统计学习-特征工程介绍
探究特征工程
众所周知,特征工程是非常重要的数据挖掘步骤之一。在我们获取数据后,会首先进行数据清洗并得到一个能够分析的数据集。然后开始观察数据,并对数据做特征工程处理,因为有些模型对数据的特征属性要求较高。因此特征工程处理技巧是一个非常重要的步骤,它甚至可以影响最终数据挖掘的结果。在本文中,将会介绍几种简单的特征工程方法,比如对数压缩、特征归一化等方法。
首先我们对特征也就是解释变量的种类做一个归纳,大致的变量可以分为离散无序变量、离散有序变量、连续变量、非数值变量等。对于离散无序变量,比如性别、邮编、物品种类等都是离散无序变量。对于离散有序变量来说,常见的比如学历、年龄段等变量是属于离散有序变量。而对于连续变量,常见的有身高、体重等变量是属于连续变量。对于非数值变量,比如图片、文本、日志、邮件等变量。而对于不同的变量类型,我们会采用不同的特征工程技巧,下面我们来进行介绍。
首先介绍的是特征变换,特征变换属于一种常见的变量映射方法。由于在经典回归模型中,模型的系数受到变量取值范围的影响较大,所以我们可以在进行模型分析之前先进行特征变换。常见的特征变换有标准化和区间放缩法。标准化的公式如下:
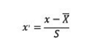
该公式代表的是把所有的值都映射到同一个量纲下,使得数据本身的单位不会过度影响模型的系数。
而对于区间放缩法的公式如下:
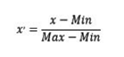
该公式的含义是把某个变量的数值进行映射到[0,1]的区间上,因为变量的取值总是在最小值和最大值之间,因此它们在经过上述公式的变换后会落入[0,1]区间。该公式也可以帮助使用者消除数据单位量纲的影响。
所以我们可以看出,如果使用者在对连续的数据进行分析时,最好先将数据进行特征变换,以此来消除量纲和数据单位对模型最终参数的影响。
下面我们来介绍一下特征压缩这种方法,特征压缩是一种非常常用的特征工程方法。就拿常见的对数变换方法来说,该方法是对自变量进行对数变换,比如直接使用以自然数e为底的log函数进行映射。其实对于对数压缩方法来说,它有两个好处。第一是可以降低数值较大的样本对于模型参数的影响,降低了数据异常值的影响,因为在实际的数据集中常常存在一些异常数据的情况,使用对数压缩变换可以降低这种影响。第二是这种变换可以将一些偏态的分布转换为近似的正态分布,从而更符合模型的使用假设。
其实还有比较常用的压缩方法,比如主成分分析方法(PCA),在后续文章中我们会专门介绍主成分分析方法。该方法是一种常见的提取变量主要特征的方法,通常用于变量的降维处理,进而降低模型的复杂度,增加模型的通用性和解释性。
总的来说,特征工程有许多的技巧和方法,本文只是对特征工程进行一个初步的简单介绍,在后续的文章还会进行其他的特征工程方法介绍。而实际上,特征工程是非常依赖分析者的经验的,何时使用特征工程技巧,使用什么特征工程技巧都会决定模型最终的可解释性和预测准确性。因此我们需要重视特征工程方法,加强这方面的学习和积累。
