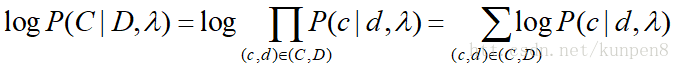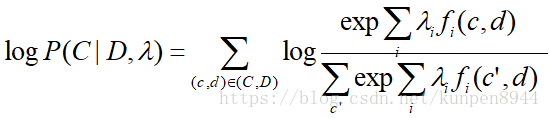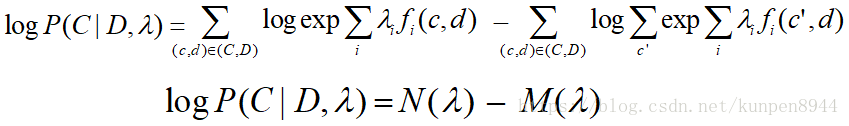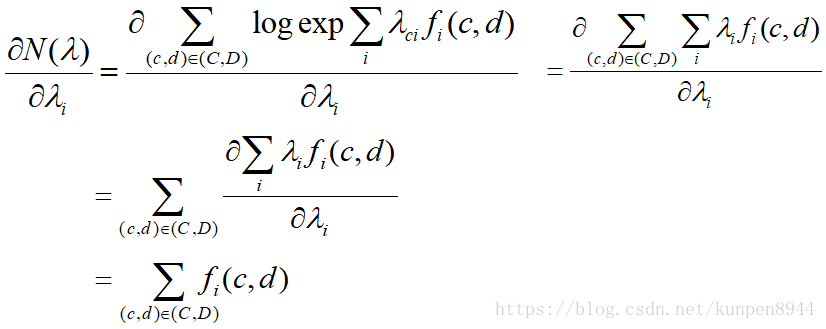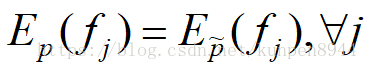一、生成模型与判别模型
1、引言
- 到目前为止,我们使用的是生成模型(generative model),但是在实际使用中我们也在大量使用判别模型(discriminative model),主要是因为它有如下的优点:
- 准确性很高
- 更容易包含很多和语言相关的重要特征
- 有助于建立language independent, retargetable NLP modules
2、比较
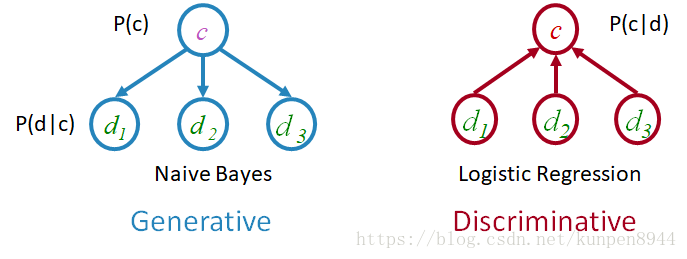
- 生成模型,Joint (generative) models,关注的是观测数据和隐藏类别的联合分布P(c,d),并试图将之最大化
- 判别模型,Discriminative (conditional) models,关注的是,在给定数据的情况下,隐藏类别的概率P(c|d),寻找最大条件似然。虽然这个更困难一些,但是这个与任务本身的关联性更强。
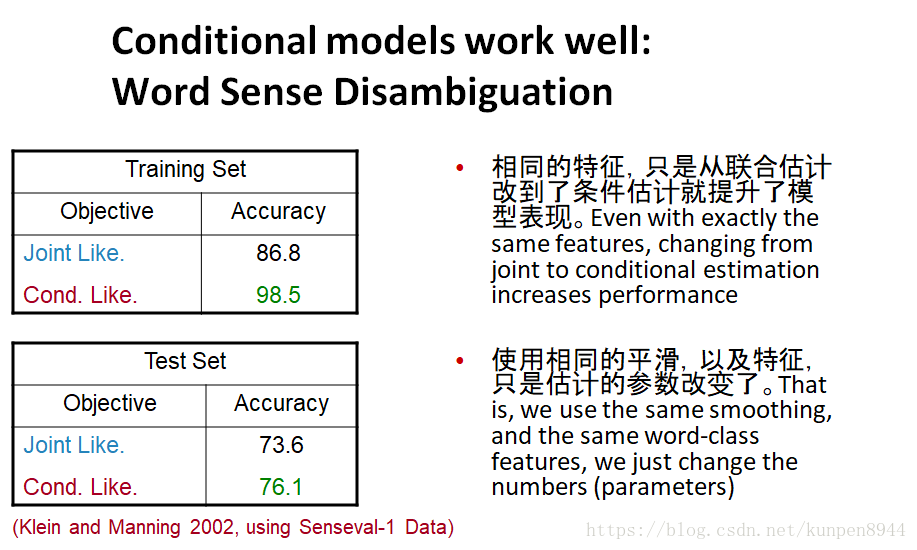
- 基于实验的比较结果
二、为判别模型从文本中寻找特征
- 特征(feature)是一系列把我们观测到的d和我们想要预测的类别c联系到一起的证据(evidence)。特征是在实数范围内一个函数f:C*D→R
- 我们定义了两种特征期望
- 特征的实证期望(empirical expectation)
- 特征的模型期望(model expectation)
- 特征的实证期望(empirical expectation)
- 我们定义了两种特征期望
- 模型会给每个特征分配一个权重
- 正权重说明这种结构很可能是正确的
- 正权重说明这种结构很可能是不正确的
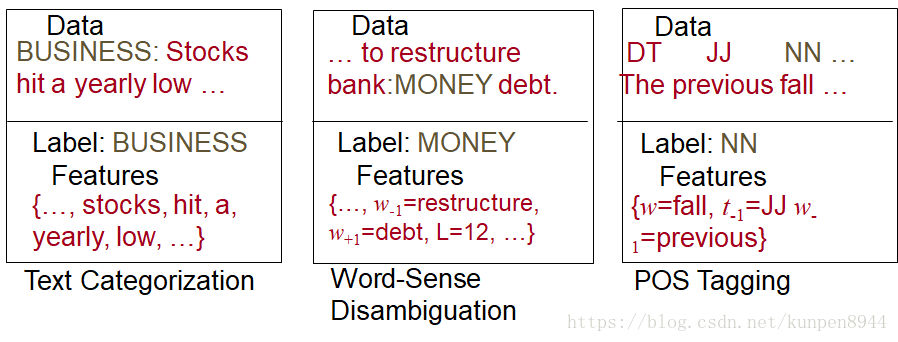
- 基于特征构建的模型的一些例子:第一个是使用了词袋,第了在单词附近的单词是否是某个特定单词的特征,第三个加入了前一个单词的词性特征
- 一个文本分类的例子
- (Zhang and Oles 2001)
- 特征是文档中的每一个单词,并进行一定的特征筛选,然后进行文档分类
- 在测试集上的度量:朴素贝叶斯f1(77.0%),线性回归(86.0%),逻辑回归(86.4%),SVM(86.5%)
- 论文强调了对使用判别模型对正则化(平滑)的重要性,这在早期的NLP/IP研究中很少使用。
- 其他最大熵分类模型的例子
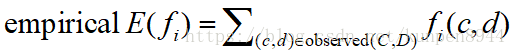
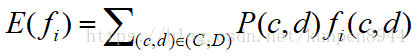

三、怎么样把特征放到分类器中
1、基于特征的线性分类器
- 具体步骤
- 从特征集对类别建立线性函数
- 为每个特征分配权重λ
- 对每个观测到的数据考虑分类
- 特征根据权重进行投票
- 选择结果最大的类别
- 计算权重的方法(感知机,SVM)
- 指数模型(对数线性,最大熵,逻辑,Gibbs)
- 利用之前计算的线性组合∑λf(c,d)计算概率模型:为了保证计算出的概率是正的,需要加一个exp;同时为了保障概率在0-1的范围内,分母进行了标准化,即把该样本对应所有类别的投票结果加起来了作为分母。
- 利用之前计算的线性组合∑λf(c,d)计算概率模型:为了保证计算出的概率是正的,需要加一个exp;同时为了保障概率在0-1的范围内,分母进行了标准化,即把该样本对应所有类别的投票结果加起来了作为分母。
- 这个模型也被称为softmax模型,主要的原因是对一个数字指数化数字变大,因此在该模型中原来的数字越大,对结果数字的影响就会越大,所以称为soft-max。
- 基于模型的类型,我们选择的是使得数据的条件概率最大的λ作为参数。

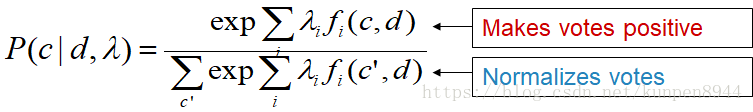
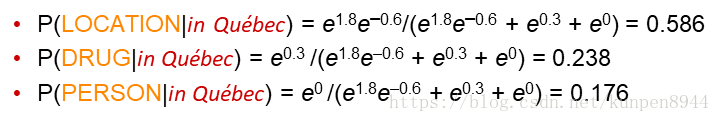
2、逻辑回归
在NLP领域的最大熵模型和统计领域里多分类逻辑回归模型基本是一致的,只有两个变动:
- 参数化(parameterization)会有点不同,因为NLP模型有很多稀疏特征
- NLP中特征方程很重要
四、基本要点
建立一个最大熵模型的基本要点


五、判别模型与生成模型:证明重复计数会造成问题
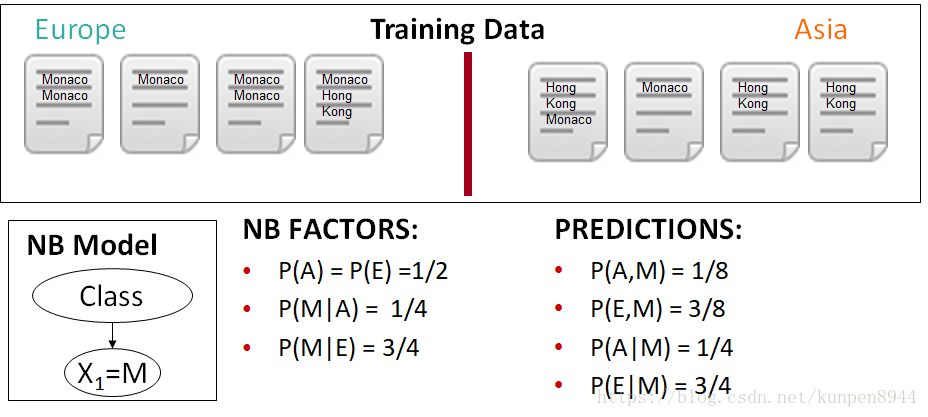
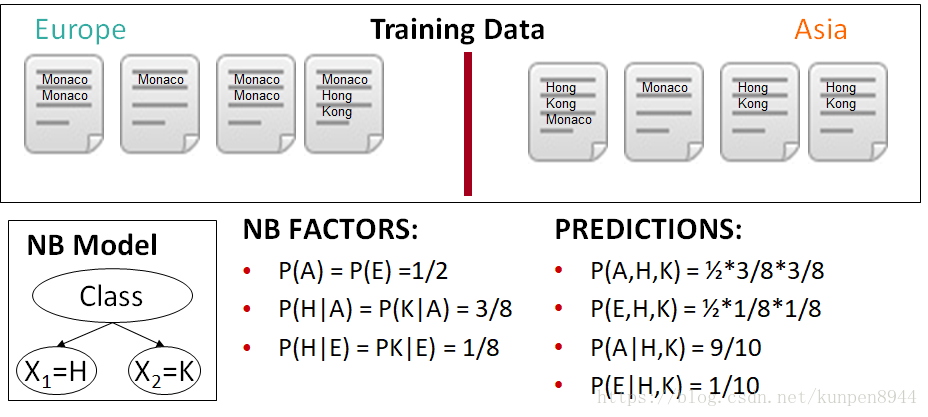
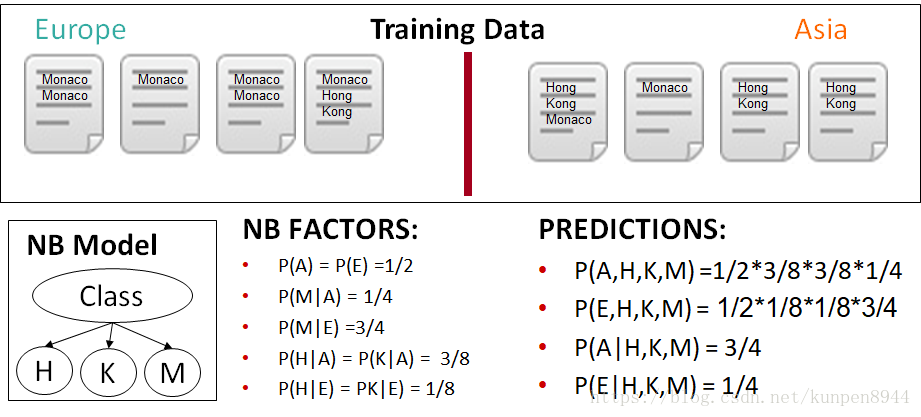
一个朴素贝叶斯计算的例子:训练样本是八个文档,两个类别,europe类别有四个文档,asia有四个文档。每个文档包含Monaco和Hong Kong这些词。概率表示中的大写字母是对应单词的首字母缩写。
在下面的例子中,计算结果P(A|H,K)和P(E|H,K),两者之间的比例存在问题,主要的原因是Hong和Kong实际是一个相关性很高的单词,但是在朴素贝叶斯的假设中这两个单词是相互独立的。
贝叶斯模型和最大熵模型一个重要的不同是,贝叶斯模型会重复计算相关的证据,但是最大熵模型就可以解决问题。
六、最大似然(likelihood)
- 极大似然模型:选择使得数据的似然性最大的参数值。
- 对一个数据(C,D),最大熵模型的条件似然公式如下:
将P(c|d,λ)的公式带入,得到:
可以将上述公式,拆解成为分子和分母两个部分。这个公式的导数,就是这两部分的导数之差。
N(λ)的导数表示特征的实证预期(empirical expectation)
M(λ)的导数表示特征的预测预期(predicted xexpectation)
最佳的参数是使得这两个预期相等的参数,最优分布永远是唯一并且肯定存在的。
这个模型又被叫做最大熵模型,因为这个模型有最大熵并且满足如下条件限制:
- 最优参数的计算
- 最优参数应该满足下面的要求:使得训练数据的条件对数似然(∑logP(c|d))最大化。
- 具体方法有如下几种: