数据挖掘-AdaBoost方法简介
初探AdaBoost方法
本文将会介绍AdaBoost方法,之前的文章介绍过Boosting方法的思路,以及一些常见的Boosting方法原理,比如GBDT梯度提升树、XGBoost等算法,本次文章介绍的AdaBoost方法是一种比较简单但是非常实用的提升算法,这种算法其实是一种处理问题的思路或是框架,不能完全称之为具体的算法。它的核心目标就是在同一个数据集上,使用不同的弱分类器进行训练,并且通过调整权重来对分类器进行组合,从而形成一个更准确更稳健的强分类模型。
具体来说,AdaBoost算法其实每次只训练一个分类器,用来训练的数据每次都是一样的,只不过每次训练某个分类器的时候,之前训练好的分类器里面的参数不会再变动,而当前被训练的分类器使用的数据会被加权,从而影响它的损失函数,也就是说数据还是那份数据,但是数据的重要性不一样,之前训练错误的样本会被加上比较大的权重,而之前训练正确的样本则会减小权重,通过这种处理方式,让后面的分类器更“重视”之前训练错误的样本,从而提升整个模型的训练准确率。当然AdaBoost算法最后的输出也是要N 个分类器综合进行判断来得到预测结果,值得注意的是,如果数据里面具有比较异常的样本,则需要进行手动删除,因为AdaBoost本身对于错误的样本会过度训练,所以要进行删除脏数据,防止最终的模型被错误的训练。那么下面我们来简单介绍一下这种算法的步骤。
1)初始化各类参数,并且将原始数据进行清洗,选取基准弱分类器的模型,比如选择决策树作为弱分类器。
2)对于N个样本使用决策树进行学习,此时每个样本的权重是一样的,训练后形成第一个模型。
3)把第一次训练的错误的样本的权重进行增加,训练正确的样本权重进行减小,开始训练第二个弱分类器。
4)反复重复步骤3,把历史训练里面错误的样本进行汇总后,加大错误样本的权重,减小正确样本的权重来训练当前分类器
5)最终得到K个弱分类器,可以使用权重投票法让这些分类器进行联合预测得到最终的预测结果。其中单个分类器如果误差比较小,则它的投票权重则会被放大。
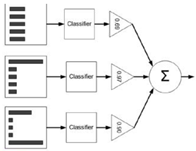
总的来说,AdaBoost方法其实是一种策略,它本身使用了串行的思路,把各个弱分类器进行连接,并且在各个分类器内部的模型可以任意选取,比较灵活,并且最后构成的强分类器是比较准确且稳健的。但需要值得注意的是,AdaBoost算法的迭代次数是比较难确定的,而且它的训练速度是非常慢的,因为串行的原因,每次训练只能按顺序进行训练,所以在数据量比较大的情况下,无法并行也是这种算法的缺点。当然AdaBoost算法的提出是比较经典的,它把弱分类器通过组合的方式,提高了预测准确率,初学者需要弄懂它的原理和步骤,从而在后续的实际场景中灵活使用。