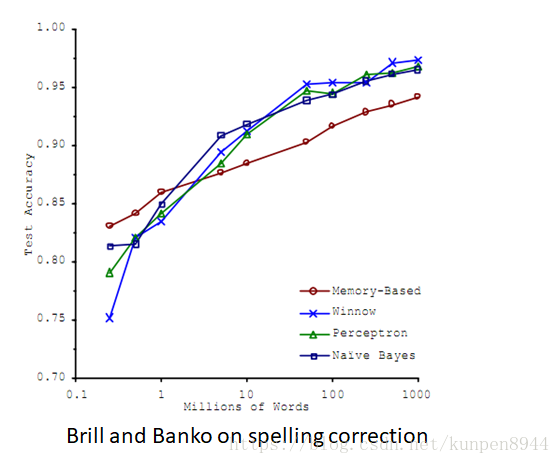
一、文本分类任务概述
1、应用领域
- 归类
- 垃圾邮件识别
- 作者识别
- 性别/年龄识别
- 等等
2、定义
- 输入:一个文档d,一系列固定的类型C={c1,c2,…,cj}
- 输出:预测类别c ∈ C
3、分类方法
- 手工规则:很精确但是代价很高
- 监督机器学习:
- 输入:一个文档d,一系列固定的类型C={c1,c2,…,cj},一个训练集包含m个样本,每个样本是手工标记的文档(d1,c1)…(dm,cm)
- 输出:γ:d→c
- 可以使用的分类方法:朴素贝叶斯,逻辑回归,支持向量机,k近邻
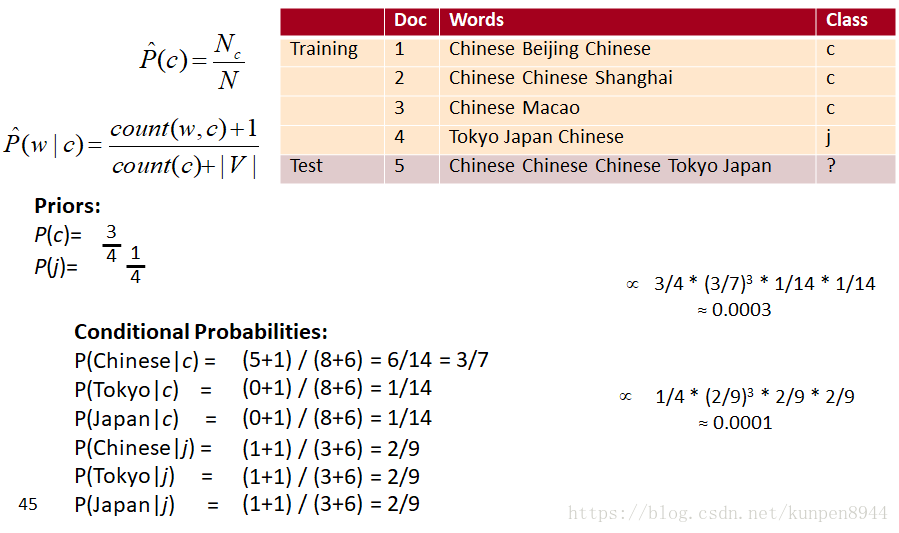
二、朴素贝叶斯
- 朴素贝叶斯的思想:基于贝叶斯规则的简单分类方法,分类的依据是文本的简单代表,词袋(bag of words)
- 把文本抽象成一个个单词以及对应的次数的特征
- 如下



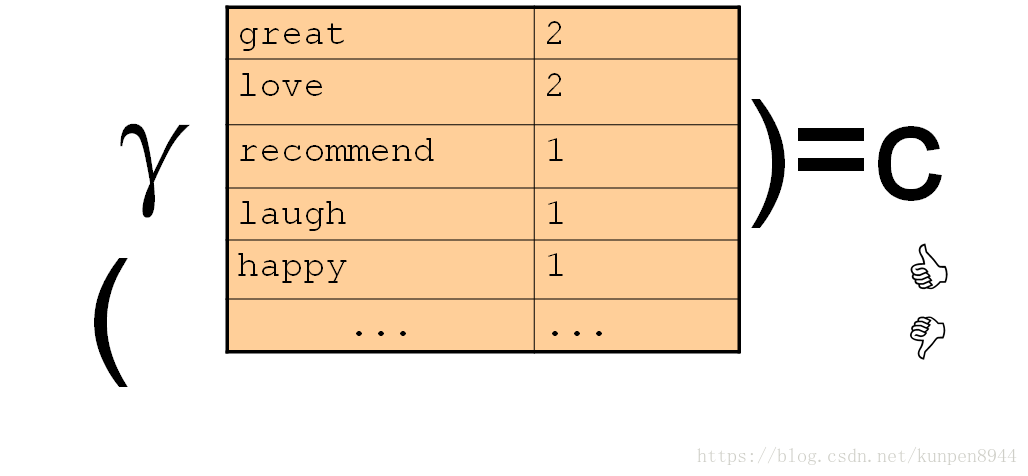
三、定义朴素贝叶斯分类
1、应用于文档和类别的贝叶斯规则
- 公式:
- 其中,d表示文档,c表示类别
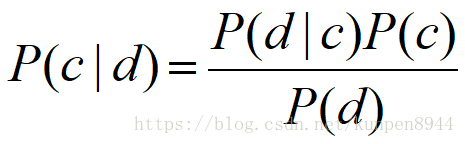
2、朴素贝叶斯分类
- 公式推导1:我们需要求的是使得P(c|d)最大的类别c。利用贝叶斯规则可以得到第二行的公式,因为第二行的分母对任何类别都是一样的,不影响argmax的计算。所以,可以忽略掉分母。
- 公式推导2:把d用x1,x2等特征表示
- 基于上述公式进行估计的话,需要估计的参数量级很大,因此对样本数量的要求会很高。
- 参数量级
- 参数量级
- 因此,我们需要进行一些假设来简化模型
- 词袋(bag of words)假设:单词的文职不重要
- 条件独立(conditional independence):对于特征而言,基于c的条件概率是相互独立的
- 基于上述两点,上述公式可以推导为
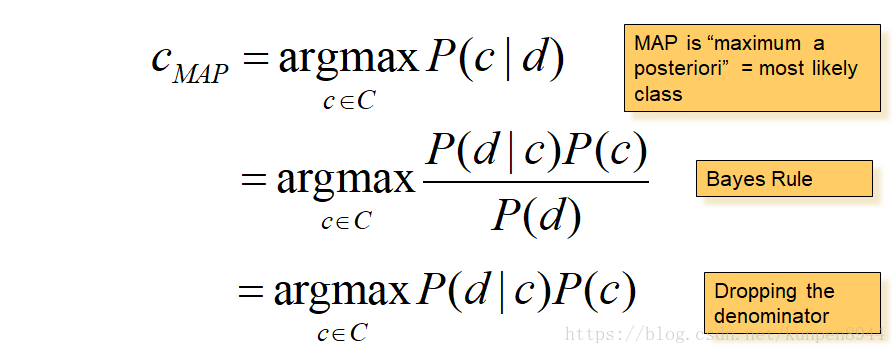
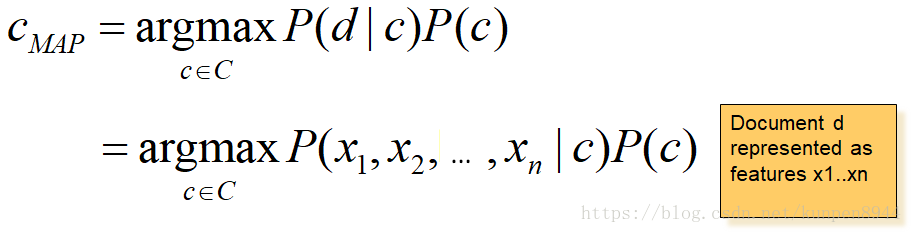
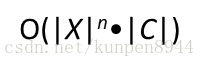
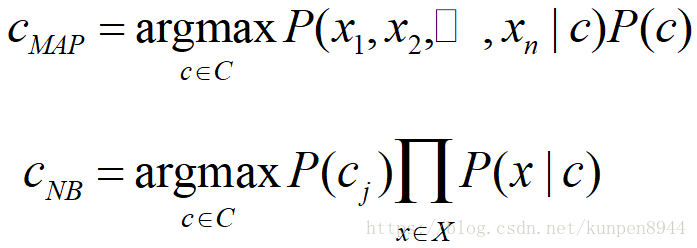
四、朴素贝叶斯的训练
1、极大似然估计
- 朴素贝叶斯的训练的一个方法是极大似然估计,利用数据的频率进行计算
- 极大似然估计的问题:如果在训练集中没有出现单词的话这个单词的P(w|c)就是0,那么对应的基于下面公式的c也是0,就无法进行分类
- 基于上述的问题,我们就需要使用加一平滑也就是拉普拉斯平滑来解决,解决的公式是
- 对于一个训练语料库而言,训练公式如下
- 如果遇到未知(unknown)的单词的处理方法,公式如下
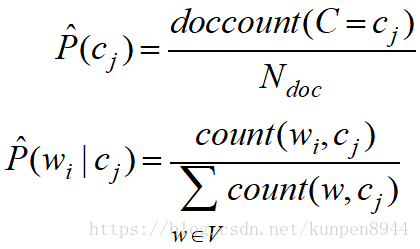
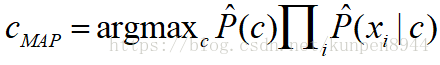
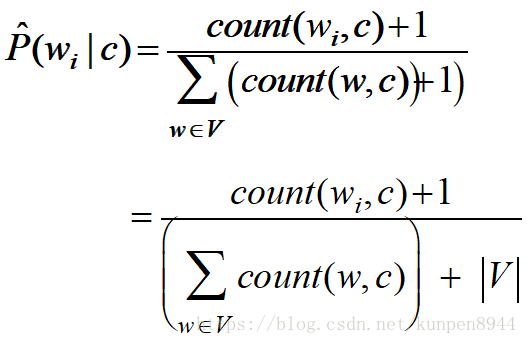

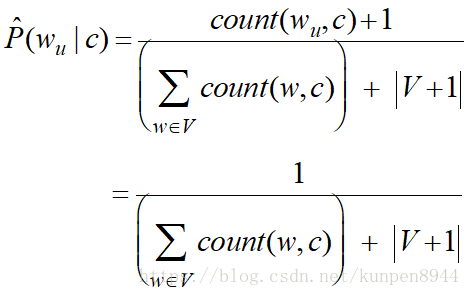
五、朴素贝叶斯:和语言模型的关系
- 朴素贝叶斯的每一个类别就是一个条件于类别的一元语言模型
- 对每个单词而言,他们的概率是P(word|c)
- 对每个句子而言,他们的概率是P(s|c)=∏ P(word|c)
- 贝叶斯最后的结果而言,就是选择比较大的P(s|c)的类别
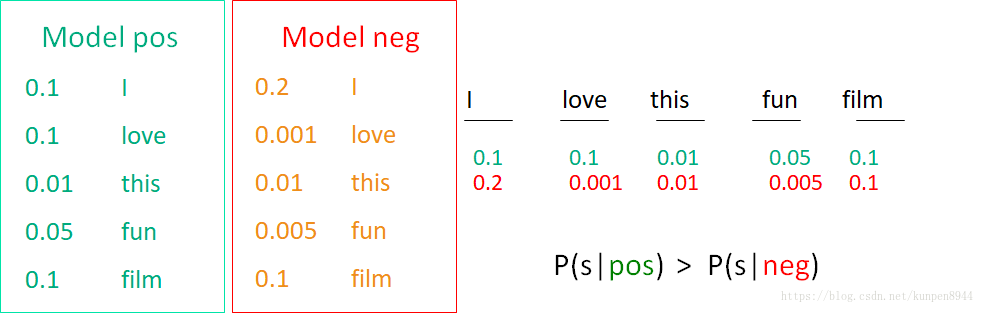
六、关于多元朴素贝叶斯的例子
- 实例:
- 在垃圾邮件检测领域,写有效的应用于贝叶斯的特征:
- 关于朴素贝叶斯的总结
- 非常快,并且对内存的要求低
- 对不相关的特征十分稳健
- 在有很多同等重要的特征的时候表现得比较好
- 如果独立假设存在的话是最好的
- 是文本分类一个很好的可依靠的底线

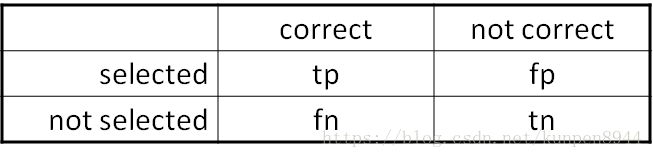
七、precision,recall and f measure
- 依据预测的结果(selected)与实际的分类(correct)可以将样本分为四类
- 因为准确率在估计样本不均衡的时候并不是有效的,所以需要引入下面的度量
- precision:表示预测的结果是正确的百分比 tp/(tp+fp)
- recall:表示实际分类中被预测到的百分比 tp/(tp+fn)
- F值:是precision和recall的加权调和平均数,调和平均数会更加接近比较小的数
人们一般会使用f1值来估计,是上面的计算公式中β为1,α为1/2的度量
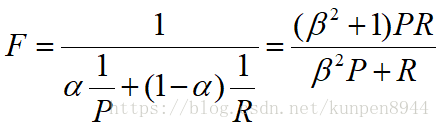
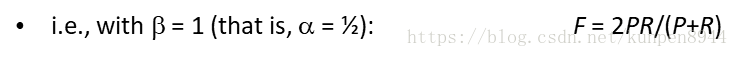
八、文本分类评估
1、用于评估的数据集


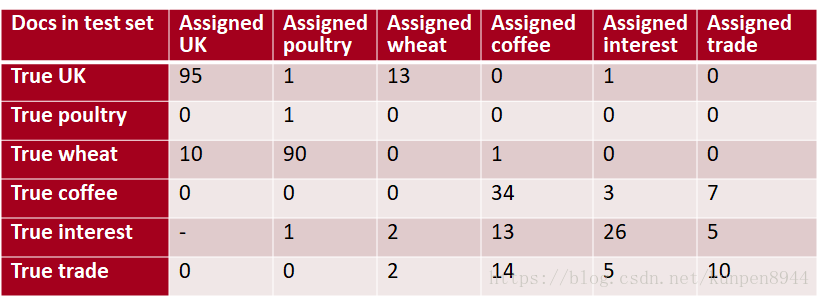
2、混淆矩阵(confusion matrix)C
- 对所有的类别建立混淆矩阵,列表示实际的类别,行表示预测的类别
- recall:在类别i中的文档被预测正确的比例
- precision:被分为类别i的文档中实际为i分类的类别的比例
- accuracy:被正确分类的文档比例
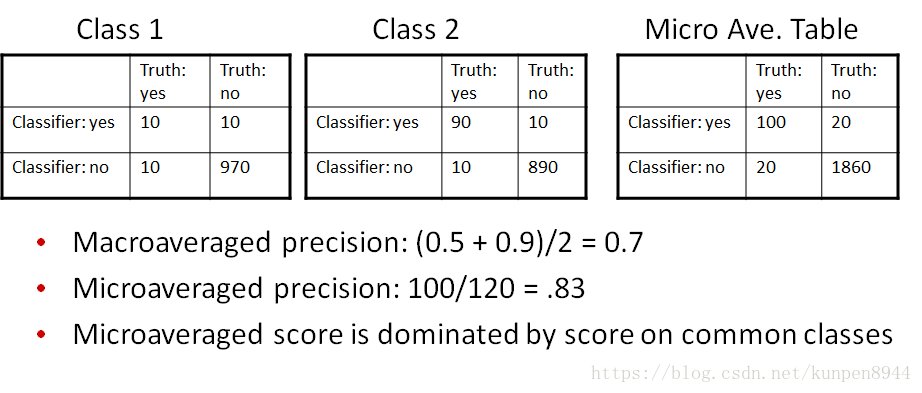
- 当分类大于两类的时候,我们用下面两种方法把多个指标合并
- 宏平均(macroaveraging):单独计算每个类别的度量,然后平均
- 微平均(microaveraging):把每个类别的结果归入下面列联表中,然后计算
- 举例:
3、发展测试集(development test set)与交叉检验
- 一般会把数据分为三类,一类是训练集,一类是发展测试集,一类是测试集。
- 测试集:避免过拟合、估计更保守
- 发展测试集:用来调整算法
- 交叉检验:发展测试集的存在可能会导致测试集过小,所以我们可以使用交叉验证的方法来构造发展测试集。


九、文本分类:实际中会遇到的问题
- 没有训练数据怎么办?
- 人工写规则:需要非常小心并且十分费时(两天一个类)
- 数据很少怎么办?
- 使用朴素贝叶斯:朴素贝叶斯是一个高误差(high-bias)的算法,不容易现过拟合问题
- 获得更多的标记数据
- 尝试半监督训练方法:bootstrapping或者是针对非标记文本的EM算法
- 合理的数据量
- 对更“聪明”的分类方法会更好:SVM,正则逻辑回归
- 使用解释性更强的决策树
- 有很多很多的数据
- 可以得到很高的正确率
- 代价是:svm的训练时间和knn的测试时间都会很长;正则逻辑回归可能会好一点
- 朴素贝叶斯的速度在这种情况就是优势
- 当数据足够的时候,算法就不重要了
- 其他的要点: