统计学习-初探因子分析方法
初探因子分析
在之前的文章里,我们聊了主成分分析方法,这种方法广泛应用于各种实际统计问题,可以被用来进行降维处理,减少了变量数目,并且新变量之间没有相关性。今天我们来了解一下因子分析,因子分析从本质上来说就是一种寻找多个变量之间的共同因子,如果主成分分析方法是一种变量合成的方法,那么因子分析方法就是一种提取共性变量的方法。
其实因子分析这种方法最早是从教育统计来的,当时研究者发现某一科成绩好的学生,在另一科的成绩也不错。从现在的理解来看,数学成绩好的学生,物理成绩很有可能也不错;而英语成绩不错的学生,语文成绩可能也很棒。从深层次的角度上来说,数学成绩和物理成绩可能是逻辑能力和计算能力的体现,而语文成绩和英语成绩可能是阅读能力和写作能力的体现。因此,如果研究智力因素对成绩的影响,那么可以对各科成绩变量进行因子分解,得到一些共性因子后再对这个问题进行研究,可以得到更好的结论和更强的可解释性。
由于因子分析方法有很多种,比如最小平方法,最大似然解法,重心法等。从另一种角度来说,因子分析可以分为对变量做出因子分析和对样本做出因子分析,本文将介绍一些对变量做因子分析的原理和思想,方便初学者可以理解因子分析。
假设在问题中,自变量X和因变量Y之间存在线性关系,而更进一步来看,自变量X也存在深层的共性因子F,每一个自变量X都和因子F有线性关系,公式如下:
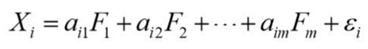
观察上面公式发现,该公式的形式和之前文章的线性回归模型结构相似,但其实在因子分析中,每个因子F之间是没有关联性的,并且为了标准化,它们的方差为1,从矩阵代数的角度理解,就是说每个因子构成的协方差矩阵是一个单位矩阵,即只有对角线(方差)是1,其余值都是0(不相关)。同时还值得注意的是,因子F的数量是小于自变量X的数量的,因为因子分析也是一种降维方法,所以需要因子的维度比原有变量的维度要少,从而达到降维的效果。
值得注意的是,由于因子分析是一种降维的处理方法,即在得到新的潜在影响因子后,我们需要对因子进行观察和理解,从而给因子赋予一个更贴合实际问题的含义。这个时候需要注意因子载荷矩阵,从数学角度来说,因子载荷矩阵是不唯一的,所以使用者可以观察不同的因子载荷矩阵,得到最适合当前问题的因子载荷矩阵,从而对因子F进行贴合实际的解释。
总的来说,因子分析是一种非常重要的降维方法,在某些情况下如果使用者认为当前观测的自变量无法反映真正的影响因素,那么可以使用因子分析方法进行处理。但是需要注意的是,在使用因子分析方法后,需要对潜在的因子进行合理的解释,否则因子分析方法会导致解释不清的问题。而且当自变量本身数量不多的情况下,也不建议使用因子分析方法,因为这样会丢失很多变量的信息,使得模型的准确性遭受影响。在实际问题中,还是要结合具体情况进行分析,不能随意使用因子分析方法。
