数据挖掘-探讨Kmeans算法
Kmeans算法简介
众所周知,机器学习分为有监督学习和无监督学习两种。对于有监督学习的情况,一般根据被解释变量是否连续,分为分类问题和回归问题,在之前的文章中已经有过讨论。在本文中,我们将讨论无监督学习中的一种聚类方法,即Kmeans算法。该算法被称为K均值方法,从字面上的意思就可以看出,确定参数K非常重要。实际上,K均值方法的主要思想是采用距离作为衡量两个实体之间是否属于一个群落的评判标准,如果两个实体的距离越近,那么它们之间的相似性就越大;如果两个实体的相似度越远,那么它们之间的相似性就越小。
在某种程度上来说,影响Kmeans算法的因素主要有2个,第一个因素是K值的选取,第二个因素是衡量距离的公式。对于第一个因素来说,需要使用者进行大量的尝试,寻找在不同K下的损失函数并进行比较,找出所谓的肘部值,即损失函数曲线的凸点,在该凸点时,损失函数较小,同时不会造成过度的分类。在下图中,K的值为2对应的是损失函数的肘部值,即损失函数曲线的凸点。
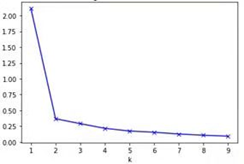
对于第二个因素来说,衡量样本之间的距离方式有很多,比如欧式距离、绝对值距离、闵可夫斯基距离等。一般来说算法包默认使用欧氏距离,使用者也可以根据问题的实际情况去定义其他的距离函数。
下面我们来探讨Kmeans算法的主要步骤:
(1)确定K值,并随机在数据集合中选择K个数据点作中心,即有K个中心。
(2)对数据集合中的每个数据样本,计算它们与每个中心的距离,将离当前样本划归为距离最近的中心所属的集合。
(3)将所有的数据样本划分为K个集合,然后再次通过计算集合内部的数据均值重新得到每个集合的中心。
(4)如果再次计算得到的中心和上一次的中心的距离小于事先设定的一个较小的阈值时,认为中心的位置变化已经不大并且已经稳定,即认为Kmeans算法已经结束。反之,则继续计算步骤(3)直到中心的位置已经基本稳定。
通过上述步骤,我们发现该算法的原理较为简单,并且实现起来很方便,同时计算复杂度不高,聚类效果还不错。但同时,需要注意到算法有以下三点的不足。
1、该算法非常依赖K值的选择,如果K值选的不对,那么会很影响最终的聚类效果,即对K值的选择非常敏感。
2、该算法对离群点、异常数据较为敏感,当数据集中出现此类异常数据时,计算得到的距离会影响中心的位置,进而对聚类的每一步计算造成影响,使得聚类的效果和真实的结果有较大差异。
3、该算法得到的聚类结果可能不是全局最优的结果,因为它每次得到的中心是和上一次进行比较的,如果小于某个阈值,那么就会停止计算。如果在初始选择的时候刚好在某个局部最优分类点附近的话,那么通过几次迭代计算后会使得中心稳定在局部最优值,没有达到最好的聚类效果。
其实Kmeans这种算法在大量的实际场景中,有着非常广泛的应用。比如寻找犯罪地点、寻找保险诈骗案件、文档自动化归类等。所以理解Kmeans算法的原理和步骤,对于在实际场景的应用有好处。
总的来说,Kmeans算法是无监督学习中最简单的一种算法,在某些明确需要几个类别的场景中,该算法可以较快地进行聚类。同时,还可以应用该算法进行异常值的发现,从而提高数据质量和分析的价值。
