第一章:计算机视觉梗概
第二章:图像分类途径

python+Numpy简单教程:
http://cs231n.github.io/python-numpy-tutorial/
Image Classification: A core task in Computer Vision(核心任务)
————计算机可以识别图像里面的内容。
The Problem: Semantic Gap(计算机眼里的图片是一系列像素的数值,如何解决语义隔阂?)
Challenges: Viewpoint variation(视觉变化,计算机看到的图像又是不同的,十分复杂)
- Challenges: Illumination(光线?)
Challenges: Deformation(视觉中物体的姿态?)
Challenges: Occlusion(产生遮挡?)
Challenges: Background Clutter(视觉中的物体和背景非常相似时又该如何识别???)
Challenges: Intraclass variation(物种问题??物体多物种)
An image classifier(分类器):是一个函数,参数是一张image输出是图片的label
下面是关于分类器的一些尝试:
1.寻找图片里面元素的边界,因为一个边界往往是像素值相同,所以可以描绘出边界勾勒出物体的轮廓,寻找一些角。
2.数据驱动的方式
收集一些有标签图片作为数据集——>用这个数据集来训练分类器(机器学习的办法)——>评估这个分类器(新的图像)train和predict两个函数
First classifier: Nearest Neighbor(最近邻)
train函数:输入参数:image+label 机器学习方法 返回model
predict函数:输入model还有新的测试image 返回label
一个核心思想应该就是会有大量的训练数据集,训练完毕来测试新数据的时候,会和之前的训练数据集进行比较,然后label就是最近邻居的label。
那么问题来了,如何比较图像呢?也就是:
Distance Metric(距离度量) to compare images:
用的是:L1距离——曼哈顿距离
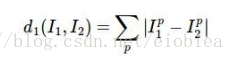
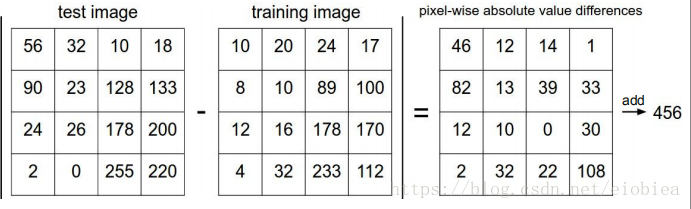
缺点:训练很快,预测很慢,不符合我们的要求。
一张图表示缺点:只有一个最近邻决定的缺点
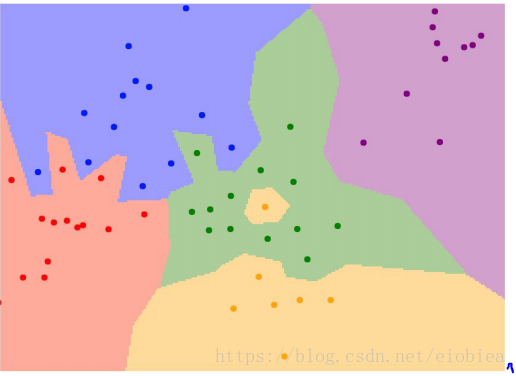
边界不平滑,起伏很大,会导致效果不好。
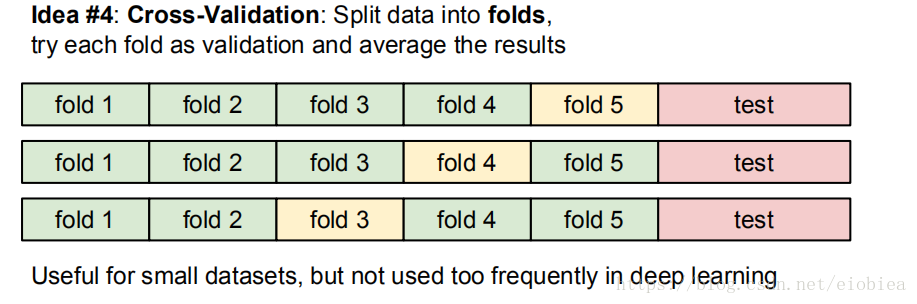
所以采用K-Nearest Neighbors
不单单和一个最近邻来进行比较,而是K个最近邻投票决定
K-Nearest Neighbors: Distance Metric
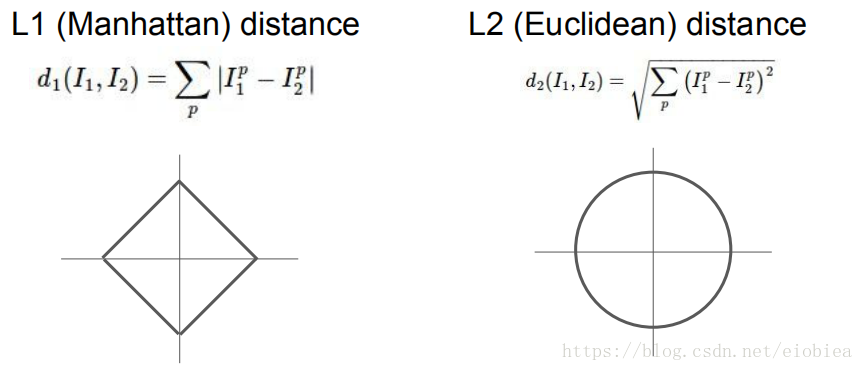
没办法说L1L2哪一个比较好看实际来决定。这种参数叫做超参数(K L1 L2)

关于超参数的选择:
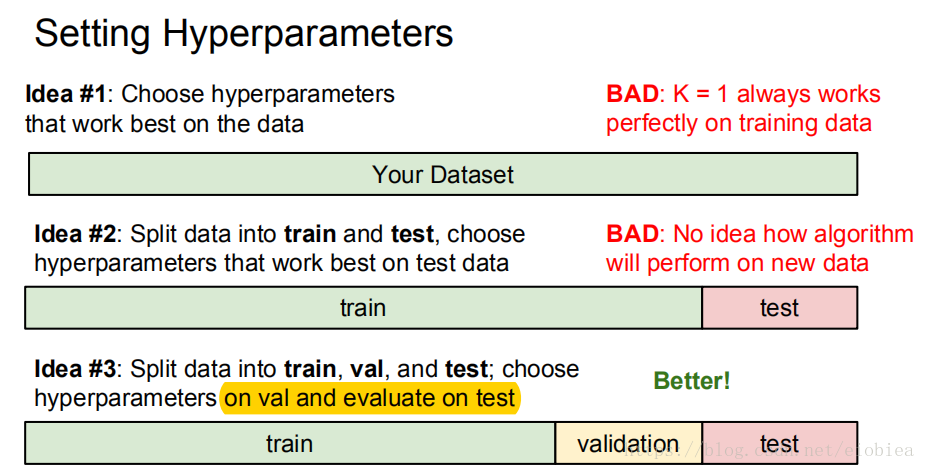
k-Nearest Neighbor on images never used.
- Very slow at test time
- Distance metrics on pixels are not informative(提供信息)
- Curse of dimensionality(维度灾难)
线性分类器:
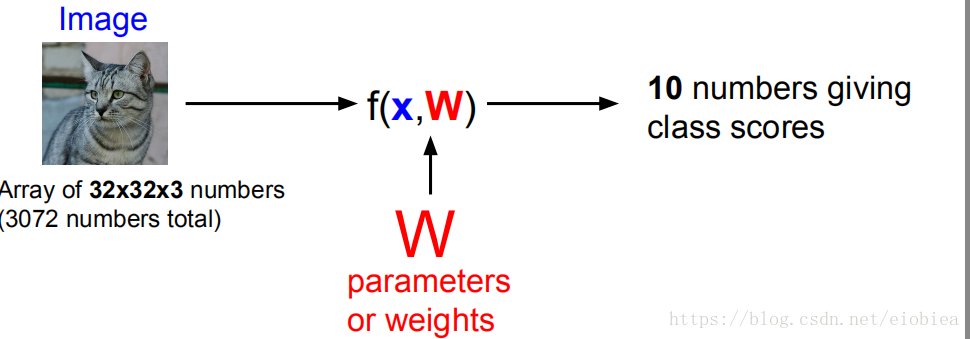
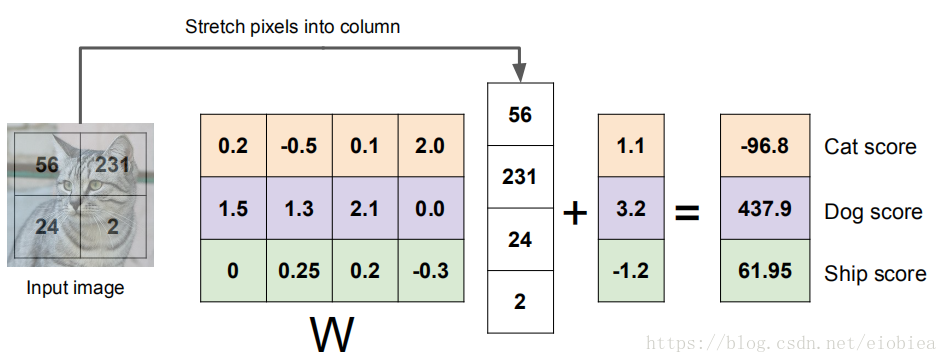
线性分类器的分类原理——有点类似于线性函数对于区域的划分
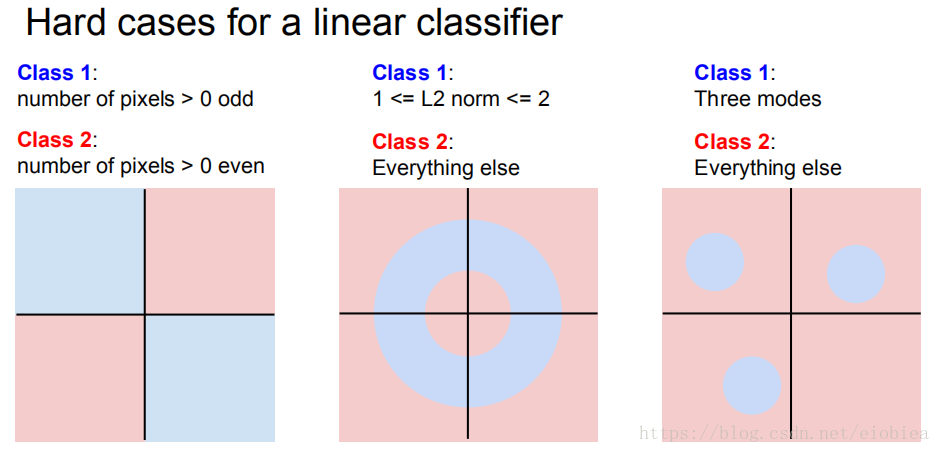
一些不适用线性分类器的情况——很难划分
第三章:损失函数和优化
一.损失函数:当前分类器的好坏
如现在有一个数据集:
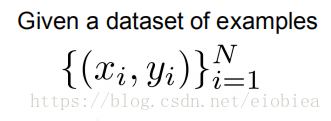
有N项,X是图像,Y是label
损失函数是:
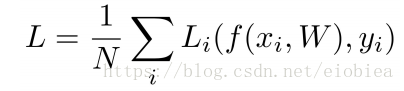
Multiclass SVM loss::是一个Hinge loss(合页损失函数)


不会唯一的,因为是一个倍数的问题。
数据损失项+回归项:
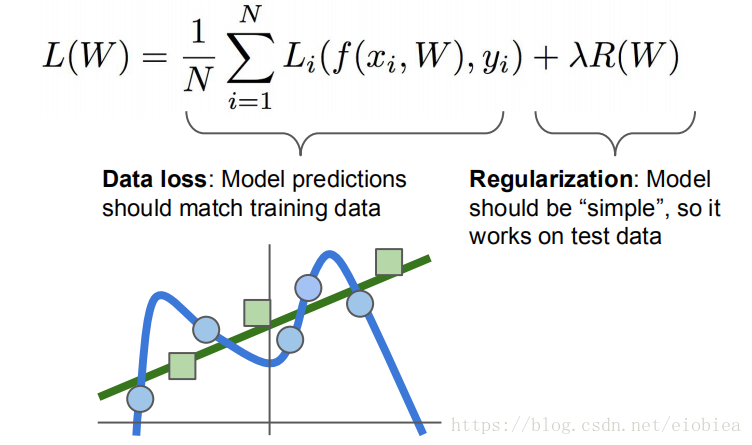
超级参数:归一化强度

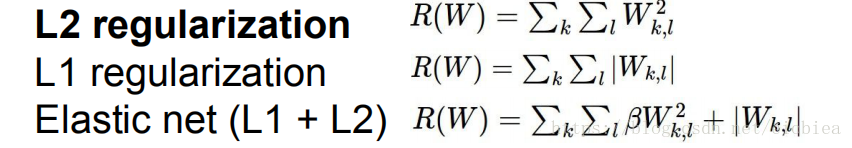

Softmax Classifier Multinomial Logistic Regression
分数转化为一个概率性的东西。

二.优化
一个人走下山的一个正确的 路径:
Strategy #1: A first very bad idea solution: Random search
Strategy #2: Follow the slope
一维是微分,多维是梯度(偏微分)。
Gradient Descent:梯度下降Stochastic Gradient Descent (SGD)