统计学习-主成分分析方法介绍
探究主成分分析
今天我们来聊聊这个主成分分析方法,主成分分析方法是一种将统计问题中的自变量进行组合,组合成新的变量后,按照使用者需求,提取出最主要的变量的一种方法。主成分分析方法是一种比较常见的统计学方法,常用于降维、特征工程等场景,在一些竞赛中使用主成分分析方法对海量的特征进行提取,合成新的维度,这样可以提高模型的可解释性,也可以提升模型的稳健性。
当然,主成分分析的使用是要分情况的,因为在某些场景下是不建议使用该方法的,比如自变量数量较少时,可能某些场景需要研究的变量就4、5个,如果此时继续使用主成分分析方法,可能会有问题。还有一些情况,变量之间是基本独立的,此时如果使用主成分分析方法会使得变量混合到一起,造成最后的模型可解释性不强。但是在某些情况,如果使用主成分分析方法进行处理是对问题的解决有好处,比如在图像压缩等高维度场景的情况下,使用该方法可以对数据进行降维,在压缩的情况下最大程度保留原始数据的信息。
其实主成分分析的核心思想,就是方差最大理论。这个要从信息论的信息熵说起,信息熵是一种代表信息所蕴含内容多少的一种衡量,即信息熵越大,所蕴含的信息越多,信息熵越大其实代表的就是越混乱,从统计指标上看就是一组数据的方差越大,波动性越大,它蕴含的信息就越多。主成分分析方法认为,通过主成分分析的线性变换,将原有的特征进行组合,得到一组新的互相之间独立的特征,而且新特征之间是通过信息贡献率进行排序的,含有原始变量的信息越高,排序越靠前,并且使用者可以根据这个顺序进行选择,从m个新的变量选择前k个变量后,从而达到变量降维的效果。
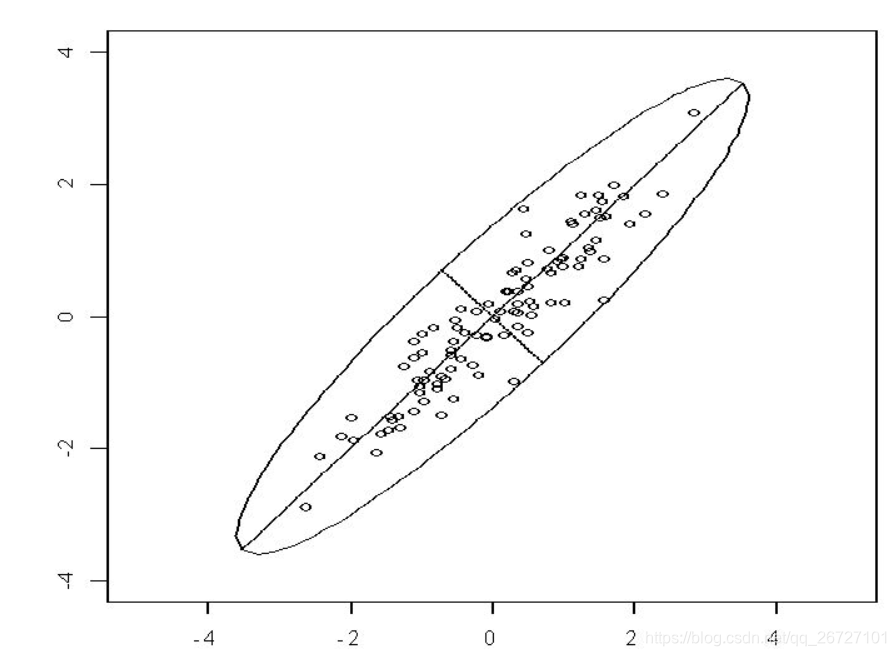
上图中的点是在理想正态分布情况下的数据样本的一个分布情况,大致都是在椭圆区域以内,当然实际情况下会有各种离群点或者异常值,这个我们暂时不考虑。从直观上我们可以发现,如果将图中的二维数据进行降维的话,可以降成图中的短线或是长线。显然在降维后,长线代表的新变量比短线代表的新变量要更能反映原始数据的信息,即损失了更少的信息。
而主成分分析方法就是把原始的变量转化成超空间上的一系列互相正交的线,这些新的互相正交的线是互不相关的,最终使得原始数据的信息能够最大的映射到新的变量上。
实际上,主成分分析方法也是有一些缺陷的,比如在某些问题上,变量之间的相关性较弱,那么这时候使用主成分分析的方法是不合理的。因为在主成分分析进行变量的组合和提取后,得到的新的变量的前几位可能并不能代表老的变量所蕴含的信息。从线性变换的角度来看,主成分分析是一种线性变换,而某些变量是存在非线性特性的,举个不恰当的例子,比如在医学上,吃巧克力会使人分泌多巴胺,即吃巧克力和多巴胺含量在前期是正比的关系,但是吃巧克力如果过多,这时候多巴胺的含量不会一直提升,反而有可能下降一些。即主成分方法处理这种非线性相关的变量时,起到的效果往往适得其反。
总的来说,主成分分析方法是一种非常经典的降维方法,它不仅可以从海量的变量中提取最有效的特征,也可以在一定程度上消除变量的相关性。但是使用者一定要关注该方法的使用情况,不能在数据挖掘等场景中一上去就直接使用主成分分析方法,要做到深入理解变量的含义以及数据的一些固有特性。作为一名初学者,理解主成分分析方法对于后续的竞赛或是实际问题处理上都是有好处的。
