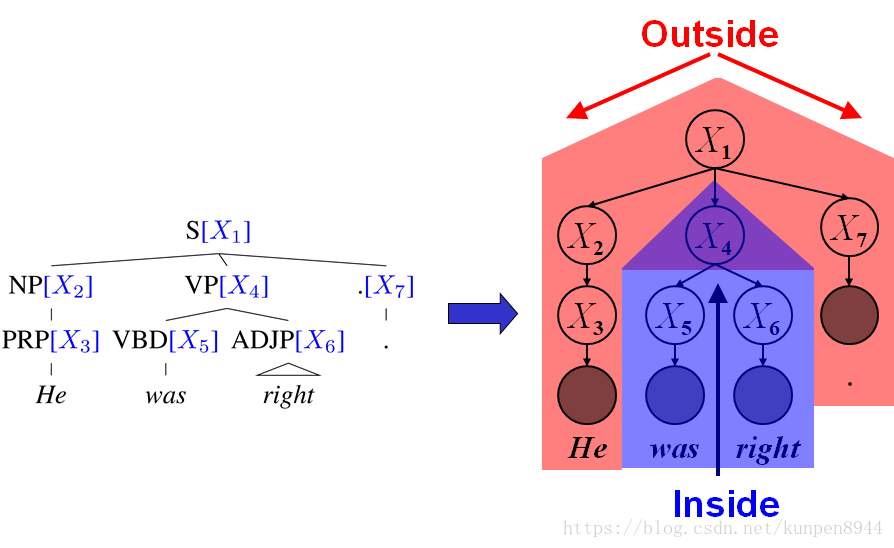
一、介绍
- 一个短语的中心词(head word)可以很好地代表这个短语的结构和含义,在构建PCFG模型的时候,可以考虑将这部分信息纳入其中。如下图所示加入单词信息可以帮助我们更好地选择出合适的模型。

二、Charniak模型
- Charniak模型是词汇化PCFG的一个非常直观的模型。条件概率是自上而下进行计算的,就像一般的PCFG一样,但是实际的语法分析过程是自底向上的,就像CKY算法一样。
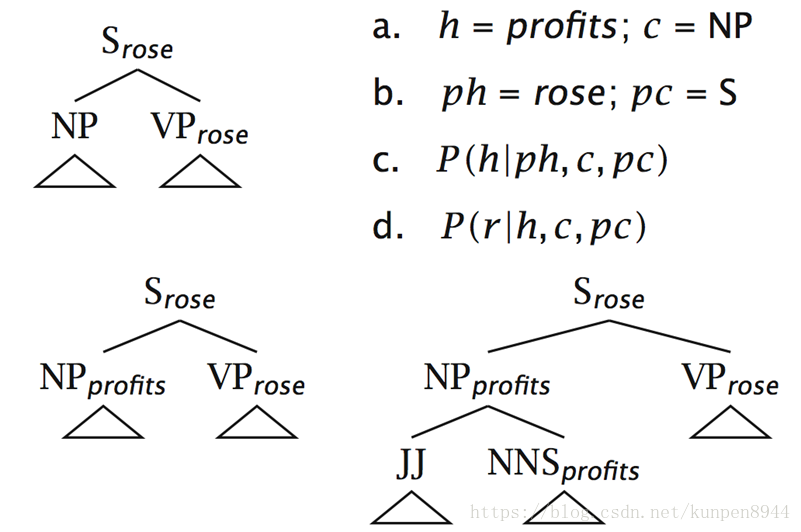
- 一个具体估计的例子:
- 1、已知类别S的中心词是rose,由NP和VP构成,VP的中心词是rose,求NP的中心词。h表示目前节点的单词,这里是profits;c表示目前节点的类别,这里是NP;ph表示目前的节点的父节点的单词,是rose;pc是目前节点的父节点的类别,这里是S。对于NP的中心词的计算是:从可能的中心词中找到条件概率最大的那个argmaxP(h| ph,c,pc)=profit
- 2、已知类别S的中心词是rose,由NP和VP构成,NP的中心词是profit,求接下来NP的构成规则。找到argmaxP(r| h,c,pc)。
- 当估计根节点的单词和接下来的构成规则时,概率条件中需要去掉父节点的信息。
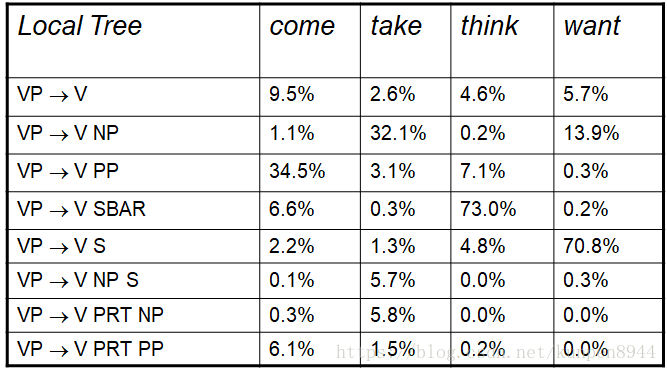
- 词汇化PCFG会明显差异化概率
- 基于不同动词的动词完全框架概率。
- 双词汇(bilexical)概率,在加入的条件变多以后概率明显提升。
- 基于不同动词的动词完全框架概率。
- Charniak线性插值法
- 插值存在的原因是直接计算的条件概率是非常稀疏的,所以Charniak提出了一种线性插值的方法。公式如下:
- 其中,λ是以判别模型的方法确定的;C(ph)表示父节点单词的语义(semantic)类型。
- 这种方法能帮助我们在没有充足的数据的时候,进行数据平滑。比如出现的下图第一列的情况,P(h|ph,c,pc)估计为0时。
- 插值存在的原因是直接计算的条件概率是非常稀疏的,所以Charniak提出了一种线性插值的方法。公式如下:

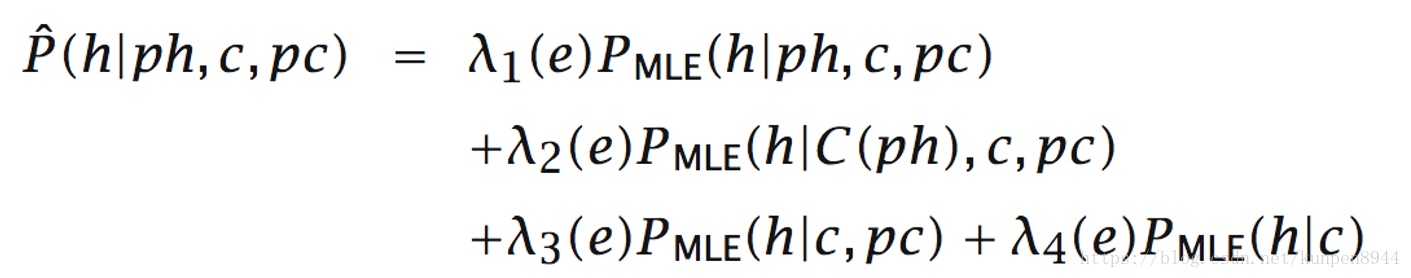
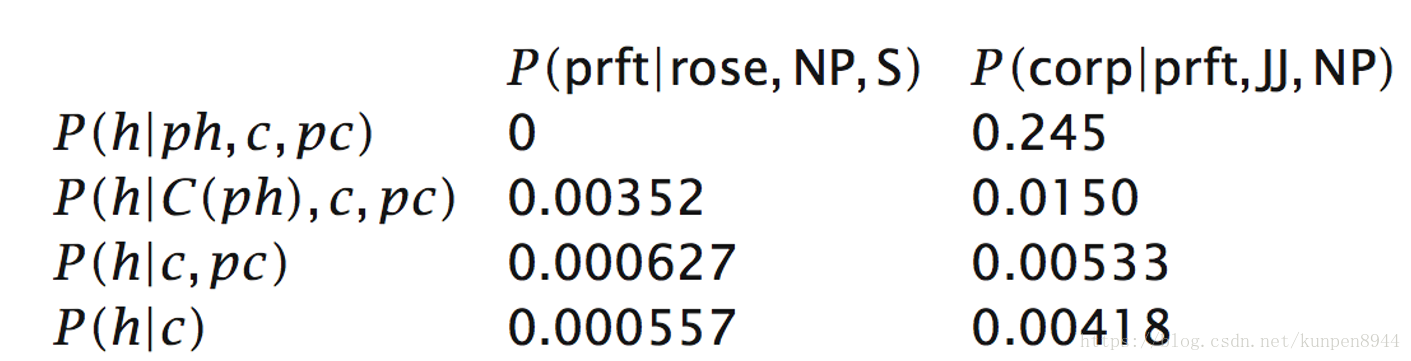
三、PCFG的独立假设
- PCFG也就是上下文无关文法的暗含假设就是独立假设:在任意节点,当给定该节点的类型之后,该节点子树内部的概率与子树外部的概率相互独立。
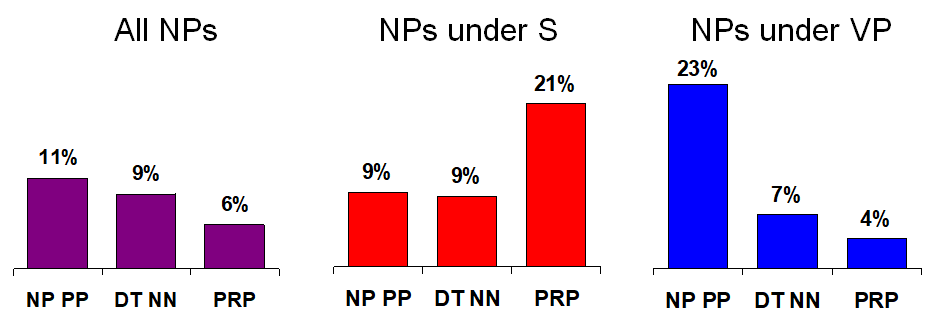
- 独立假设存在导致的一个问题是:在实际情况中很多时候父节点和其子节点的子节点是有很强的相关性的。举例而言,下图的第一个图表示的是单纯分裂一个NP节点的时候,它的左右子节点的可能性百分比。第二个图是当已知这个节点是在父节点下的NP节点的时候的百分比。第二个图是当已知这个节点的父节点是S时的百分比。第三个图是当已知这个节点的父节点是VP时的百分比,可以看出三者的百分比是完全不同的。
- 解决独立假设太强的问题的一个方法是状态分裂(state spliting)。也就是在标注单词类别的时候加上父节点的类别。但是会导致的问题是:造成特征稀疏。
四、非词汇化PCFGs
1、什么是非词汇化句法分析?
- 非词汇化句法分析区别于词汇化句法分析,我们使用的规则不会涉及到具体的单词。
- 比如NP-stocks就不算非词汇化句法结构,NP^S -CC就是词汇化句法分析
- 还有一些语言学中常用的功能词也能作为一种规则,比如VB-have,SBAR-if/whether
- 总结而言,我们使用的不是词汇层面的特征,而是基础的语法层面的特征,比如动词的形式,是否是助动词等等
2、基于实证的研究
- 实证材料:语料库是Penn treebank WSJ;分成测试集、训练集和发展集
- 评价标准:
- f1,precision, recall
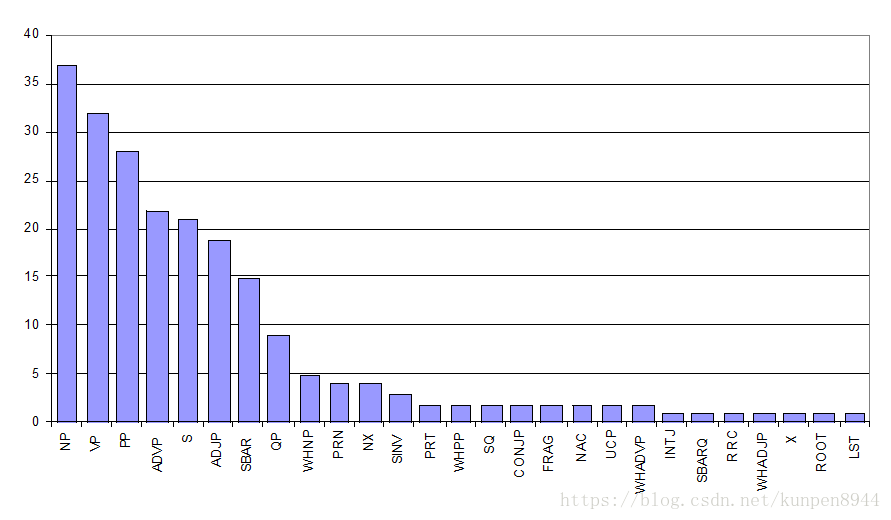
- 在语法中的象征(symbols)个数:(因为个数的增长会导致速度变慢和稀疏特征的问题)
- 完整/被动象征:NP,NP^S;
- 积极/不完整象征:拆分一对N规则导致的象征,比如@NP_NP_CC
- 状态分裂(state spliting)
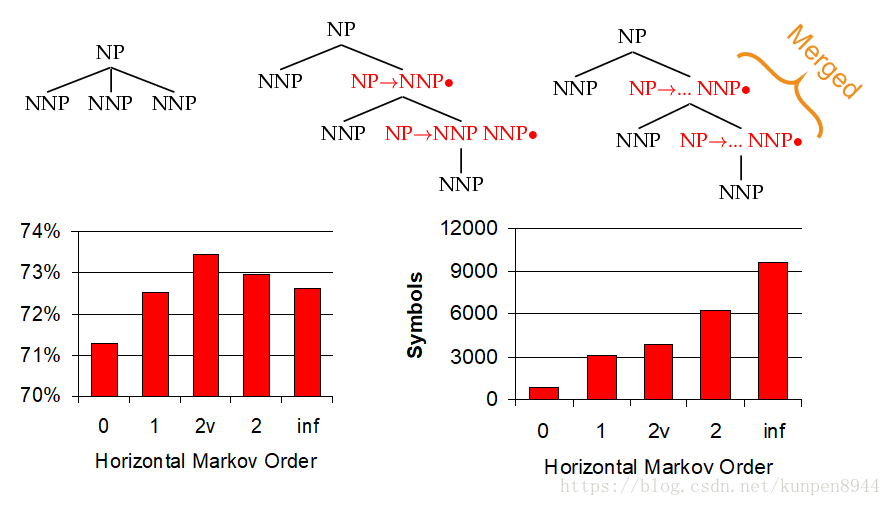
- 1、水平马尔可夫化(Horizontal Markovization):把前面单词的类别附加到现在的单词的类别上。见下图图表,横坐标1表示只附加一个前面的单词类别;横坐标2v表示对频率比较高的父节点类别附加两个前面的单词类别,剩下的附加一个;横坐标2表示附加两个前面的单词类别;inf表示不限制附加个数。可以看到在2v的时候预测比较正确,并且象征个数比较少。
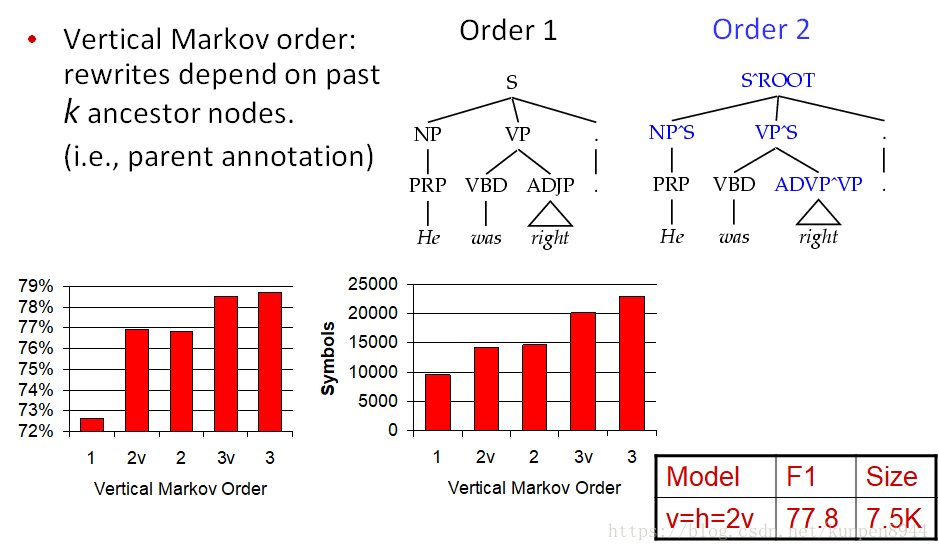
- 2、垂直马尔可夫化(Vertical Markovization):与水平类似,只不过附加的是祖先节点的类别。
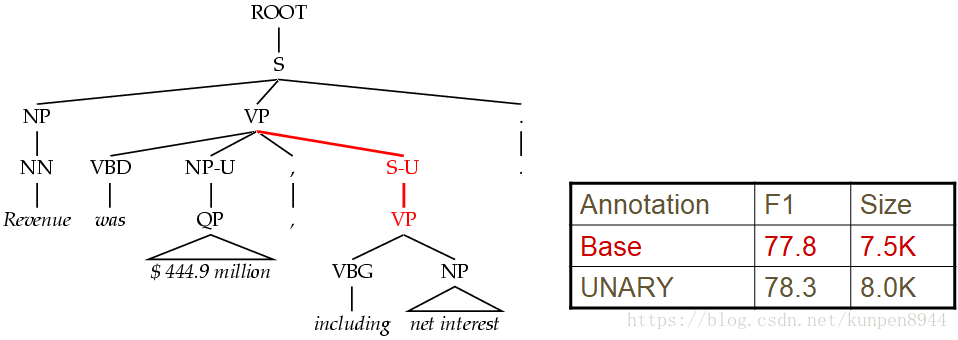
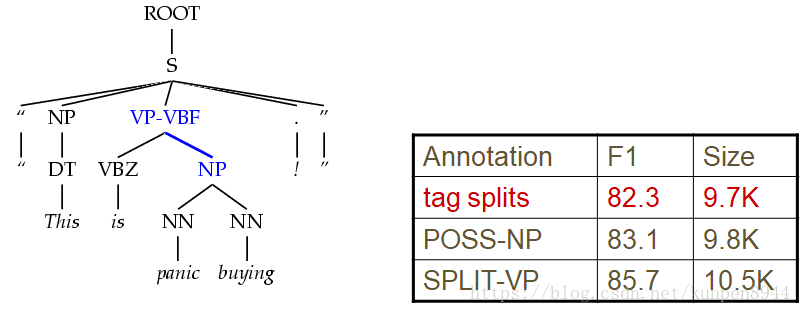
- 3、一对一规则分裂(Unary Splits):一对一规则经常出现,因此会导致一些错误,我们可以对一对一规则的类别进行标记-U。这一可以使得我们模型的f1提升1%
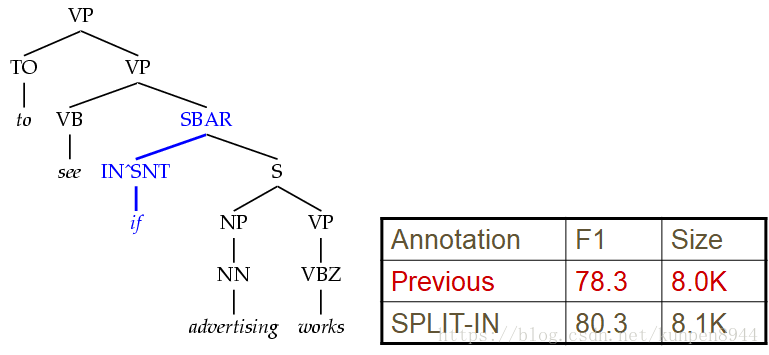
- 4、细化标注类型:Treebank 标注比较粗糙,很多不适合标注到一起,所以我们应该细化标注分类。比如把IN类型分成三类(that,whether,if| while after| in of to)
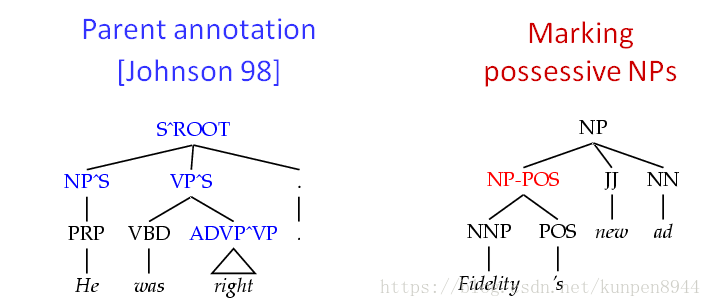
- 5、在词组类别上标注中心词的性质:比如Possessive NPs,Finite vs Infinite VPs,Lexical heads。
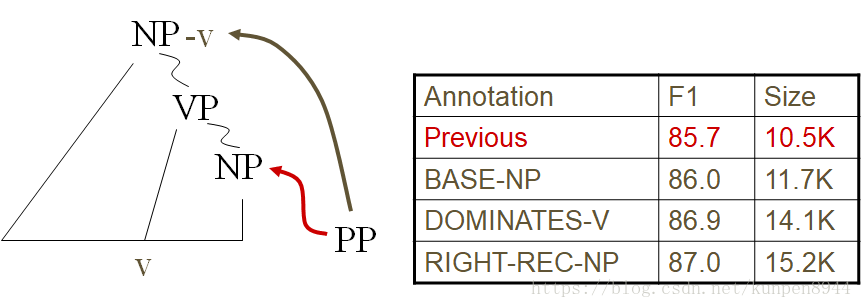
- 6、距离(distance)/递归(recursion)分裂:对附属(attachment)进行标记
- 如果词组里有动词的话对其进行标记
- 对有附属的名词词组(NP)进行标注
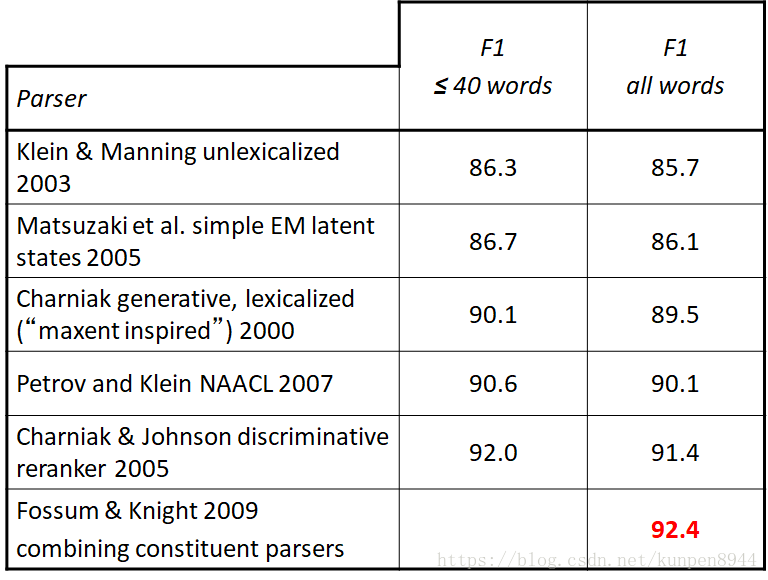
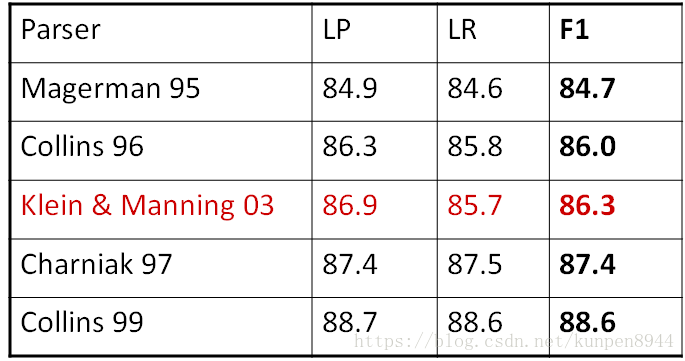
- 模型结果:86.7%的f1,效果比第一代词汇化句法分析好
- 1、水平马尔可夫化(Horizontal Markovization):把前面单词的类别附加到现在的单词的类别上。见下图图表,横坐标1表示只附加一个前面的单词类别;横坐标2v表示对频率比较高的父节点类别附加两个前面的单词类别,剩下的附加一个;横坐标2表示附加两个前面的单词类别;inf表示不限制附加个数。可以看到在2v的时候预测比较正确,并且象征个数比较少。
五、隐变量PCFGs
- 我们怎样自动找到合适的分裂象征?
- 利用一个隐变量算法,是EM算法,类似于向前的HMMs(forward-backward for HMMs),限制条件是限制条件是已经存在的树结构。
- 已知树结构、基本类别,利用这种算法来找分裂的子类别(以数字来标记)。可以预先设定一个基本类别分裂成子类别的数目,但是更好的方法是先把一个类别分成两个类别,如果这两个类别可以提升条件概率就进行分裂,如果不行就合并,然后继续分裂一直循环到满足停止条件。
- 模型结果
- 一些基本类型的隐变量学习结果
- 基本类型分裂成的子类型的数目图
- 模型结果比较
- 一些基本类型的隐变量学习结果