神经网络学习-初探GPT模型思路
初探GPT思路
在之前的文章我们聊过transformer机制和bert模型的思路,其实transformer是一种理论的框架模型,而bert则是用了transformer模型的编码层构建得出的一个近似工程的模型,今天所介绍的GPT模型的全称是Generative Pre-Training,中文名字是生成式预训练模型,这种模型和bert模型最大的区别就是它使用的是transformer模型的解码层,也就是decoder部分的框架。所以这种GPT模型天然地就适合做输入的补全,因为它在训练的时候对于下文的内容是完全隔离的,因为transformer里的decoder层是加入了mask遮挡的,所以GPT被训练好以后就可以拿来直接做输入补全,相当于只用了“上文信息”,没有使用“下文信息”。下面我们来介绍这种模型的思路和原理。
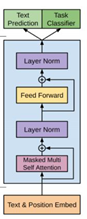
GPT模型分为两个阶段,第一阶段是根据海量的无标签数据进行训练,得到一个Pre-Training的预训练模型,然后根据实际的NLP任务,比如智能问答、输入补全等任务去进行模型的Fine-Tuning精调。首先是第一步预训练,该步骤是被训练者拿出的8亿多词的Corpus数据进行训练的,该训练是一个无监督的训练过程,其本身的目的是通过构建历史的K个词语去预测当前目标的词,通过极大化似然函数来构建的目标函数,然后再用随机梯度下降法进行训练。其中在输入的部分如图所示,有单词本身的词向量和位置信息进行融合后,采用self-attention自注意力机制进行计算,最后经过softmax得到输出。当然还有一点值得注意,仔细看下图你会发现,GPT模型不是完全使用了transformer机制的解码层,因为它抛弃了原有解码层里的第二个attention,那个attention是含有编码层信息的,所以是只留下了Mask的多头注意力机制。
在精调阶段的时候,也就是经过预训练之后,使用者拿到训练好的模型开始针对具体任务进行微调,和预训练不同的是,微调采用实际任务里的真实数据进行有监督学习,根据给定的输入单词序列和真实标签y去进行训练,这个时候的损失函数不仅仅是当前任务的极大似然函数,还有之前预训练的损失函数乘以惩罚系数后进行加总得到的,才是最终的损失函数,因为要防止当前的数据过度影响精调结果,加上预训练的损失函数可以有效防止过拟合。
其实对于GPT模型来说,它的效果是不如bert模型的,因为bert是双向架构,而GPT模型是一种单向的架构,而在某些任务确实只能使用GPT模型,因为像输入补全等任务天然地就不能看到下文的结果,否则会影响模型的泛化性和准确性。同时GPT模型对于精调的步骤不友好,在不同的任务里要调整精调阶段输入的数据结构,以适应预训练模型,也就是它的使用性不够便捷。对于这个模型其实也有一些优点,那就是其本身的transformer架构可以比传统的RNN、LSTM捕捉到更多的语义信息,并且速度较快方便并行,同时它训练的数据量较大,在某些NLP任务里预测的准确率较高。
总的来说,GPT模型是适合特定的自然语言处理任务的,因为bert模型天然就是使用上下文进行预测,而GPT使用的是上文历史信息进行预测,它的这种生成式的模型是比较适合文本生成类的任务的,所以初学者在遇到具体问题的时候要使用适当的模型,当然前提是要了解各个模型的原理和背后的思路。