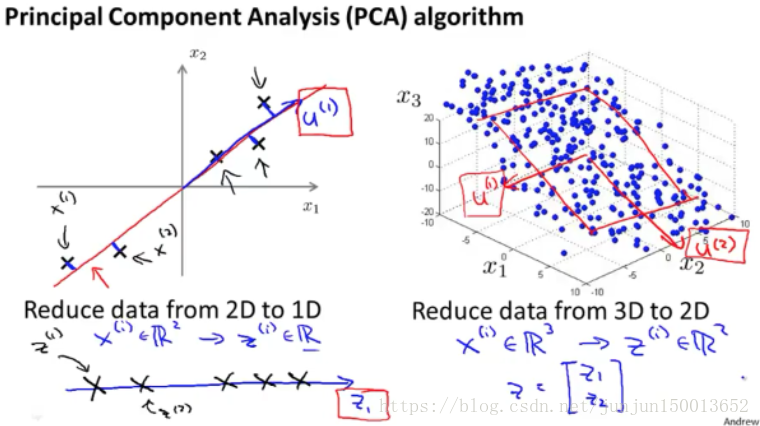
对于左边这个例子 我们的数据是 二维实数 x(i) 我们想要做的 是找到一系列 一维实数 z(i) 来表示我们的数据 也就是把数据投影到这条红线上 我们只需要一个数 来指明点在线上的位置 我把这个数称为 z 或者 z1
因此 PCA 要做的事儿 就是要得到一种方法 来计算两个东西 其一是计算这些向量 比如左图的 u(1) 右图的 u(1) u(2) 其二是 怎样计算出这些 z
所需要进行的步骤 假如说 我们想要 把数据从 n 维 降低到 k 维

我们首先要做的 是计算出 这个协方差矩阵 通常是用 希腊字母大写的西格玛 ∑ 来表示
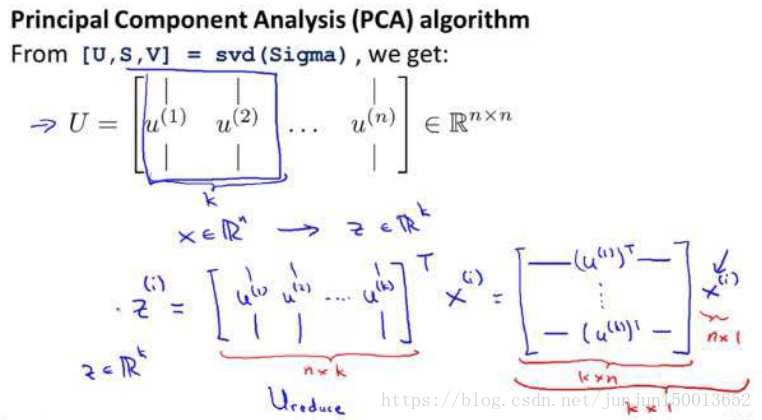
计算出这个协方差矩阵后 假如我们 把它存为 Octave 中的 一个变量 叫 Sigma 我们需要做的 是计算出 Sigma 矩阵的特征向量 (eigenvectors) 在 Octave 中 你可以使用如下命令 来实现这一功能 [U,S,V] = svd(Sigma); svd 表示奇异值分解 (singular value decomposition) 如果你的数据 是一个大 X 矩阵 那么 Sigma = (1/m) * X' * X
实际上 Sigma 是一个 协方差矩阵 有很多种方法 来计算它的特征向量 Octave 中 svd 命令 和 eig 命令 将得到相同的结果 虽然说 svd 要更稳定一些 你用 Sigma 命令 用在这里的协方差矩阵上 你会得到同样的答案 这是因为协方差均值 总满足一个数学性质 称为对称正定 (symmetric positive definite)
svd 和 eig 是不同的函数 但当它们用在 协方差矩阵时 可以证明它始终是满足 这个数学性质的 因此用两个命令的结果一样
Sigma 应该是一个 n×n 的矩阵 svd 将输出三个矩阵 分别是 U S V 你真正需要的是 U 矩阵 U 矩阵也是一个 n×n 矩阵 如果我们看 U 矩阵的列 实际上 U 矩阵的 列元素 就是我们 需要的 u(1) u(2) 等等
如果我们想 将数据的维度从 n 降低到 k 的话 我们只需要提取前 k 列向量
因此这就是一个 n × k 维的矩阵 叫做 U 下标 reduce 表示 U 矩阵约减后的版本 我将用它来约减我的数据
然后 计算 z 的方法是 z 等于这个 Ureduce 矩阵的转置乘以 x 维度 k × n *维度 n × 1 = 维度 k × 1 因此 z 是 k 维的 这就是 PCA 的全过程
另外 跟 k均值算法类似 PCA 的 x 应该是 n 维实数 所以 没有 x0 = 1 这一项
Applying PCA
Reconstruction from Compressed Representation
PCA (主成分分析) 作为压缩数据的算法 能将高达一千维度 的数据压缩到 只有一百个维度 如果有一个这样的 压缩算法 那么也应该有一种方法 可以从压缩过的数据 近似地回到原始高维度的数据

给出一个一维实数点z 我们能否 让z重新变成原来的 二维实数点x? 我们知道 z的值 等于Ureduce的转置乘以x 如果想得到相反的情形 方程应这样变化 x_approx 应该等于 Ureduce乘以z 右图就是还原成二维后的样本
为了检查维度 在这里 Ureduce 是一个n×k矩阵 z就是一个k×1维向量 将它们相乘得到的就是n×1维 所以说 x_approx 是一个n维向量 我们也 称这一过程 为原始数据的重构 ( reconstruction )
Choosing the Number of Principal Components
在 PCA 算法中 我们把n维特征变量 降维到k维特征变量 这个数字k 是 PCA 算法的一个参数 这个数字k也被称作 主成分的数量 或者说是我们保留的主成分的数量

为了选择参数k 也就是要选择主成分的数量 这里有几个有用的概念 PCA 所做的是 尽量最小化 平均平方映射误差 (Average Squared Projection Error)
我还要定义一下 数据的总变差 (Total Variation) 它是这些样本x(i)的 长度的平方的均值 它的意思是 “平均来看 我的训练样本 距离零向量多远? ”
当我们去选择k值的时候 一个常见的 选择K值的经验法则是 选择能够使得它们之间的比例 小于等于0.01的最小的k值 换言之 用PCA的语言说就是 保留了99%的差异性
如果你使用PCA 并且你想要告诉别人 你保留了多少个主成分 更为常见的 一种说法是 我选择了参数k 使得99%的差异性得以保留 了解这个事情是有用的 它的意思是 平均平方映射误差 除以总变差 至多是1% 这是一个可以去思考的 有见解的事情 然而如果你跟别人说 “我有100个主成分” 或者说“从1000维的数据中 得到的k等于100” 这就有点 让人难以理解
可能从95到99 是人们最为 常用的取值范围 对于许多数据集 你可能会惊讶 为了保留99%的差异性 通常你可以大幅地降低数据的维度 却还能保留大部分的差异性 因为大部分现实中的数据 许多特征变量 都是高度相关的 所以实际上 大量压缩数据是可能的 而且仍然会保留 99%或95%的差异性 那么你该如何实现它呢?
你可能会用到这个算法 你可以这样开始 比如你想选取k的值 我们可以从k=1开始 然后我们再进行主成分分析 我们算出 Ureduce z(1) z(2) 一直到 z(m) 算出所有那些 x_approx(1) 一直到 x_approx(m) 然后我们看一下99%的差异性是否被保留下来了 是的话就搞定了 我们就用 k=1 但如果不是 那么我们接下来尝试 k=2 然后我们要重新走一遍 这整个过程 检查是否满足这个表达式 这个式子的值是否小于0.01 如果不是 我们再重复一次 我们尝试 k=3 然后试 k=4 以此类推 一直试到 比如我们一直试到 k=17 然后发现99%的数据 都被保留了 我们就会用 k=17 这是一种用来选择 使得99%的差异性能够得以保留的 最小的k值的方法
但是可以想见 这个过程的效率相当地低
我们在尝试 k=1 k=2 时 做了所有这些计算 幸好 你在应用 PCA 时 实际上 在这一步 它已经给了我们 一个可以使计算变得 容易很多的量 特别是当你调用 svd 来计算这些 矩阵U S V时 当你对协方差的矩阵 Sigma 调用 svd 时 我们还会得到 这个矩阵S 是一个 对角方阵

这里有个等价的计算,就是从 i=1 到 k 对 Sii 求和 除以 从 i=1 到 n 对 Sii 求和 它是否大于等于0.99 如果你想确保能够保留99%的差异性的话 你要做的 就是慢慢地增大k值 把k值设为1 k值设为2 把k值设为3 以此类推 并检验这个数值 找出能够确保99%的差异性被保留的最小的k值 找出能够确保99%的差异性被保留的最小的k值 如果这样做 那么你只需要调用 一次 svd 函数 因为它会给你S矩阵
Advice for Applying PCA
在解决某个计算机 视觉的问题 在这里有 一张100 × 100的图片 那么 如果是100×100 那就是10000 像素 如果 x(i) 是 包含了 这10000像素 强度值的特征向量 那么 你就会有10000维特征向量 像这样有很高维 的特征向量 运行会比较慢

我们应用PCA 将x从10000维江到1000维的z,就有了一个新的训练集样本 (z,y) 然后将这个已经降维的数据集 输入到学习算法 学习出假设函数
最后要注意一点 PCA 定义了从 x到z的对应关系 这种从 x 到 z的对应关系只可以通过 在训练集上运行 PCA 定义出来 当你在 运行PCA的时候 只是在 训练集那一部分 来进行的 而不是 交叉验证的数据集 这就定义了从 x到z的映射 然后你就可以 将这个映射应用到 交叉验证数据集中和 测试数据集中
对于大多数我们实际面对的数据降维问题 降维到原来的五分之一或者十分之一 依旧保持着原本维度数据的变化情况 改变并不会有多少影响 就分类的精确度而言 数据降维后对学习算法 几乎没有什么影响 如果我们将降维 用在低维数据上 我们的学习算法会运行得更快
有关PCA的应用中 第一个是数据压缩 第二是可视化应用
对PCA不好的应用方面 那就是使用它来避免过拟合 如果我们有x(i) 是有n个特征的数据集 如果我们将数据进行压缩 并用压缩后的数据z(i)来代替原始数据 在降维过程中 我们从n个特征降维到k个 比先前的维度低 例如如果我们有 非常小的特征数目 假如k值为1000 n值为10000 如果我们有1000维度的数据 和我们用10000维度的数据比起来 对于同样是1000个特征来说 或许更不容易过拟合 如果你想使用 PCA方法来对数据降维 以避免过拟合 PCA方法实际看起来是可以的 但是这并不是 一个用来解决 过拟合问题的算法 仔细想想PCA是如何工作的 它把某些信息舍弃掉了 舍弃掉一些数据 并在你对数据标签y值毫不知情的情况下 对数据进行降维
建议 一开始不要将 PCA方法就直接放到算法里 先使用原始数据x(i)看看效果 只有一个原因 让我们相信算法出现了问题 那就是 你的学习算法 收敛地非常缓慢 占用内存 或者硬盘空间非常大 所以你想来压缩 数据 只有当你的x(i)效果不好 只有当你有证据或者 充足的理由来确定 x(i)效果不好的时候 那么就考虑用PCA来进行压缩数据
参考资料