数据挖掘-探讨Bagging方法
浅谈装袋方法
在传统分类问题中,我们通常使用基本的分类器去得到模型,比如朴素贝叶斯模型、决策树方法、logistic模型等。但这些基本的分类器的预测正确率都是较为一般的,在处理实际问题中,这些模型的准确率可能在70%~85%之间。如果还想进一步提高预测准确率的话,可以选择使用深度学习的神经网络预测或是集成学习的方法进行预测。
在某些问题上,如图像分类问题、语音识别问题、自然语言问题上,深度学习中各类神经网络要强于普通的机器学习方法,也强于集成学习的方法。本人认为在这些涉及到感知的分类问题上,神经网络由于本身对数据的特征抽取是非常细微的,所以能够观察到人类无法观测到的差异和特征;同时由于神经网络本身是模仿人类大脑神经元的结构,所以对这些基于感知的分类问题上,效果非常好。
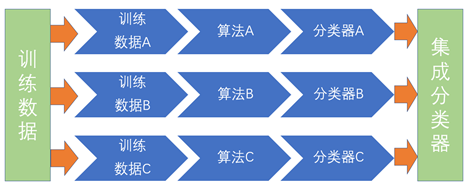
我们今天要谈的Bagging方法,是属于集成学习的一种。上一次的文章中谈到的提升方法也是集成学习的一种。Bagging方法又名装袋方法,它的本质上是一种学习策略,而不是具体的分类模型。即这种Bagging方法的学习策略是把多个简单的分类器进行组合,通过数据训练得到分类器后,在预测时采用投票的方式进行预测。
在某种程度上,Bagging方法是在竞赛中经常被使用的,因为它的这种组合的学习策略是可以防止过拟合的,并在一定程度上提高预测的准确率。这种学习策略本质上不是一种数学模型或是统计理论,所以这种方法在期刊论文中的研究较少,大部分人是在实战中用到该策略。
其实最典型的Bagging模型就是随机森林模型,随机森林模型是基于决策树模型的一种延伸,因为它的本质是多棵决策树进行组合。它的训练步骤主要是三步:
1、从总数据中选出n组样本作为训练数据,从总特征中选出x个特征作为某棵决策树的特征。
2、将n组样本对应的x个特征进行训练,得到一棵决策树。
3、重复步骤1和步骤2,得到K棵决策树后,训练结束。
在使用时,只需将K棵决策树进行组合,并通过投票机制得到最终的预测结果。其实在实际的比赛中,随机森林模型是经常被使用的,它的优势主要是三个。第一,随机森林模型可以防止噪声数据对模型的干扰,即健壮性较强,模型较为稳定。第二,随机森林模型可以防止过拟合。第三,随机森林模型不需要进行人工筛选特征,即可以处理高维特征的问题。基于上述三个优点,随机森林模型在一些问题中,它的预测能力和稳健性甚至超过一些神经网络模型。所以随机森林模型是较为经典的数据挖掘模型,初学者应该熟悉这种方法的原理。
总的来说,Bagging的学习方法是一种非常经典并且十分实用的机器学习方法,初学者应该熟悉并掌握,特别是这种策略对应的经典模型(随机森林模型)。并且这种模型在分布式系统十分适用,在处理大数据的情况下会具有一定的优势。
