神经网络学习-初探激活函数
理解激活函数
在之前的文章中,我们谈到了神经网络的结构和基本思路,并且提及了激活函数。在本次文章中,我们来具体比较几种常见的神经网络,寻找它们之间的共同特点和不同之处。激活函数是神经网络中非常重要的角色,激活函数的好坏可以决定神经网络最终的准确率和稳健性。
激活函数在神经网络中扮演的角色其实是一种非线性的映射形式,所以我们看到的绝大多数激活函数都是非线性函数。在神经网络中,每当上一层的神经元向下层传递信息的时候,中间都会经过激活函数的映射,从而增加整体模型的复杂度和预测能力。如果激活函数是线性函数,那么神经网络其实可以看作多层的回归模型,其本身的预测能力大大下降。
下面我们来介绍常见的激活函数,主要有sigmoid函数、tanh函数、ReLU函数、Leaky-ReLU函数、ELU函数。
首先是经典的sigmoid函数,该函数是最早被使用的神经网络非线性激活函数,从它的函数形式我们可以,它在x取值距离零点近的时候,能够进行较好地映射,当x的取值距离零点比较远的时候,映射后的值几乎相同。所以这种函数在实际的竞赛、论文中,较少被使用,但是由于它是最开始被使用到神经网络中的非线性激活函数,所以初学者需要记住sigmoid函数的特性。
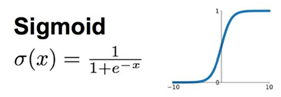
其次是tanh函数,该函数和sigmoid函数的区别是,该函数在x取0的时候映射值是0,而sigmoid函数在x取0的时候映射值是1/2。与此同时,我们还发现,在距离零点的时候,tanh函数比sigmoid函数更为陡峭,即收敛更迅速。但是tanh函数和sigmoid函数的相同点都是当x取值距离零点较远的时候,映射后的值差别不大,这样会导致神经网络训练到后期的下降梯度消失,所以该函数和sigmoid函数一样,在实际问题中使用的不多。
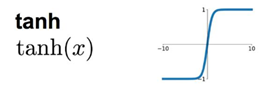
然后我们介绍ReLU函数,这个函数是一个分段函数,显然是一个连续的函数,但是该函数在x=0的时候,是不可导的,在其他x的取值是处处可导的。这种函数在x>0的时候,是一种线性的映射,即可以避免之前的tanh函数和sigmoid函数在训练后期的下降梯度消失的问题。但是这种函数的问题在于,到了训练的后期,会使得激活函数映射后的值变为0,这样会使得部分神经元参数无法更新。
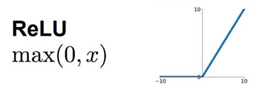
在看了ReLU函数的缺点后,有学者对ReLU函数进行了优化,提出了一种Leaky-ReLU函数,即在函数的左侧加入了系数,在不改变ReLU函数原有的特征基础上,继承了ReLU函数的优点,同时避免了训练后期部分神经元参数无法更新的问题,这个参数一般取值较小,比如0.01~0.1的范围,具体取值还是需要到实际问题去确定。

最后我们介绍一下ELU函数,这种激活函数和前面的Leaky-ReLU函数较为相似,区别是函数的左侧用指数函数去表达,而不是线性函数。同时这种激活函数在x取值趋近于0 的时候,收敛速度比Leaky-ReLU函数的收敛速度更快,但是这种函数的缺点是有指数函数,即在数据量大、多层的神经网络进行训练的时候,会降低一些计算的速度。

总的来说,激活函数的种类非常多,初学者需要理解激活函数的意义,通过引进激活函数可以增加模型的复杂性和模型的准确性。初学者可以在实际问题中使用不同的激活函数去观察实际效果,并且可以对现有的函数进行系数的优化改进或者提出新的激活函数,所以深入理解激活函数的原理和设计思路还是非常重要的。
