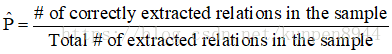一、简介
- 关系抽取就是从文档中抽取关系,例子如下:
- 为什么进行关系抽取
- 创建新的关系型知识库(knowledge bases)
- 增强目前的知识库(knowledge bases)
- 支持问题回答(question answering)
- 一些例子
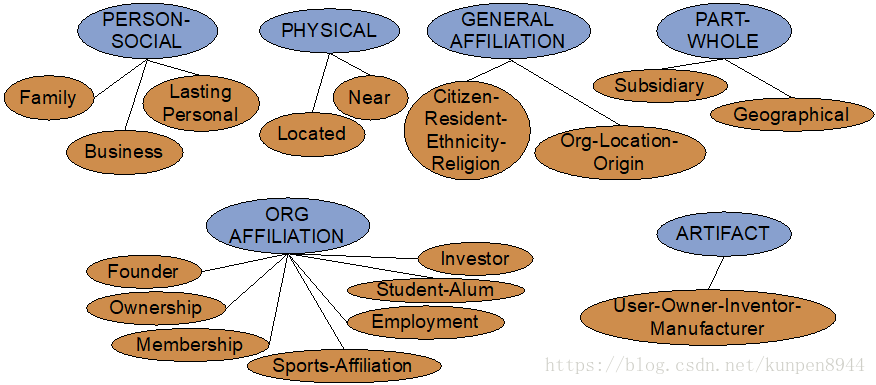
- 自动内容抽取(Automated Content Extraction (ACE))
- 2008年关系抽取任务的17种关系
- 2008年关系抽取任务的17种关系
- UMLS: Unified Medical Language System
- 自动内容抽取(Automated Content Extraction (ACE))
- 如何建立关系抽取器
- 人工定义的模式
- 有监督的机器学习
- 半监督与无监督
- 利用种子(seed)进行bootstrapping
- 远程监督(Distant supervision)
- 从网页进行无监督学习




二、利用模式(pattern)进行关系抽取
1、抽取is-a关系的规则
- X和Y相似的语句规则

2、利用规则抽取更丰富的关系
- 主要思想:关系永远发生在特定实体之间,所以我们使用命名实体标签(named entity tag)来帮助我们进行关系抽取。
- 例子:比如说谁在什么组织做什么事情?

3、人工建立关系模式
- 优点
- 人工模式会更精确(high precsion)
- 可以根据特定领域进行修改
- 缺点
- 人工模式的recall很低
- 需要花工作来考虑所有可能的模式
- 但是不要对所有的a都使用这种方法
三、监督型关系抽取
1、监督型关系抽取的机器学习流程
- 选择一些我们想要抽取的关系
- 选择一些相关的命名实体
- 寻找并标记数据
- 选择一个有代表性的语料库
- 在语料库标记命名实体
- 人工标注这些实体之间的关系
- 将它分成三个部分(train,development,test)
- 在训练集上训练分类器
- 找到所有的命名实体对(通常在同一个句子中)
- 判断两个实体是否相关
- 如果是的话,就对关系进行分类
- Question:为什么要分两步来进行分类?
- 分类训练会比较快,因为第一步会排除大部分的无效对
- 对每个任务都可以使用合适的特征集
2、特征构建
任务:对在一个句子中的两的关系进行分类
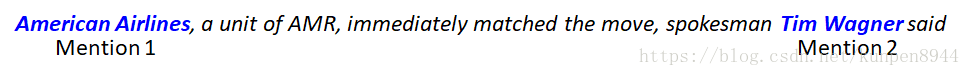
- M1和M2的中心词,以及两者的结合 Airlines,Wagner,Airlines-Wagner
- M1和M2的词袋以及二元组 American, Airlines, Tim, Wagner, American Airlines, Tim Wagner
- M1和M2左边和右边的单词 M2: -1 spokesman,M2: +1 said
- M1和M2中间的单词的词袋和二元组(bigram)a, AMR, of, immediately, matched, move, spokesman, the, unit
- 命名实体的类型 M1: ORG M2: PERSON
- 两个命名实体之间关联:ORG -PERSON
- M1和M2的实体层级(entity level)一共三类(NAME,NOMINAL-比如the company,PRONOUN-比如it 和这样的代词):M1 NAME,M2 NAME
- 两个实体之间的单词的基本语法块(syntactic chunk词性序列:NP NP PP VP NP NP
- 两个实体之间的树的成分路径(constituent path):
- 依赖路径(dependency path):Airlines matched Wagner said
- 关于家庭的触发清单(trigger list):亲戚关系词 parent, wife, husband, grandparent, etc. [from WordNet]
- gazetter:有用的地理词列表,国家名字以及其他子实体名字

3、有监督方法的分类器
- 可以使用任何分类器:最大熵、朴素贝叶斯、SVM
- 在训练集上训练,在发展集上调试,在测试集上测试
4、有监督关系抽取的评估
- 为每个关系计算precision,recall以及F1
5、总结
- 优点:如果有足够的手工标注的数据,并且测试集和训练集相似的话,可以得到很高的正确率
- 缺点:标注大量的训练集是很贵的;有监督模型对其他的类型的泛化能力不足
四、半监督或者无监督关系抽取
1、关系bootstrapping(Hearst 1992)
- 收集一些关系为R的种子对(seed pair)
- 迭代
- 找到有这些单词对的句子
- 找到这些单词对的上下文,泛化成模式(pattern)
- 找到新的单词对
- 例子1
- 例子2


2、滚雪球法(snowball)
- 参考文献:E. Agichtein and L. Gravano 2000. Snowball: Extracting Relations
- 和上面的方法一样的迭代算法
- 也和上面一样利用例子(instance)抽取特征,但是不同的是X和Y都必须是命名实体,并且为每个模式计算置信度。

3、远程监督(distant supervision)
- 参考文献
- 远程监督的思想:假设一个句子包含某对实体,那么这个句子应该蕴含了两个实体间的关系(Freebase中罗列的关系之一),可以将这个句子作为该实体对所对应关系的训练正例。(引自https://blog.csdn.net/wen_fei/article/details/80500654?utm_source=blogxgwz1)
- 具体步骤:
- 对每个关系(relation)中的每一对元组,在语料库中找到同时包含这两个实体的句子
- 抽取高频的特征(语法分析、单词等)
- 用这些模式来训练监督模型


4、无监督关系抽取
- 参考文献:M. Banko, M. Cararella, S. Soderland, M. Broadhead, and O. Etzioni. 2007. Open information extraction from the web. IJCAI
- 开放信息抽取:在没有训练数据和关系列表的情况下,从网页中抽取关系
- 利用语法数据(parsed data)训练一个“值得信任的元组”的分类器
- 抽取所有名词短语之间的关系,并且如果分类器认为值得信任的话,就将之保留
- 基于这种关系出现的频率来对该关系排序
5、对无监督和半监督的评估
- 因为它抽取的都是来自网页的新关系,因此我们无法计算precision(不知道哪些是正确的)和recall(不知道那些是错过的)
- 我们只能大致计算一个precision。计算的方法是,从结果中随机抽取一些关系,人工来判断这些关系是否是正确的。正确关系数比上总的关系数就是估计的precision。
- 我们也可以基于不同水平的recall来计算precision
- 前1000个新关系,前10000个新关系,前100000个新关系的precision
- 每一种都进行随机取样
- 但是没有办法进行recall评估