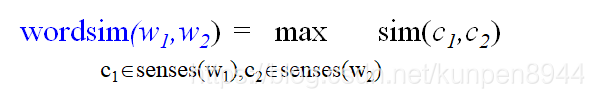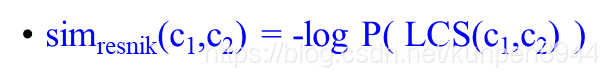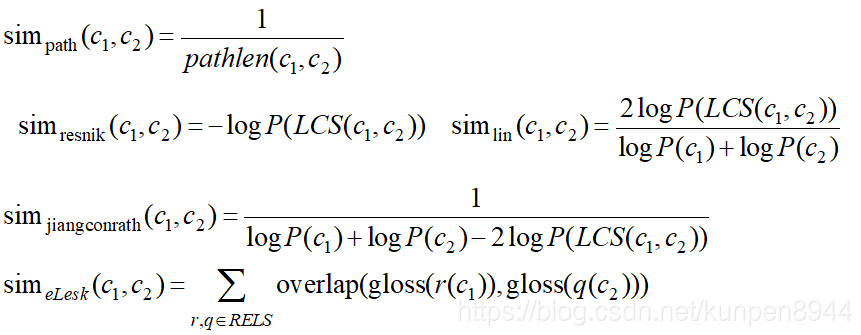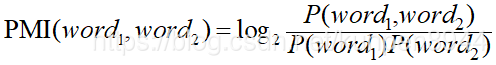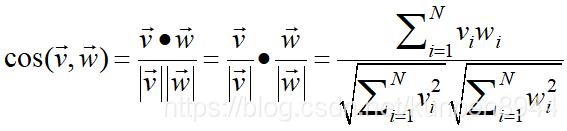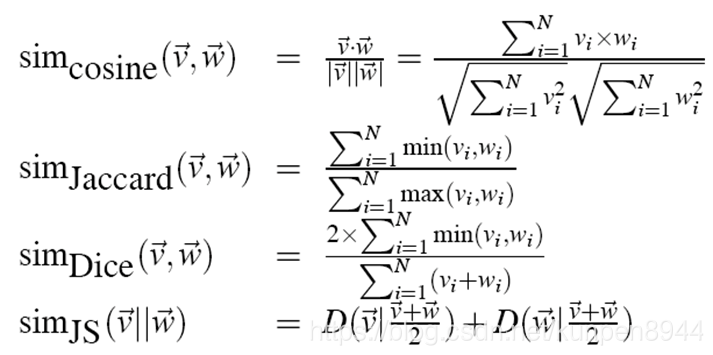斯坦福大学-自然语言处理入门 笔记 第十九课 单词含义与相似性
其他
2018-11-06 12:45:04
阅读次数: 0
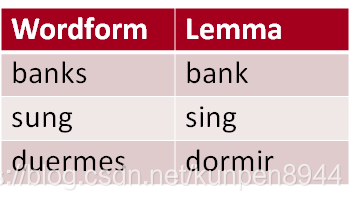
回顾:词目(lemma)与单词形式(wordform)
词目:表示相同的词根、词性以及大致的语义
单词形式:表示在文档中出现的具体单词形式
一个词目可能会含有很多含义(sense)。含义(sense)表示单词意思的一个方面的表现。比如说bank就有两个含义。
…a bank can hold the investments in a custodial account…
“…as agriculture burgeons on the east bank the river will shrink even more”
同音异义词(homonymy):有同一个形式但是有独立不同的含义的单词,形如bank,bat
bank1: financial institution, bank2: sloping land
bat1: club for hitting a ball, bat2: nocturnal flying mammal
同音异义词分为两种: 同形异义(Homographs )(bank/bank, bat/bat);同音异义(Homophones):Write/right或者Piece/peace
同音异义词可能会引起NLP应用的很多问题:信息检索(“bat care”),机器翻译(bat: murciélago (animal) or bate (for baseball)),文档发音(bass (stringed instrument) vs. bass (fish))
一词多义(polysemy):多义词会有相关联的含义。一词多义可以分为两种:转喻(metonymy)以及系统性的(systematic)。大部分的一词多义都是系统性的,比如school,hospital等等都可以既指组织又指建筑。
我们怎么知道单词有一种以上的含义?zeugma测试。
利用连词把两个句子连起来,然后看一下句子是否奇怪,如果奇怪的话就说明有两种含义。
句子1:Which flights serve breakfast?
句子2:Does Lufthansa serve Philadelphia?
连起来:?Does Lufthansa serve breakfast and San Jose?
同义(synonyms):在某些语境下单词有相同的含义
couch / sofa big / large automobile / car Water / H20
如果他们能在所有语境中互相替代,我们就认为他们有相同的命题含义(propositional meaning)
但是基本有没有完全同义的两个单词,即使在某些情况写是完全一致的,但是在正式用语,俗语等等各种方面还是会有所不同的。因此,同义是一种针对含义(sense)的关系,而不是针对单词的关系。比如下面的big和large的例子,前者是同义,后者则不是。
反义(Antonyms):在某一种含义上有相反的含义。可以是对立的两个方面,或者是反向关系。比如:
下义(hyponymy)与上义(hypernymy):如果一种含义是另一种的子集的话,我们认为前者是后者的下义,后者是前者的上义。比如car是vehicle的下义,vehicle是car的上义。下义一般是具有传递性的,如果A是B的下义,B是C的下义,那么A也是C的下义。我们也可以称下义为IS-A等级(IS-A hierarchy)
分类词典在很多的领域都有广泛的应用:信息抽取,信息检索,问答系统,生物和药物信息学,机器翻译等等
其中一个典型的在线分类词典就是Wordnet,它是一个按照层次组织的词汇数据库,是一个在线的分类词典,同时也包含一些除了英语以外的其他语言。
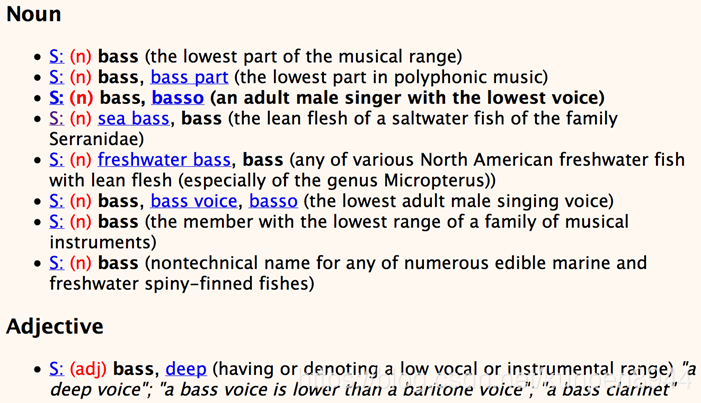
一个具体单词的展示:下面的一个S就代表一个含义(sense)
对于同义关系的表达,我们会用对同一个同义注释集的单词的含义进行标注。比如chump1, fool2, gull1, mark9, patsy1, fall guy1, sucker1, soft touch1, mug2,这个九个单词的对应序号的含义是同义的,就都对这些含义打上标注(gloss)“a person who is gullible and easy to take advantage of”。
上义关系的展示
WordNet的名词关系
WordNet3.0 :http://wordnetweb.princeton.edu/perl/webwn
这个是专门针对医学领域的分类词典,包含177000款目词(entry term)以及26142主题词(heading)
MeSH的用途:提供同义词(即款目词);提供上义关系(层次);MEDLINE/PubMED数据库的索引
同义(synonymy):是一个二分类问题,两个单词要么同义要么不同义
相似度(similarity):是一个更宽松的度量,如果两个单词在意思更接近,就更相似
相似度是一个和含义(sense)相关的关系,而不是和单词相关的关系,因此我们在衡量的时候是以某个单词的某个含义来进行衡量的,比如Bank¹相似于fund³。但是我们会同时在单词和含义的基础上计算相似度。
计算相似度的应用领域:信息检索,问答系统,机器翻译,自然语言生成,语言模型,自动论文打分,抄袭检测,文档聚类
单词相似度(similarity) 和单词相关度(relatedness)是不一样的:相似的单词是度量单词的同义程度;单词可以以各种可能进行关联,比如car和bicycle关联,car和gasoline关联。
计算单词相似度有两种方法:
基于分类词典的方法:判断单词在上义等级中是否接近?单词是否有相似的标注(gloss)
分布算法:判断单词是否有相似的上下文分布
基于路径的相似度
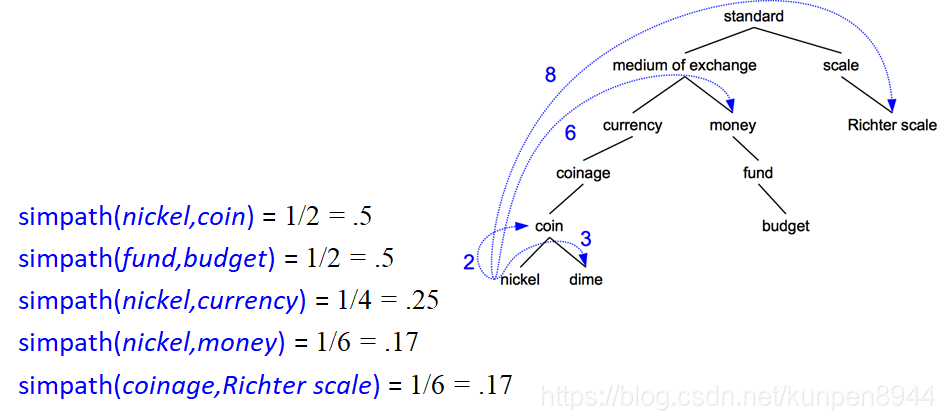
如果两个含义(sense)在分类词典的层次中越接近,就认为他们越相似。这种接近程度以路径长度为度量
路径长度:pathlen(c1,c2)=1+ c1和c2之间在上义关系图中最短路径的边数
相似路径:simpath(c1,c2)=1/pathlen(c1,c2)
单词相似度:wordsim,对两个单词的含义组合配对计算相似度,然后取最大的那个
计算例子
基于这种方法存在的问题
这种方法假设每个层次关系都有一样的距离,但是我们在上面的例子中可以看到nickel和money以定会比nickel和standard的更接近,因为在层次中比较高的节点含义会更抽象,但是基于路径的相似度结果计算出来却是一样的。
所以我们想要中的度量需要满足下面两个条件:1,独立代表每个边的代价;2、只通过抽象节点连接的单词相似程度更低
信息内容(content)相似度量
定义P(c)表示在语料库中随便取的一个单词是概念c的一个实例(instance)的概率。所以,这是一个在层次中所有概念都有的随机变量。对于一个给定的概念,每个观测到的名词要么是概念中的成员,概率是P(c),要么不是成员,概率是1-P(c)
所有的单词都是根节点(entity)的成员,所以P(root)=1
在层次中一个节点越低,它的概率就越低
我们可以通过在语料库中计数来进行训练:每个hill的实例都计入natural elevation, geological formation, entity等的频率。计算公式如下,其中words©表示c及其所有的子节点
信息内容:IC©=-log§
最富信息类(subsumer)/最低公共类(subsumer),即LCS(c1,c2)也就是c1和c2的最低公共子节点
Resnik相似度计算方法:两个单词之间的相似度和他们的公共信息有关系;两个单词的公共信息越多,他们就越相似。所以计算的相似度就是最低公共类的信息内容,公式如下:
dekang lin方法:这种方法认为相似度计算不仅和公共信息成正比,而且和两者之间的不同成反比。对应的计算公式和计算例子为:
拓展的Lesk算法:这种算法把分类词典中的注释(gloss)放入了相似度计算。如果两个概念的注释有相似的单词那么我们认为这两个概念相似。对于在注释中公共存在的n个单词组成的词组,我们计分为n²。把所有的公共词组,包括上义词和下义词的公共词组的得分都相加,就可以得到一个分数。下面是一个简单的例子:
四种方法的公式总结
内在评估:算法和人工相似度得分进行比较
外在(基于任务的,头尾连接)评估:利用一些需要单词相似度的任务来进行评估,比如拼写错误纠察,WSD,论文评分,以及TOEFL多选词汇题。
不是每一种语言我们都有一个分类词典(thesaurus)
即使我们有该语言的分类词典,但是应用分类词典的算法会有recall的问题
很多单词都没有收录
大部分的词组也没有收录
有一些含义(sense)之间的关联也没有收录
分类词典在动词和形容词上做得不好,因为形容词和动词的结构化的上义关系很少
我们也可以称之为意思的向量空间模型(space-vector model of meaning)
这种模型会比前一种模型的recall更高,但是precision会有所下降
这种模型的基本想法是:如果两个单词的上下文相似的话,这两个单词很有可能就是相似的。举例而言,看下面的四句话,我们很容易就看出加粗部分的单词是一种酒。
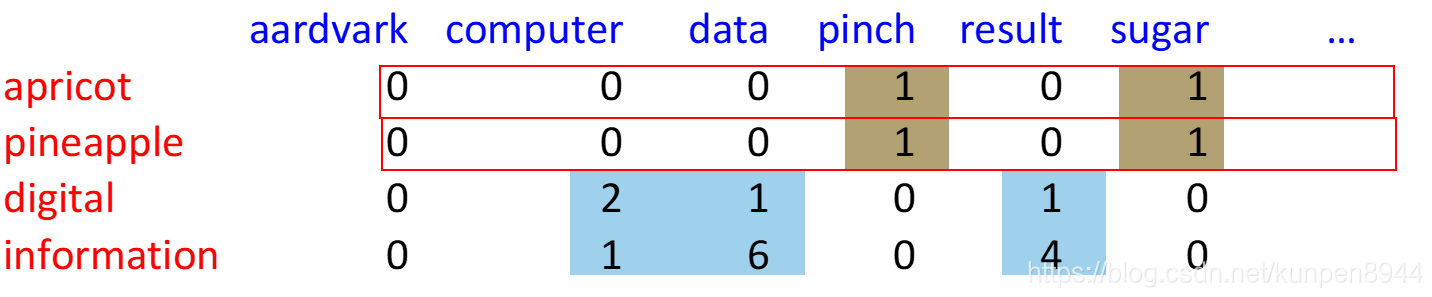
这种模型的第一步是构建项上下文矩阵。这个矩阵基本构建思想是和项文档矩阵一致的。项文档矩阵的每一行表示的是每一个单词,每一列表示的是文档,每一格表示的是该行单词在对应文档中的计数。而项上下文矩阵每一列表示的是下文中出现的单词,每一格表示的是该行单词的上下文中出现该列单词的数量。
所谓的上下文,我们一般指段落,或者是10个单词的窗口。
如果两个单词在他们对应的行向量上是相似的话,就意味着他们的含义相似。
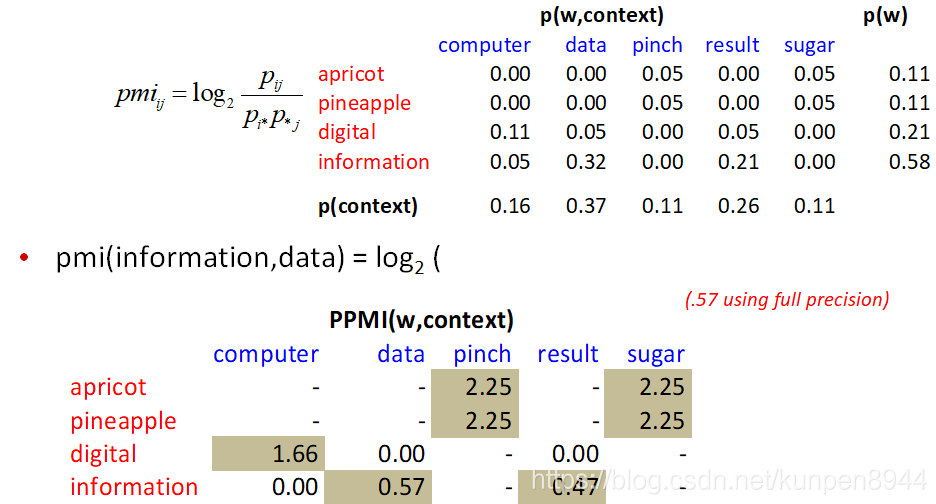
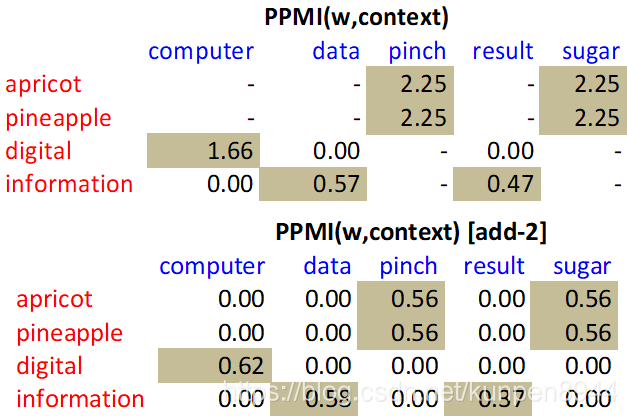
在项上下文矩阵中,我们不是直接使用纯计数,而是使用PPMI(Positive Pointwise Mutual Information)来替代。PMI的计算公式如下,PPMI的区别就是当PMI为负的时候就直接哟个0替代。
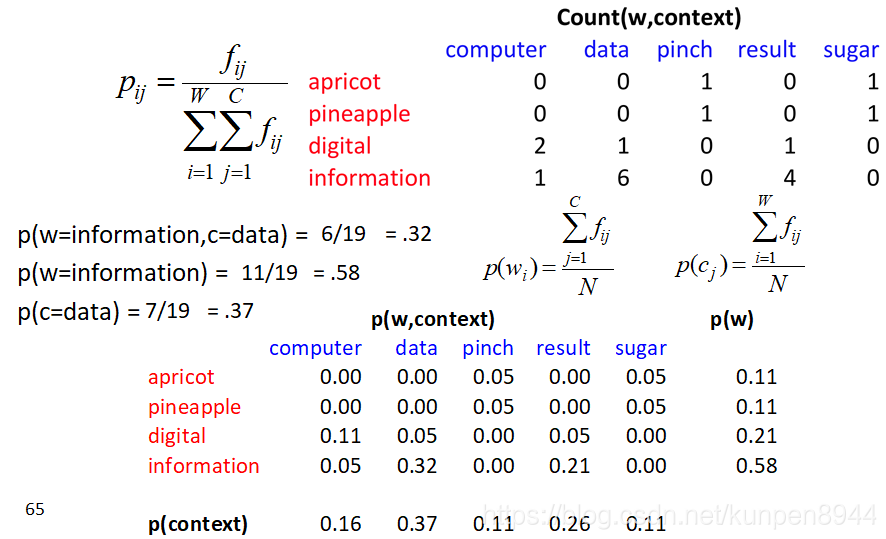
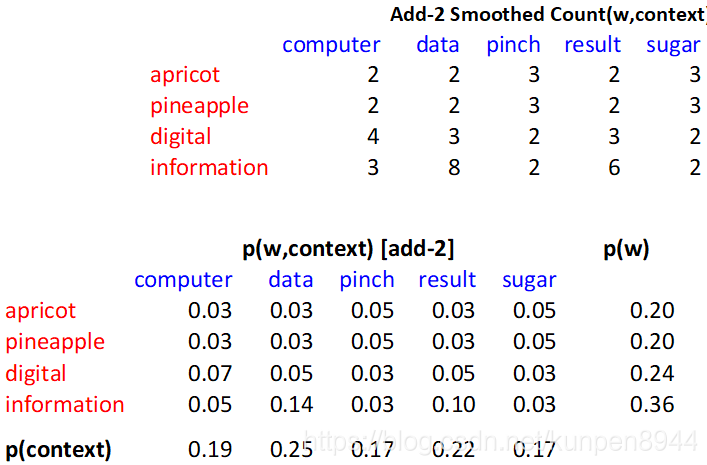
一个计算的例子:W表示行,C表示列
除了这个以外,我们还可以在加入拉普拉斯平滑
在构建项上下文矩阵的时候,上下文矩阵和每一列是单词和对应的单词依存关系,比如主语、介词等等
我们利用cosine来进行相似度估计,公式如下:其中v和w分别表示两个相似单词的对应在项上下文矩阵中的行向量
一个计算的例子
其他相似度的计算
转载自 blog.csdn.net/kunpen8944/article/details/83448258




 - MeSH的层次展现
- MeSH的层次展现