一、词性(part-of-speech)介绍
- 词性:名词(Nouns),动词(Verbs),形容词(Adjectives), 副词(Adverbs)等等就是我们想要研究的词性
- 我们可以把词性分为开放类(open class)和闭合类(closed class)。
- 闭合类只有固定的一些词不会再增加,包含
- 限定词(determiners):a,an,the
- 代词(pronouns):she,he,I
- 介词(prepositions):on,under,over,near,by…
- 开放类的词是会增加的,包含
- 名词、动词、形容词、副词
- 闭合类只有固定的一些词不会再增加,包含
- 这些类中,又可以细分成其他的小类
- 一个单词可能有不止一个词性,如back(见下图)。所以所谓的词性标注是指在具体上下文环境中的单词的词性标注。


二、词性标注(Part-of-speech tagging)
- 词性标注就是对具体的句子中的单词进行标注,例子如下
- 输入:Plays well with others
- 输出:Plays/VBZ well/RB with/IN others/NNS
- 这里使用的词性标记叫做Penn Treebank POS tags。具体的词性标记缩写和对应的介绍,可以查看这个博客((自然语言处理文档系列)Penn Treebank词性标记集)。
- 词性标注的作用
- 帮助我们对单词的发音做判断(在不同的词性是单词的发音是不同的)
- 对输出结果我们可以写正则表达式,比如(Det) Adj* N+
- 把这个作为句法分析(praser)的输入可以加快分析
- 在其他的任务中,我们可以不用单词本身而是直接使用它的词性,这样的话就可以减少特征稀疏的情况。
- 词性标注程序的表现
- 目前表现最好的程序的正确率是97%
- 但是一个基础程序(baseline)的正确率也可以达到90%(假设每个单词的标记都是它出现频率最高的标记,不认识的单词就标记为名词)
- 词性标记这么容易取得很高的正确率的原因是:很多单词的词性都是很清晰的,我们可以依据标点符号,a,the等这些来进行判断。比如:
- 词性标注的难点
- 在Brown语料库中有11%的单词类型无法直接判断词性。这个其中有一些是非常常见的单词,比如that
- 所以,在实际文本中有40%的token是无法直接进行判断的。
- 在Brown语料库中有11%的单词类型无法直接判断词性。这个其中有一些是非常常见的单词,比如that


三、如何构建词性标注模型
- 判断词性标注的主要信息来源
- 周边单词的信息:限定词后面主要是名词
- 单词本身出现的概率:man一般出现都是名词
- 一般而言,第二种信息是更有用,但是第一种信息也是有帮助的
- 特征构建:一些特征
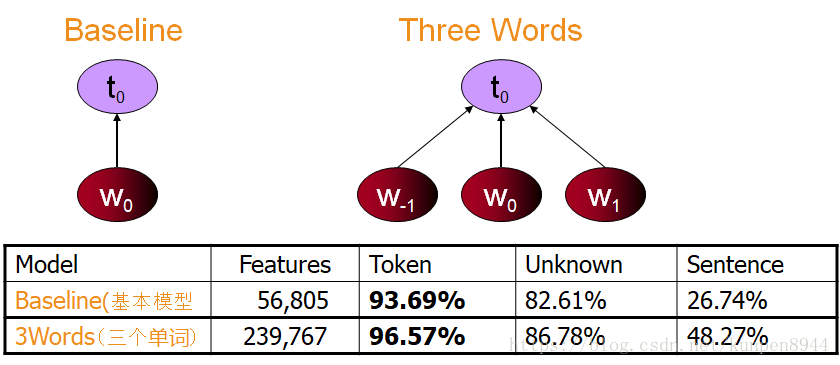
- 模型构建和对应的正确率
- 如何提升有监督模型的结果:构造更好的模型
- 直接使用分类模型而不是序列模型我们也可以得到很好的效果



四、总结
- 对于标注而言,从生成模型改为判别模型不会导致很大的提升。存在的有一个收益是解决了特征重叠存在的问题(比如单词本身和前缀)。
- 另外,判别模型的一个优势是高正确率,但是以更慢的训练速度为代价的