一、拼写纠正任务
1、拼写任务
- 发现拼写错误
- 纠正拼写错误
- 自动纠正
- 给出纠正建议(一个词)
- 给出纠正建议(一些词)
2、拼写错误的类型
- 拼写出来的不是单词(non-word spelling error):graffe→giraffe
- 拼写出来的是另一个单词
- 排字(Typographical )错误:three→there
- 认知错误(同音异形):too→two
3、拼写出来的不是单词的错误(non-word spelling error)
- 错误发现:预先有一个字典,任何不在字典中的单词就是错误,字典越大越好
- 错误纠正:
- 生成修正可选项:和错误相似的实际单词
- 选择最好的那个
- 最短加权编辑距离
- 最高噪音通道(noisy channel)概率
4、拼写出来是另一个单词(real word spelling error)
- 对每一个单词,w,生成一个候选集(candidate set)
- 找到发音相似的候选词
- 找到拼写相似的候选词
- 把w也放在候选集中
- 选择最好的候选词
- 噪音通道
- 分类
二、拼写的噪音通道(noisy channel)模型
1、噪音通道模型
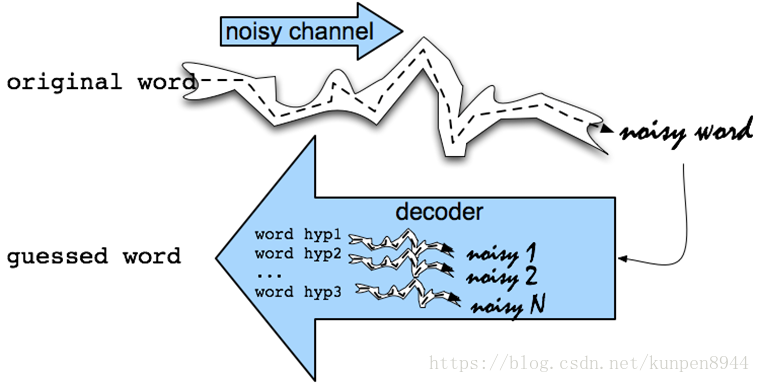
- 初始想法:一开始初始单词(original word)经过噪音通道(noisy channel)会生成噪音单词(noisy word)。我们通过对噪音单词的解码得到猜测的单词(guessed word)。
- 噪音通道模型:当我们拿到一个拼错的单词x的时候,我们可以利用下面的公式得到正确的w。
- P(w)表示语言模型
- P(x|w)表示通道模型(channel model)或者是错误模型(error model)
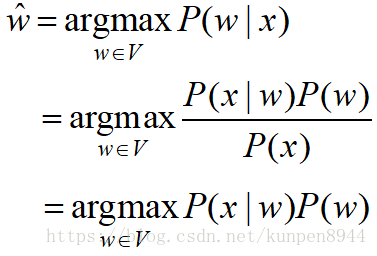
2、从拼写出来的不是单词的错误(non-word spelling error)开始
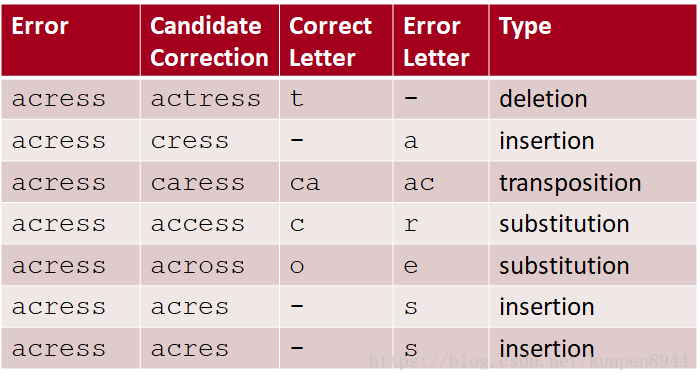
- 错误是:acress
- 候选词生成(candidate generation)
- 相似拼写的单词:找到最小的编辑距离
- 相似发音的单词:找到发音的最小的编辑距离
- 这里选取相似拼写来举例子
- 编辑距离:我们采取Damerau-Levenshtein编辑距离
- 对两个字符串而言,之间的基本编辑操作是:插入、删除、替换和两个相邻的字母的交换
- 以acress来举例子来看编辑操作
- 80%的错误都是编辑距离为1的错误
- 所有的错误都是编辑距离为1或者2的错误
- 同时也包含连字符-和空格的插入
- thisday→ this day
- inlaw→in-law
- 语言模型
- 包含任何我们之前学习的语言模型算法,包括一元、二元、三元以及stupid backoff(针对web规模的拼写纠正)
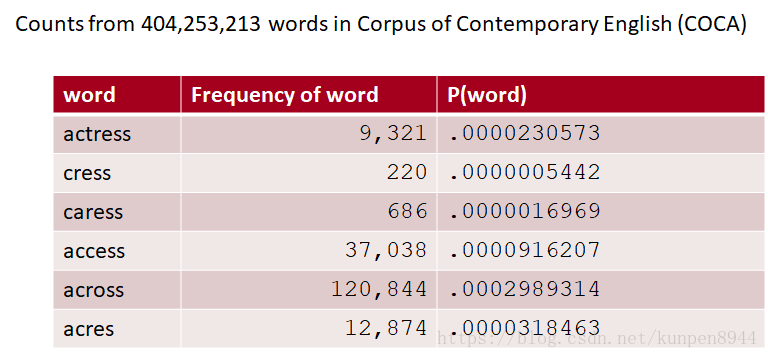
- 以acress的候选集举例,来看他们的语言模型
- 通道模型概率
- 又称错误(error model)模型概率,编辑(edit)概率
- 定义:
- 拼错的单词X=X1,X2,X3…Xm
- 纠正的单词w=w1,w2,w3…wm
- P(X|w)表示编辑概率
- 计算:混淆矩阵
- 计算公式
其中,
对这四种编辑公式,我们分别构造混淆矩阵,一共是四个混淆矩阵,形如下图
- 计算公式
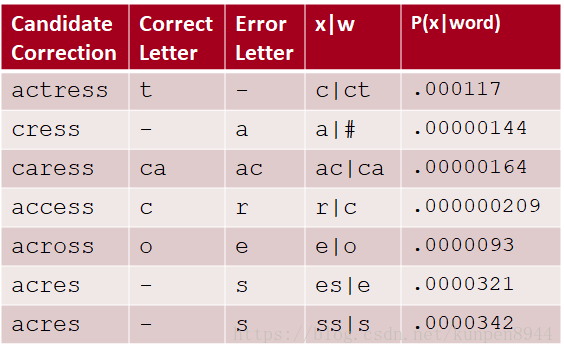
- 以acress举例,通道模型计算如下
- 以acress举例,噪音通道概率计算如下:
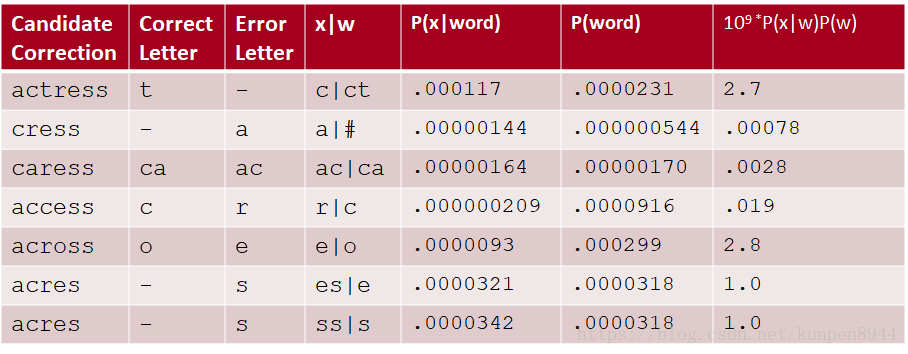
- 改进:使用二元语言模型
- 在大部分的情境下,二元模型会更准确
- 例子如下:
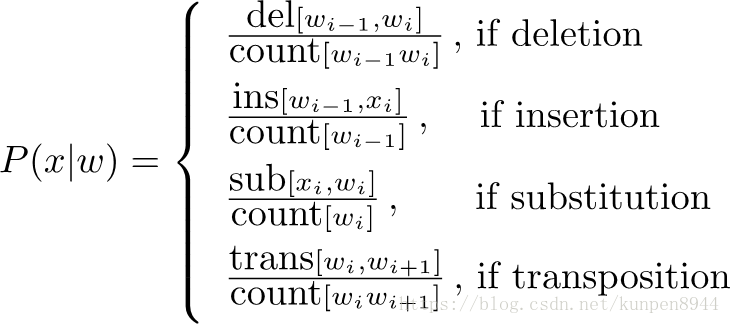



3、评估
我们可以利用一些拼写错误测试集进行评估

三、拼写出来是另一个单词的错误纠正(real-word spelling correction)
1、解决方案
- 对句子中的每一个单词
- 生成候选集,包含(单词本身、同音异形词,和原来的单词之差一个字母编辑的单词)
- 选择最好的候选(用噪音通道,或者分类)
2、公式描述
- 给定一个句子包含一系列单词w1,w2,w3,…,wn
- 对每个单词都生成一系列的候选词(candidate)
- 选择一系列的单词W使得P(W)最大
- 图解如下:
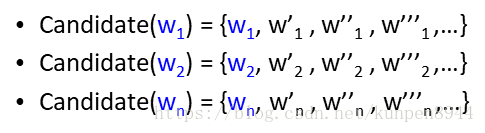
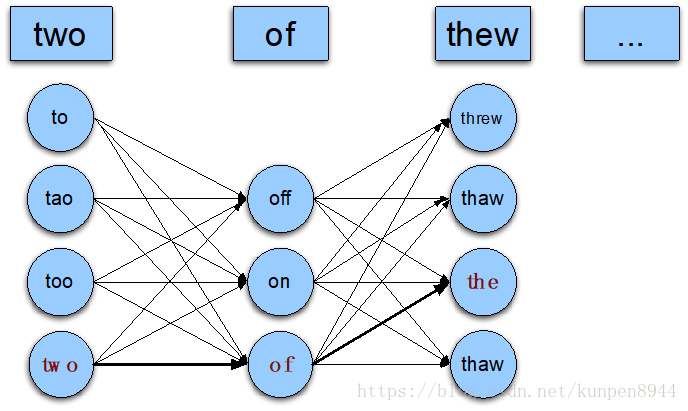
3、化简版:每个句子一个错误
- 假设句子里面只有一个单词出现了错误,只对一个单词进行纠正
- 分别计算纠正过的概率,选择概率最大的那个

4、如何确定概率
- 语言模型:一元、二元、等等
- 通道模型:和非单词拼写错误(non-word spelling correction)一样,除此之外加上没有发生错误的概率P(w|w)
- P(w|w)的计算
- P(w|w)的计算
- 一个计算的例子

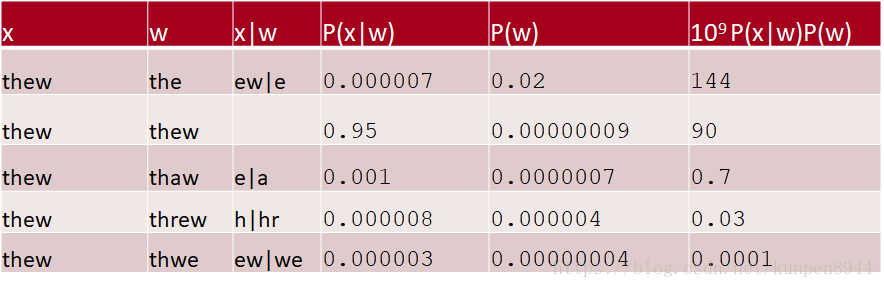
四、一些改进
1、人机交互的拼写问题
- 如果对纠正很有自信:自动纠正
- 次之,给出最好的纠正
- 次之,给出纠正列表
- 次之,示意出现了错误
2、噪音通道的改进
- 不应该直接将先验和错误的模型相乘,这样的理论基础是独立假设。但是实际上先验概率放在这里是不合适的。
- 所以,取而代之的公式应该是这样:
- 我们可以从一个发展测试集(development test set)来学习lamdba
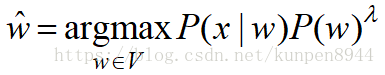
3、语音(phonetic)错误模型

4、对通道模型的提升


