数据挖掘-Stacking策略简介
浅谈Stacking方法
在之前的文章里,我们谈过一些模型融合的策略,比如Bagging策略、Boosting策略等,并且它们都有一些代表性的方法,比如Bagging策略里最有代表性的方法是RF随机森林,而Boosting策略里面最有代表性的方法是GBDT梯度提升树。那么本次要讨论的Stacking方法也是一种模型融合的策略,只不过它不是简单的串行提升或者并行投票,而是采用堆叠的形式进行各个模型的融合,Stacking方法的核心思路就是把一些简单的模型先进行训练,然后拿预测结果作为特征再使用比较强的模型再次训练,最终得到一个多模型堆叠融合的大模型,并且这个大模型的预测准确率和稳健性比一般模型要好。
在传统的预测分类的问题上,比如Kaggle比赛里非常经典的训练赛Titanic问题,我们可以使用一些非常基本并且经典的模型。比如支持向量机、朴素贝叶斯、决策树等模型,这些模型的准确率可能就在60%到90%之间,但是如果想再进一步提升模型的预测准确率,则需要使用一些模型融合的策略,比如我们本次文章所谈到的Stacking策略。Stacking方法的大致步骤如下:
1)选择第一阶段和第二阶段的模型,并且初始化相关的模型参数,同时将数据分割成K份,采用交叉验证方法对数据进行标记,每次测试集是1份,而训练集是K-1份。以这样的方法对把数据克隆K份。
2)对于第一阶段的模型,把步骤1里面的数据输入模型进行训练,得到K个模型的预测结果,记录K个预测结果;然后继续拿这些模型去预测它们自己的测试集,得到测试结果的预测值,并且取预测平均值后记为NT。
3)对于第二阶段的模型,把步骤2里面的数据带到新的模型里面,使用阶段1里面的训练集预测结果数据作为特征并且进行横向拼接记为NTRA,并使用NTRA和它们原有的标签继续进行训练,训练之后的模型在NT里进行预测,最终得到Stacking模型融合之后的模型,也就是可以通过这样的步骤预测最终的结果。
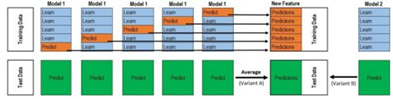
在模型的选取上,第一阶段的模型可以使用一些简单的模型,比如对于Titanic比赛里,第一阶段可以选择支持向量机、决策树、KNN、朴素贝叶斯、logistic模型这五种方法作为初始训练,得到的结果作为特征输入到第二阶段的模型里,第二阶段的模型可以选取BP神经网络或者XGBoost方法做训练,从而得到最终的大模型。
在某种程度上,Stacking方法是在某些竞赛中是非常强的,因为第一阶段简单的分类器可以互不干扰地提取数据的特征,并且有效的交给更强的第二阶段模型进行训练,不需要对于模型进行太多的调参操作,整个大模型的稳健性比较好,而Stacking最大的问题是训练比较缓慢,这个在实际生产环境使用需要考虑使用离线训练等。
总的来说,Stacking的学习方法是一种非常经典并且十分实用的机器学习策略,在比赛中经常被使用到,因为它本身的思路是非常合理的,对于初学者来说,需要熟悉并掌握这种思路,特别是在实战场景中的使用和具体源代码的实现方式,可以参加一些竞赛去实际的使用这种方法。