数据挖掘-knn
KNN算法
KNN算法是机器学习里较为简单和初级的算法,也称为最近邻算法。可以算的上是学习数据挖掘的入门算法,在大赛中,该算法一般用来作为插值来用,一般不会直接使用该算法来进行预测。
众所周知,对于KNN算法可以这样理解,该算法是基于一种现有的数据分布来作为判别依据,当一条数据进来时,通过之前确定的参数k去统计,距离这个点最近的k个点的类别,选择次数最多的类别作为新数据的类别。
对于这种算法,下述图片能很好的说明:
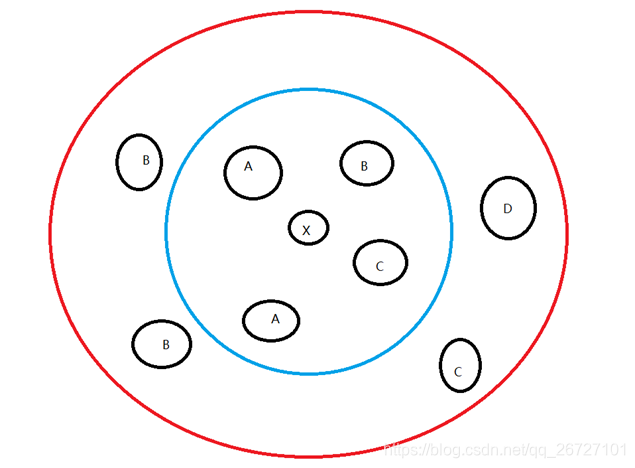
在上述的图片中,A、B、C、D为已有数据的类型,当新数据x进入时,如果用户将k定为4,那么将统计最近4个点的类别,即蓝圈内的类别,出现次数最高的是A,那么新数据x的类别将被判定为A。如果用户将k定为8,那么将统计最近8个点的类别,即红圈内的类别,出现次数最高的是B,那么新数据x的类别将被判定为B。
所以对于k的选取是非常重要的,而根据实际的数据集,选取的k是不一样的。从某种意义来说,k的值不是越大越好,应该取某个范围内,建议k取值为2~10。
从另一个方面来说,如何衡量距离当前点最近的标准也是非常重要的。因为距离的计算公式将直接决定哪些点是最近的。距离的公式有很大,比如曼哈顿距离(绝对值之差)、平方距离、三次方距离、几何平均距离等。这些距离本质上是1-范数、2-范数、3-范数、p-范数。一般比赛采用曼哈顿距离和平方距离较多,因为计算量较小且较为稳定。
在这个基础上,我们发现其实对于新数据类别的判定是一种基于策略的结果。即k的选取和距离公式会最终影响新数据的类别,一般会把这两者进行结合。现在从更高的角度去看这个问题,统计次数是一种简单的计数,是把最近的k个点对于新数据的影响一视同仁。而如果我们对于更近的点赋予更高的权重,更远的点赋予更小的权重,从某种意义上来说,可以更为准确的决定新数据的类别。在python自带的knn方法中,就有这个参数,用户可以把这个参数设置为distance,即基于距离的倒数去决定该权重。距离越近的权重越大,距离越远的权重越小。这也是比较合乎逻辑的优化方法。
KNN方法本质上来说是不需要进行训练的,即无法通过训练数据直接得到参数,只能凭借数据的实际情况去决定k值等参数。并且该方法计算量非常大,当数据本身角度且特征非常多时,计算量很大,得到的结果往往会被数据本身所影响。下面从两个角度说明:
(1)数据量很大,且每个特征的值范围差距很大。
比如当前班里40人,新来一个学生,不知道对方性别。现在用全班同学的身高、体重去预测新学生的性别,那么由于体重的数值和身高的范围不在一个数量级,很容易会导致体重大的人影响最终的判断。
在这种情况下,可以对数据进行标准化,将数据转化为同一个范围的数值,再使用KNN算法会得到较为信服的结果。
(2)数据维度很高
比如当前班里40人,新来一个学生,不知道对方性别。现在用全班同学的身高、体重、脚长、臂展、胸围、腰围、手指长度去预测新学生的性别,那么由于数据的维度较高,涉及的变量较多,如果直接进行KNN预测,那么会导致预测的结果不准确。
在这种情况下,可以对变量进行筛选或降维,可以基于用户经验对变量进行筛选或使用主成分分析进行数据降维,再使用KNN算法会得到较好的结果。
总的来说,KNN算法是比较简单的方法,并且对于数据的要求较高,如果数据的维度很高、数据量很大、数据类别的容量不平衡等情况下,不建议直接使用KNN算法。并且直接通过距离对各个变量一视同仁的时候,很难找出究竟是哪一个变量较为显著的影响了最终的类别。因此在写论文或比赛时,可以把这种方法当作一种简单的尝试,但不能作为最终的直接解决方法,尽量结合其他机器学习算法一起构造模型解决问题。
