图论-图论算法之PageRank
图论算法简介之PageRank算法
在之前的文章里,我们对于社群发现、标签传播算法做过介绍,在互联网时代,其实最经典的图论算法就是PageRank算法,它是直接或者间接导致互联网发展的核心算法,因为这个算法本质上给所有的网页进行排序,这让使用者可以搜到自己更想要搜索的结果,从某种程度上来说是一种网页搜索排序的革命。在本次文章中,我们将会介绍PageRank算法的原理和步骤,方便大家加深对于这种图算法的理解。在下面的介绍中,图算法里的点我们就通过网页来代替,这样可以把这种算法的介绍变得更具体一些。
PageRank算法其实是根据PR计算得出的排序结果,而这个PR值是会定期对所有的网页进行迭代计算的,而PageRank算法的核心就是两条。第一条是,如果某个网页被大量的网页链接就会使得PR值较高,所以会让这个网页比较重要。第二条是,如果某个PR值较高的网页链接到一个新的网页,那么这个新的网页的PR值也会提高,所以也会让这个新的网页变得比原来更为重要。下面我们来介绍PageRank算法里的经典概念。
1)出链和出链,如果一个网页X里存在着网页Y的链接,用户在浏览网页X的时候点击了网页Y后跳转到了网页Y,这个时候。对于X来说就被称为X出链到Y;对于Y来说就被称为X入链到Y。
2)只对自己出链,这其实是一种互联网初期的作弊方法,当一个网页没有其他任何页面的链接,而只有自己的链接时,则称为只对自己出链。
3)无出链,如果网页X没有任何其他网页的链接时,则称为X网页无出链。
下面的图是PageRank的核心公式,代表了每次迭代计算PR值的表达式。因为PageRank这种算法其实只从出链去考虑,因此在计算某个网页X的PR值的时候,就看有哪些网页直接链接或者说出链到X就可以了,本质上一种投票的思路,就是看和X直接关联的网页总共的出链是多少,网页的PR值是多少,然后通过加权求和得出新一轮迭代的PR值,而下面的公式的加号左边就是按这个思路理解的,其中加号右边的N是所有网页的总数,α是超参数一般取0.85,这个加号右边的式子是防止迭代无法收敛的情况,特别是对于一些自己链接到自己的网页存在的情况。
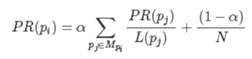
从算法本身来说,只需要根据当前的网页拓扑链接来进行迭代就可以了,一开始可以把所有网页的PR值设置成一样,然后经过不停地迭代就可以得到比较稳定的PR值,这其实是采用了马尔可夫链的收敛性质。当然PageRank算法的效率使得当年的Google搜索结果非常准确,而这种算法本身也会被钻空子,比如一些导航网页就有很高的PR值,但是其本身内容价值并不高。从另一个角度来说,这种排序算法也没有很好地解决冷启动问题,当一个新网页产生的时候,如果它的内容较好并且确实是搜索者想要搜索的结果,但是由于其本身在图内部被链接的较少,几乎没有网页会链接到这个新的网页,所以这个内容很棒但是比较新的网页的PR值会长期停留在比较低的水平,这对于一些专业的、冷门的内容来说,是不太友好的。
总的来说,本文提及的PageRank算法是比较经典的算法,后续一些研究者在这个算法上继续进行优化,得到了更为快速和准确的排序结果。对于初学者来说,了解这种图节点排序的算法是比较重要的,因为它可以帮助你更好的理解图结构的信息。虽然这种算法是很久之前被提出的,但在当前的实际问题中,仍可以使用PageRank进行求解,所以初学者需要熟练掌握这种算法。