图论-图论算法之DeepWalk
Graph-Embedding和DeepWalk算法
在之前的图算法介绍里,我们探讨了部分比较简单和经典的图算法,比如PageRank、最短路径、深度优先搜索等方法。在某些场景,之前介绍的一些算法虽然很经典,逻辑很清晰,但是由于实际情况里数据量非常大,所以经常会用到Graph-Embedding类型的算法,在基于图的推荐等经常被使用,因此本文将会介绍这种类型的算法,并且拿一个最基础的Graph-Embedding类型的算法做进一步介绍。
首先介绍的是Graph-Embedding,也就是所谓的图嵌入,这种方法是把实际场景里的高维度稀疏图数据,转化为低维度稠密的向量,然后再进行后续深度学习或者机器学习算法进行构建模型。这种思路是比较常见的,比如某线上商城有100万种商品、3亿用户,这个时候如果直接在原始图上进行推荐、聚类等操作,会非常耗时和耗资源,所以这种嵌入的思路应运而生。
那么基于上述的图嵌入思路,在2014年提出了比较经典的DeepWalk方法,它的思路就是多次在图上进行随机游走,然后得到海量的节点序列,并且把这些序列作为训练样本输入到模型进行训练,并且得到最终的Embedding结果向量。下面我们来说明DeepWalk算法的步骤。
1)初始化相关的参数,比如设置Embedding结果的向量长度,设置每次随机游走总共的步数,设置走多少轮次等参数。
2)对于图里的每一个节点,都进行K次游走,而且每一次在游走的时候,每次都走N步,将走过的节点进行记录,对于得到的结果进行打乱处理,然后再把这些结果输入到树里面,再次进行随机游走,并记录结果,然后使用skip-gram模型对参数进行更新。
3)反复走过K轮次后,结束该算法,并且得到最终的Embedding结果。
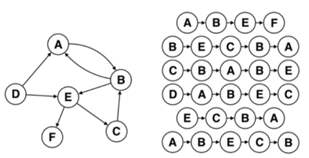
从广义来说,我们可以认为DeepWalk其实是一种可以回溯的深度优先算法,其本身使用了两次随机游走,一次是在图里针对节点进行随机游走,第二次是针对游走的结果和当前节点构成的树再一次进行随机游走,因此只要数据量够大就可以使得这种方法比较好地刻画出图里面节点的关联性和结构信息。当然这种方法由于提出的时间比较早,还可以在进行优化,比如可以考虑点之间的路径存在权重,从而引入跳转概率,尽可能地游走到权值更高、关系更强的节点之中,这样可以更好地刻画图的结构信息,因为当前的DeepWalk算法其实是完全等概率的一种跳转形式,现实应用显然可以考虑边的权重等信息,这个在后续的模型里会再进行介绍。
总的来说,图嵌入的方法是想把数据的表现形式进行转化,把高维度稀疏图数据转为低维度稠密的向量,从而使得可以展开并行化的计算,在大数据场景下非常实用;并且由于这种嵌入的技术可以看作特征工程,在转换后的数据可以继续无缝对接机器学习算法、神经网络等,所以可用性和灵活性较好。而DeepWalk算法是基于随机游走提出的,虽然思路比较简单,但在某些实际问题中,可以使用它进行求解,所以初学者需要熟练掌握这种嵌入的思路和算法。