一、介绍
1、依存句法
- 依存句法假设:句法结构包含相互之间是双边不对称关系的词典(lexical)元素,这种不对称的关系成为依存(dependency),在图中的表现是单向箭头。
- 箭头通常还会打上这种语法关系的名字(主语,前置宾语等等)
- 箭头一边连接中心词head (governor, superior, regent),一边则连接依存词dependent (modifier, inferior, subordinate)。
- 这种关系表现为树结构
2、词组结构(phrase structure)与依存结构之间的关系
- 依存语法有一个中心词的概念。但是CFG没有。
- 但是在现代的语言理论以及所有的现代统计句法分析中,确实有一个手工定义的“中心词规则”。
- 名词词组(NP)的中心词是名词/数词/形容词
- 动词词组(VP)的中心词是动词…
- “中心词规则”可以帮助我们从上下文无关文法句法(CFG)中抽取依存句法
- 而从闭合的依存句法中我们亦可以得到词组结构的成分(constituency),但是同一个单词的所有依存词都必须在同一层中,这可能会导致词组结构和依存结构结果会略有不同。
3、四种依存分析方法

4、依存分析的信息来源
- 双单词关联:比如issues→the
- 依存距离:依存词和中心词的距离,大部分时候是相邻的两个词
- 中间元素:一般依存关系之间不太可能会出现动词或者标点
- 中心词的价:一般,中心词的左边/右边有多少个依存。
二、贪婪转换句法分析(Greedy Transition-Based Parsing)
1、MaltPaser
- 这是一种简单形式的判别依存句法分析。这种句法分析涉及到一系列自底向上的行动,比如移动(shift)和移除(reduce)。
- 这种分析句法含有:
- 一个堆栈 stack σ,从ROOT开始从顶向右存储
- 一个缓冲区 buffer β,从输入的句子开始从头到左
- 一系列依存关系(dependency arcs),一开始是空的
- 一系列操作(action)
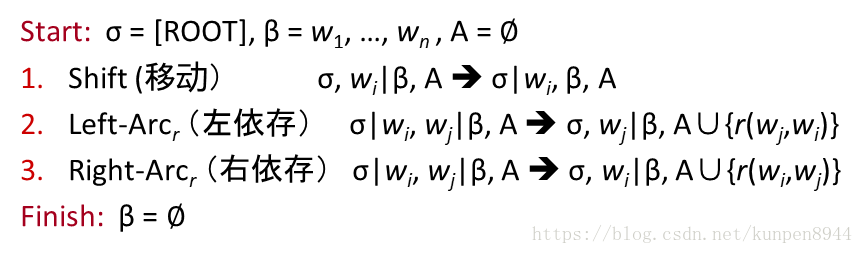
- 用字母语言来表示
- 初始状态:σ=[ROOT],β=w1,…,wn, A=空集
- 基本的转换依存句法分析(Basic transition-based dependency parser)
- “arc-eager”依存句法分析:上面基本的句法分析方法在处理某些依存结构的时候会存在一些问题,因此对操作进行了改进。
- 例子:
- 如何得知下一步操作是什么?
- 利用一个判别分类模型来帮助我们判断下一步需要做的操作是什么。可以是SVM,也可以是最大熵模型。
- 如果这是一个不标记依存类别的分类,那么我们的判别模型就是一个四分类问题,如果这是一个标记依存类别的分类问题,那么总的分类类别就是|R|*2+2,其中|R|表示依存类别的个数。
- 判别模型的特征一般是:栈顶的单词以及对应的词性;在缓冲区的第一个单词以及词性等等
- 这是一个贪婪的算法,作为改进的话,可以做一些束搜索(beam search)
- 利用一个判别分类模型来帮助我们判断下一步需要做的操作是什么。可以是SVM,也可以是最大熵模型。
- 这种语法分类方法的正确率只比最好的词汇化PCFGs低了一点点,但它是一个线性时间复杂度的算法,计算起来很快。


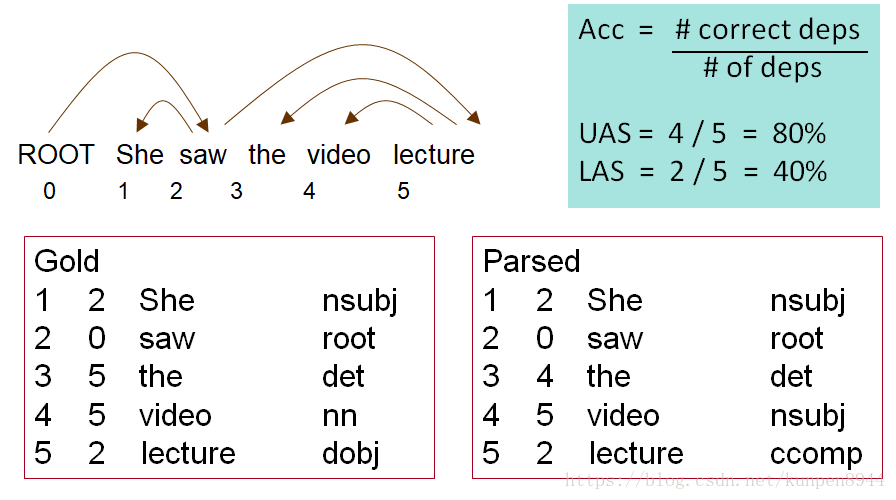
2、依存分析的评价以及表现
- 对每个单词标上序号,列出每个依存关系对应的序号和类型。分为两种正确率的计算
- UAS:不考虑依存关系的类型,只考虑依存关系的对应单词是否正确
- LAS:同时考虑依存关系的对应单词以及依存关系类型
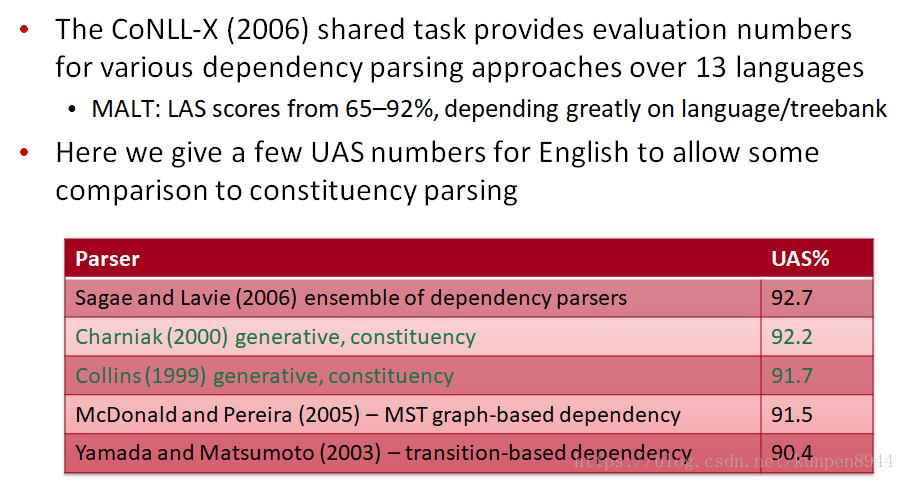
- 依存模型的效果
3、投射问题
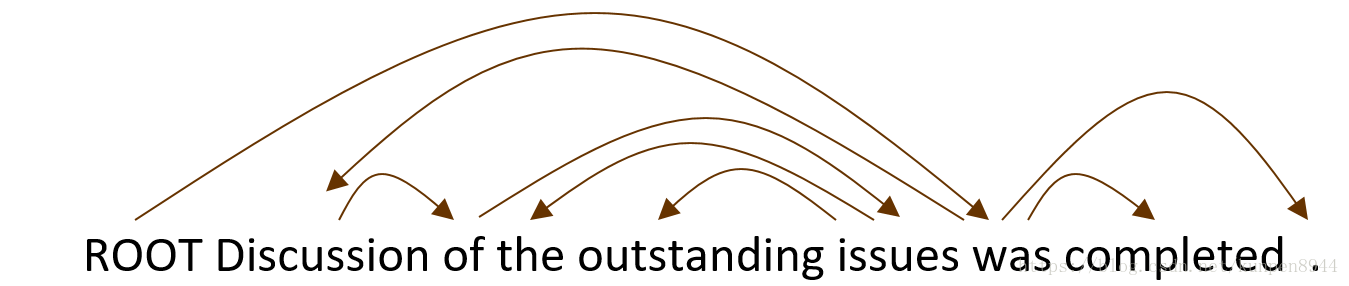
- 一个基于带中心词的CFG树,它的依存关系必须是投射性的(projective)。所谓的投射性指的是当我们在单词的上方用带箭头的弧度画出单词之间的依存关系的时候,这些弧度是不会相互交叉的。交叉情况如下图。
- 但是一般依存理论是允许非投射性(non-projective)的情况出现的:对于某些结构而言,如果不用非投射性来研究的话,我们是无法理解其语义的。
- 我们上面展示的“arc-eager”算法只能建立投射性(non-projective)树,如果我们想要处理非投射性问题的话,这里有一些解决方法。
- 直接默认不存在非投射性的依存关系,这种关系在英语里面确实很少存在。
- 使用一种允许投射性表示的依存框架
- 在进行投射性语法分析算法之前,先做一步预处理,找出非投射性依存并处理
- 在依存分析的算法中加入新的操作,以处理一些比较常见的非投射性依存
- 使用那些没有对投射性有限制的句法分析机制,比如基于图的MSTParser

三、利用依存关系来进行关系抽取
- 依存路径可以帮助我们定义蛋白质之间的交互关系
- 斯坦福依存(Stanford dependency)是一个可以实现这功能的软件。其假设所有的依存关系都是投射性的。
- 构建依存树:斯坦福依存假设所有的依存关系都是投射性的。因此我们可以用处理过的中心词组结构(Penn Treebank syntax)来构建依存关系,也可以直接使用依存分析,像上一节提到的MaltParser。
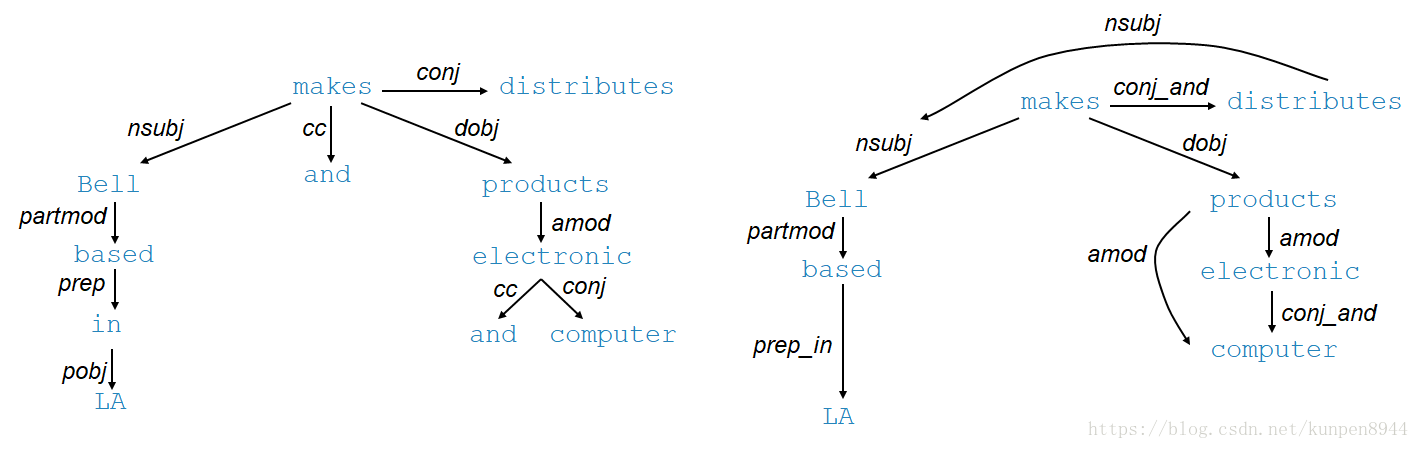
- 在构建了依存树之后,我们进行一些图的调整来帮助模型可以更好地进行关系抽取。如下图,左边是原来的依存树,右边是调整后的依存关系图。
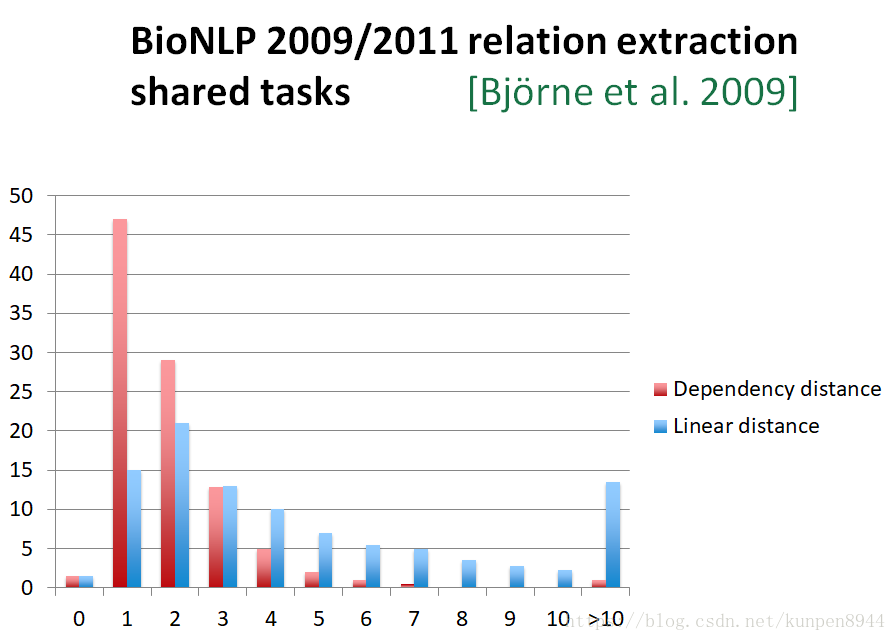
- 从实证角度来看:利用依存分析进行关系抽取的优势是,依存分析下关系词的距离要比直接进行关系抽取的单词直接距离来得近。下图横轴表示单词距离,红色的是依存距离,蓝色的是线性距离。纵轴表示频率。可以看到单词之间的依存距离比线性距离更多的集中在短距离的区域中。