神经网络学习-初探transformer机制和思路
初探transformer机制
在之前的文章里,我们探讨的是关于Seq2Seq和attention机制的原理,在本次文章中我们将会介绍现在比较受欢迎的transformer机制,这种机制是使用了6层encoder编码层和6层decoder解码层来构建的,并且利用self-attention机制,同时在decoder解码层的每一层都和encoder编码层做了注意力机制的计算,从而使得这个transformer的机制在一些NLP的任务上效果非常好,下面我们开始介绍这种机制的原理。
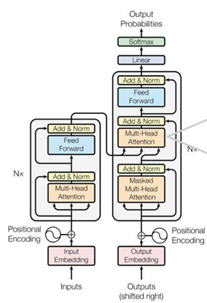
首先来看encoder层,它是把输入的句子转化为编码层所需要的向量,也就是输入的句子在embedding操作后,按照Positional-Encoding去计算得到位置的信息,然后拼接在一起得到一个新的embedding向量。用这个新的embedding向量分别去乘以W(Q)、W(K)、W(V) 三个参数矩阵,转化为self-attention机制所需要的Query向量、Key向量、Value向量,然后按之前的公式计算attention值,与此同时,这种类似的操作有8个,也就是所谓的多头注意力机制(multi-head attention),最终产生了8个不同的attention矩阵,将8个不同的attention进行拼接后得到最终的注意力向量。
再来看decoder层,它的内部结构最大的特点是在第一层有一个Masked的多头注意力机制,目的是为了怕输出之后的结果影响当前的计算。这种Masked原理是通过一个上三角全是0的矩阵而实现的,是在self-attention计算的公式里面的softmax步骤之前乘以Mask矩阵而实现的,最终得到是是Mask QK矩阵然后再去做后续的计算。而第二层的计算是加入了之前encoder计算的attention向量,目的是为了体现encoder层和decoder层之间关系。其他步骤和encoder层大致相似,最终得到了输出的预测结果。
当然,transformer机制并不是万能的,因为它也有一些缺点,同时也有一些优点。它的缺点是参数较多而且计算量非常大,因为transformer模型自身的多头注意力特点以及本身自注意力的计算量,导致整个模型的计算量呈现指数级的增长。在细节方面,单纯的transformer机制可能会存在顶层梯度消失的问题,并且对于位置信息的编码形式可能不符合语言学内部的逻辑,在局部信息的捕捉可能不够显著。当然transformer机制也是有很多优点的,毕竟在实战上的表现要比传统的RNN等模型要更好。除了之前谈到的利于并行化处理的架构,还有就是可以提供解释性更好的自注意力机制,并且采用多头的注意力可以学习不同空间或者说不同维度的任务。从另一个角度去看,这种模型由于是直接用单词和单词进行计算注意力,所以不需要经过隐藏层,有一种全局信息交互的思路。因此这种模型其实是非常经典的,在RNN和LSTM统治自然语言处理的时代,具有一定的划时代意义。
总的来说,transformer这种机制在现在的自然语言处理应用中使得的比较多,很多模型都是基于它的思路,比如Bert模型,GPT模型等。transformer在提出以后,比原来的RNN模型,LSTM模型等效果要好很多,并且可以并行化处理,提高模型训练效率。当然这种机制本身是较为复杂的,并且encoder编码层和decoder解码层内部的实现机制和架构是有区别的,初学者需要注意这些细节,并且应该充分理解实现原理,从而在后续的应用里可以更好的使用这种transformer机制。