1、什么是问答系统
-
问答系统是最早的NLP任务,根据问题的依存关系,找到适合的依存关系的回答。

-
在现代系统中问题被分为两类

事实问题的回答一般都是一个简单的词组或者是命名实体

-
两种问答系统的范式
- 基于信息检索的路径:TREC; IBM Watson; Google
- 基于知识的混杂路径:IBM Watson; Apple Siri; Wolfram Alpha; True Knowledge Evi
-
基于信息检索的事实问题回答流程
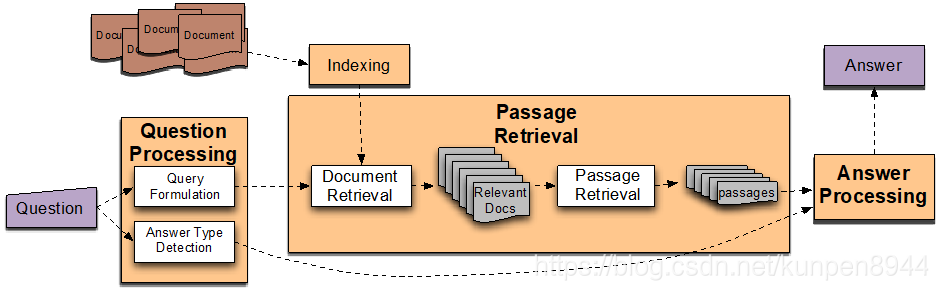
- 问题处理(question processing):研究问题的类型、回答的类型、关注点和关系;生成送入搜索引擎的请求(query)
- 段落检索(passage retrieval):检索排名文档,将其打散成适合的段落再排名
- 回答处理(answer processing):抽取可能的答案,对这些答案排名
-
基于知识的路径(Siri)
- 建立请求的语义表征:时间、日期、地点、实体以及数量等
- 基于这些语义,向结构化的数据以及资源映射请求:地理数据、百科词典(Wikipedia)等等
-
混合路径(IBM Watson)
- 建立一个请求的浅层的语义表征
- 利用信息检索技术生成一些可能的回答
- 利用更丰富的知识来源来对每个可能的回答打分
二、回答类型与请求生成
1、问题处理:从问题中抽取五个元素
 一个对应的例子:
一个对应的例子:

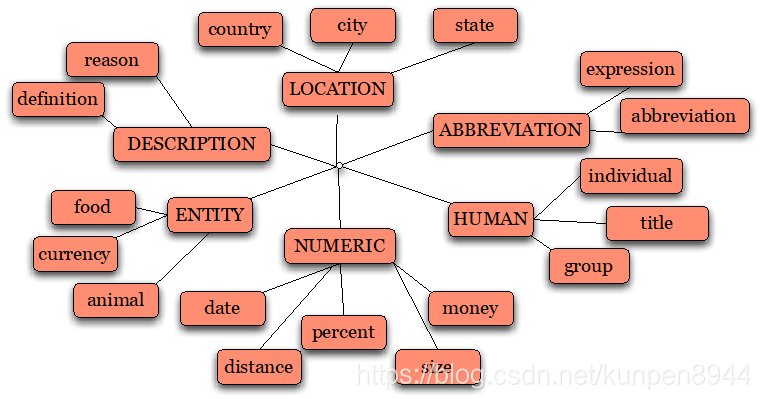
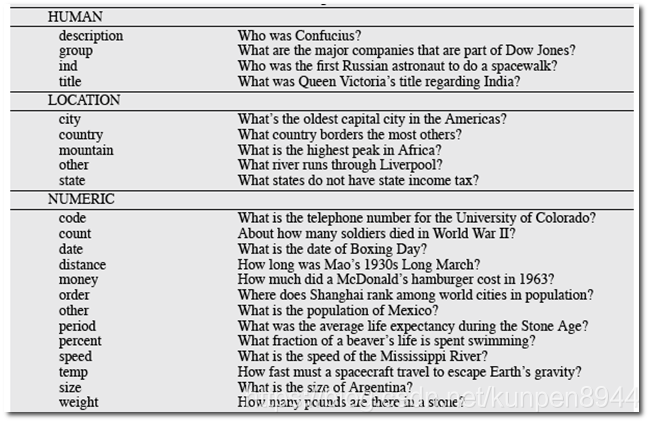
2、回答类型分类法
- Li & Roth分类:分成6个大类,50个小类

- Jeopardy回答类型:20000的Jeopardy问题样本,2500回答类型。最多频率的200回答类型只覆盖了小于50%的数据;下面是40个最多频率的回答类型:he, country, city, man, film, state, she, author, group, here, company, president, capital, star, novel, character, woman, river, island, king, song, part, series, sport, singer, actor, play, team, show, actress, animal, presidential, composer, musical, nation,book, title, leader, game
3、回答类型检测
- 回答类型检测有三种方法:人工规则、机器学习和混合方法
- 人工规则:
- 基于一些特殊的例子:Who {is|was|are|were} PERSON,PERSON (YEAR – YEAR)
- 其他规则则会使用问题的中心词:wh-单词后面的第一个名词词组的中心词。
- Which city in China has the largest number of foreign financial companies?
- What is the state flower of California?
- 机器学习
- 定义问题类型的分类系统
- 给训练数据标注问题类型
- 给每个问题分类训练分类器,训练特征可以是:问题中的单词和词组、词性标注、句法特征(中心词)、命名实体以及语义相关的单词,还可以有一些其他的人工规则。
4、请求生成:关键词抽取
- 关键词抽取的算法:基于下面的规则对关键词进行抽取

 对抽取出来的单词,按照规则排名进行检索,直到检索结果足够多为止。
对抽取出来的单词,按照规则排名进行检索,直到检索结果足够多为止。
三、段落检索与回答抽取
1、段落抽取
- 步骤
- 第一步:利用信息检索引擎抽取使用了请求项的文档
- 第二步:把文档分成更小的单元,比如段落
- 第三步:段落排名:利用回答类型来进行段落再排名
- 段落排名使用的特征(基于规则的分类或者是机器学习的分类)
-在段落中,正确类型的命名实体的数量- 在段落中,请求单词(query word)的数量
- 在段落中,问题N元组的数量
- 在段落中,请求关键词的邻近程度
- 问题单词的最长序列
- 包含该段落的文档排名
2、回答抽取
- 对段落进行一个回答类型的命名实体标记,比如回答类型是城市的话,标记就需要对城市类型的命名实体进行标记
- 然后返回正确回答类型的字符串
 - 如果段落中有很多个正确的回答类型的字符串,我们可以使用机器学习的方法,对这些字符串进行排名。下面是一些可以使用的特征
- 如果段落中有很多个正确的回答类型的字符串,我们可以使用机器学习的方法,对这些字符串进行排名。下面是一些可以使用的特征

- 回答抽取评估:
- 在IBM Watson中,会对答案从50多个方面进行打分(非结构化文本,半结构化文本,三元组)。
- 一般问答体系会返回的不是一个答案,而是一系列排名的答案。对多个答案进行度量的方法是使用平均倒数排名,即对第一个正确的答案的排名取倒数。对所有的请求计算,排名倒数的平均数。
四、在问答体系中的知识应用
1、关系抽取

2、时间逻辑

3、地理信息知识(包含、方向性、边界)

4、上下文和谈话,如siri
