图论-图论算法之InfoMap
图论算法简介之InfoMap算法
在上次的文章里,我们介绍了图论里的社区发现算法,那是一种通过模块度计算的算法,通过不断迭代和合并从而得到最终的社区结果。在本次文章中我们将会介绍InfoMap算法,这种算法的思路非常经典,而且InfoMap算法在数学上看是作者对图结构的聚合有着非常深刻的理解,该算法通过霍夫曼编码,将图结构的邻接矩阵进行转化,并且这种算法在实际场景的效果还不错,下面我们来介绍这种算法。
从本质上来说,InfoMap是想要构造出一种转移概率,然后使用点在图上进行随机游走,并生成序列的向量结果,通过对这些向量进行层次编码后,得到结果进行聚类,从而将更相似的向量聚合在一起,也就是对应的图里的点,这种思路不仅可以用在图论的应用里,还可以用在NLP自然语言处理的问题中。
InfoMap算法在最初想解决的是用最短编码去描述随机游走,传统的思路就是给每个点一个互不相同的编号,然后进行随机游走进行记录即可。但这种编码的方式不是最优的,于是InfoMap提出了双层编码,这种编码的优点是大大简化了编码长度,只需要先将点分为编号互不相同的N个大类,在每个类里面采用一样的编码,这样就可以节省编码的长度。特别的,InfoMap算法还把跳出该大类的行为进行编码,设定为000,那么每次随机游走进入到某个类的时候都是以类编码开头,离开类的时候都是以跳出行为000进行结尾,具有较好地可解释性。下面的图片就很好地说明了这种编码方法,肉类和国家这两个大类使用不同的编码,而类的内部可以使用一套编码,最后都是以End结尾,这样的编码形式其实是信息熵最小的。

那么根据上面的双层编码的语言描述,我们可以使用下面的公式来描述这种编码下进行随机游走的平均编码长度,其中第一个q代表的是所以群组类的名字的编码占比,qi代表是从群组i跳出来的概率,而H(Q)是编码群组名字所需要的平均长度,pi代表的是属于i群组的所有节点(内部编码节点和End节点)的编码占比,H(Pi)代表的是群组i里面所有节点所需要的平均字节长度。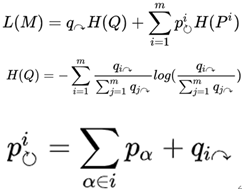
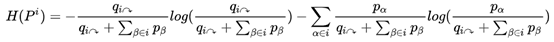
虽然上面的公式比较复杂,但其实其原理就是通过信息熵的计算公式进行构造,因为平均编码长度L(M)是群组类的编码所需要的平均长度和群内部节点所需要的平均长度,它们的系数p和q其实就是权值。那么有了公式以后,我们可以通过每个节点的访问概率和跳出类别i的概率来计算得到最终的结果,所以InfoMap和PageRank算法非常相似,它的步骤如下所示:
1)初始化相关参数,包括超参数随机跳转概率等,将每个节点都看作独立的社区。
2)使用随机游走对图里面的节点进行采样,得到一个序列,并且尝试按顺序把节点赋予和当前节点直接相连的邻居节点,计算L(M)的值,并且取L(M)下降最大的那个社团作为当前节点的社团,如果L(M)没有降低,则当前节点的社团还是它本身。
3)反复进行步骤2后,直到L(M)无法继续变化。
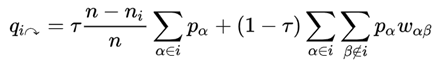
值得注意的是,为了防止上述随机游走无法跳出,还设置了一个超参数,这个超参数可以取值0.15,其实和PageRank里的那个超参数是一样的道理,就是防止陷入某个局部解,从而提升InfoMap算法的稳健性。
总的来说,InfoMap算法是比较经典的算法,它从信息学角度来理解图的聚类,是十分优美的算法,而初学者需要掌握和理解这种算法的核心思路,从而在后续自己面对图的聚类问题时,可以进行使用和优化,并且更好地解决真实应用里的问题。