数据挖掘-支持向量机初次探讨
浅谈支持向量机
支持向量机方法又称为支撑向量机,其本质是一种基于二分类的分类模型。最初使用这种模型是为了解决线性的分类问题,即线性的支持向量机;后来引入了核函数进行处理,使得支持向量机可以通过提升维度的手段将线性不可分的问题转化为线性可分,即非线性的支持向量机。
我们从最简单的二分类问题入手,假设有一群人的身高数据,这群人分为两类,第一类是一些篮球运动员的身高,记录这些篮球运动员的标签为+1,即正例。第二类是一些小学一年级的小朋友身高,记录这些小朋友的标签为-1,即负例。我们将这些数据混在一起,同时假设这些数据是线性可分的。下图通过圆圈代表正例,三角形代表负例。
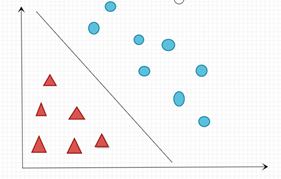
通过这些数据,可以学习得到一个分割,这个分割是在无数个可分割的超平面中的一个分割,同时这个分割的误分类是最小的,即这个分割是最准的,那么这个分割就是最大间隔分离超平面。
上述的公式代表的是分离超平面的表达式,即可以理解为图中的那条直线,因为在二维平面中,分离的超平面是一条直线;同理在三维空间中,分离的超平面是一张平面;在维数更高的空间中,这种超平面只能通过关系表达式进行表达,无法被画出。
同时,基于上述公式,我们通过符号函数sgn进行映射,将分类的决策函数构建为:
当上述公式括号内的值大于0时,决策函数的值为+1,当上述公式括号内的值小于0时,决策函数的值为-1。从直观的角度来看,在图中,直线右边的所有的蓝色圈圈都是决策函数值为+1,即代表正例;直线左边的所有红色三角形都是决策函数值为-1,即代表负例。
在进一步的观察后,以正例为例,我们发现图中的圆圈距离直线是有远近的,即可以这样理解,篮球运动员中,中锋的身高较高,离超平面的距离较远,而后卫的身高不太高,离超平面的距离较近。当图中负例数据换成是足球运动员的身高的时候,篮球后卫的身高很难被区分出来。这种情况下,我们需要一个指标去衡量数据距离超平面距离远近的变量,即函数间隔,为下式:
但是这个公式其实是有漏洞的,当参数变为原来的3倍的时候,超平面是不变的,但是函数间隔的值会变为原来的3倍。因此我们引出一个几何间隔,即通过参数的范数对参数做限制,公式如下:
通过这个公式可以很好的反映出数据距离超平面的距离,同时不会受到参数成比例变动的影响。基于这个指标,后续文章还会继续讨论间隔最大化的表达式与优化问题,此处先暂时不讨论。
总的来说,支持向量机的方法是比较经典的一种机器学习方法,它可以通过数学公式进行推出,并且可解释性较强,同时预测效果较为准确,但是当数据较难分割的时候,该方法通常会难以进行处理。
