神经网络学习-介绍Seq2Seq和Attention机制
初探Seq2Seq和Attention机制
在之前我们介绍过NLP自然语言处理中最基本的一些神经网络方法,比如RNN循环神经网络、LSTM长短期记忆网络、GRU门控循环网络等。而本文将会介绍一种新的形式,在语言翻译中经常会被使用到,就是最经典的Seq2Seq模式,这种模式其实是一种编码器和解码器的组合。Seq2Seq在输入层和隐藏层中间放置了一个编码器,这个编码器可以是RNN、LSTM、GRU、CNN等;而它也在隐藏层和输出层中间放置了一个解码器,这个解码器也可以是RNN、LSTM、GRU、CNN等。正是通过这种编码器,把上下文的信息编入到一个固定长度的向量中,并且让解码器去读取和解析这个向量,使得Seq2Seq可以解决一些基于上下文的翻译问题或是文本生成的问题,那么下面我们来进行详细介绍这种Seq2Seq的内部结构,本文将以GRU作为编码器和解码器进行内部结构的说明。
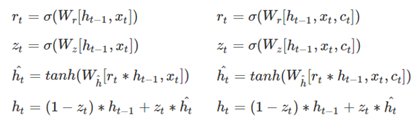
根据上图可以发现,左边是编码器、右边是解码器。在编码器encoder部分,Seq2Seq的编码器和GRU就是一样的,而在解码器decoder部分,Seq2Seq的解码器里的GRU是加入了中间向量c(t)的,因为个向量里蕴含了编码器得到的上下文信息,而传统的GRU里没有这个向量c(t) ,所以这也是Seq2Seq在某些应用比GRU等神经网络效果更好的原因。
显然,这种Seq2Seq机制是不需要输入和输出的长度相等,所以可以处理常见的自然语言中的应用,比如文本摘要的提取、语音识别、机器翻译等,很多后续的模型都是基于这个思路去进行优化的。而对于Seq2Seq来说,它也有缺点,那就是中间向量c(t)是个定长的向量,在一些长句中很容易丢失一部分信息,从而使得结果不准确。并且在序列较长的句子里,Seq2Seq这种是使用最后一个神经元进行映射后得到的上下文向量c(t)是不合理的,因为存在着梯度消失的问题,使得上下文向量c(t)无法包含更多有用的信息。
而在后续对于此类模型的优化中,又提出了Attention注意力机制,这种机制是把注意力放在原始句子的当前信息上,因此要比上下文信息c(t)更为灵活和准确一些。比如原始句子是“I eat orange”在进行翻译时,使用Attention机制是在翻译某个词的时候把注意力集中在当前词,比如翻译“吃”的时候要把注意力放在“eat”上面,而在翻译“桔子”的时候,要把注意力放在“orange”上面。这种注意力机制的上下文向量不是固定的,而是基于编码器历史状态的信息进行计算得到的,也就是在解码器decoder的第N个神经元是根据之前神经元的隐藏层向量h(N-1)计算出当前的状态和编码器encoder里的每一个神经元的相关性,然后有两种方法进行选择,比如使用贪心算法取最大的相关性进行保留;或者使用束搜索保留前K个结果并且重复这些步骤。
总的来说,Seq2Seq是一种比较经典的拓扑结构,它本身是考虑到在NLP应用里将上下文信息进行使用,所以会比传统的RNN等效果更好。而后面的Attention机制其实是一种更拟人化的思路,加入了这种机制的效果会更好,但是显然计算量会更大,所以后续的又有预训练模型的提出。总的来说,Seq2Seq这种方法在实际应用的不多,因为有更好的模型被提出,而它的这种基于上下文的思想可以被借鉴和学习。