神经网络学习-初探Bert模型思路
初探Bert思路
在上一次的文章我们介绍过transformer机制的思路,是使用了6层encoder编码层和6层decoder解码层构建得出的,而在本文中我们将会介绍Bert的原理和思路,在介绍之前会先探讨Pre-training和Fine-tuning的思路,从而帮助读者更好地去理解Bert的方法和原理。
首先我们来介绍预训练Pre-training和微调Fine-tuning的思路,这是在实际应用里得到的经验,因为在一些图像问题和自然语言处理问题里,之前已经训练得到的模型里在实际应用可以继续优化,比如图像分类就是很好的案例,之前训练过的模型可以很好的识别当前物体,当有一些新的图片想要拿去对模型做优化的时候,老模型可以继续使用,比如将最后一层的output去除,然后在这个基础上开始训练新的模型,也就是把老的模型当作一种先验的知识输入到新的模型里,使得准确率等指标得以提升。这种思路其实就是迁移学习的一个处理流程,当对于新获取的大量数据并且标签较少的情况,可以使用之前用超大数据量训练好的模型,在这个基础上再训练后,就可以得到具体应用需要的模型。其实Bert的处理思路就是这样,之前训练好的模型开源后,使用者可以在这个模型的基础上继续精调Fine-tuning,这样得到最终的模型要比完全自己从头训练的模型要效果更好。
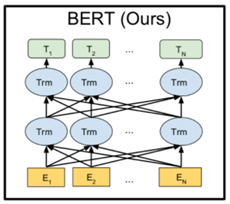
其实对于Bert来说,它的模型结构和transformer的思路是一样的,在这个基础上使用了双向的transformer block进行连接,虽然这样会使用更多的参数,但是由于自然语言处理是一种天然具有上下文的问题,所以使用双向的结构会使得整体效果好一点。而Bert里第一步是E操作代表的是Embedding操作,但其内部由三种Embedding构成,分别是Position-Embedding来记录位置信息,Token-Embedding来记录词向量信息,Segment-Embedding来区别不同句子的信息;同时在训练过程中会把需要预测的token以15%的概率进行遮掩,从而增加模型的预测能力和泛化性。上述的步骤其实都是预训练的过程,谷歌已经把这些步骤都做完了,我们可以开源获取到预训练模型后,针对自己的任务进行后续精调。
Bert模型其实在被提出后就得到了广泛使用,并且在NLP领域的很多领域中的效果要比传统的RNN和LSTM效果更好,因为它自身的Encoder层有自注意力机制self-attention,同时这个模型可以捕捉到较为长距离的信息,从而提升预测准确率。从迁移学习的角度来看,它的输入层和输出层更具有通用性,所以它的预训练模型可以被广泛使用到各个应用。从细节来看,Bert模型在最开始做embedding的时候,考虑到了句子层面的embedding,所以可以获取到更高级别的句子特征、语义特征,从而帮助在某些问题比如情感分析等获取到更多的信息,使得预测的效果更好。
总的来说,Bert模型是目前比较受欢迎的模型,因为它的通用性非常好并且设计的架构十分合理。但该模型有一个最大的缺点就是参数非常多,从而导致训练时间非常久,也导致了十分消耗服务器资源,并且由于其只预测15%,所以最终模型的收敛也很慢,并且遮挡标记的形式还有待优化。但总体上来说,Bert模型的理论是继承自transformer机制的,并且确实是做了一些优化,所以初学者需要了解该模型的设计细节,方便后续更好地使用。