听Andrew Ng深度学习课程,知识点整理
3.1.2 Bias and Variance
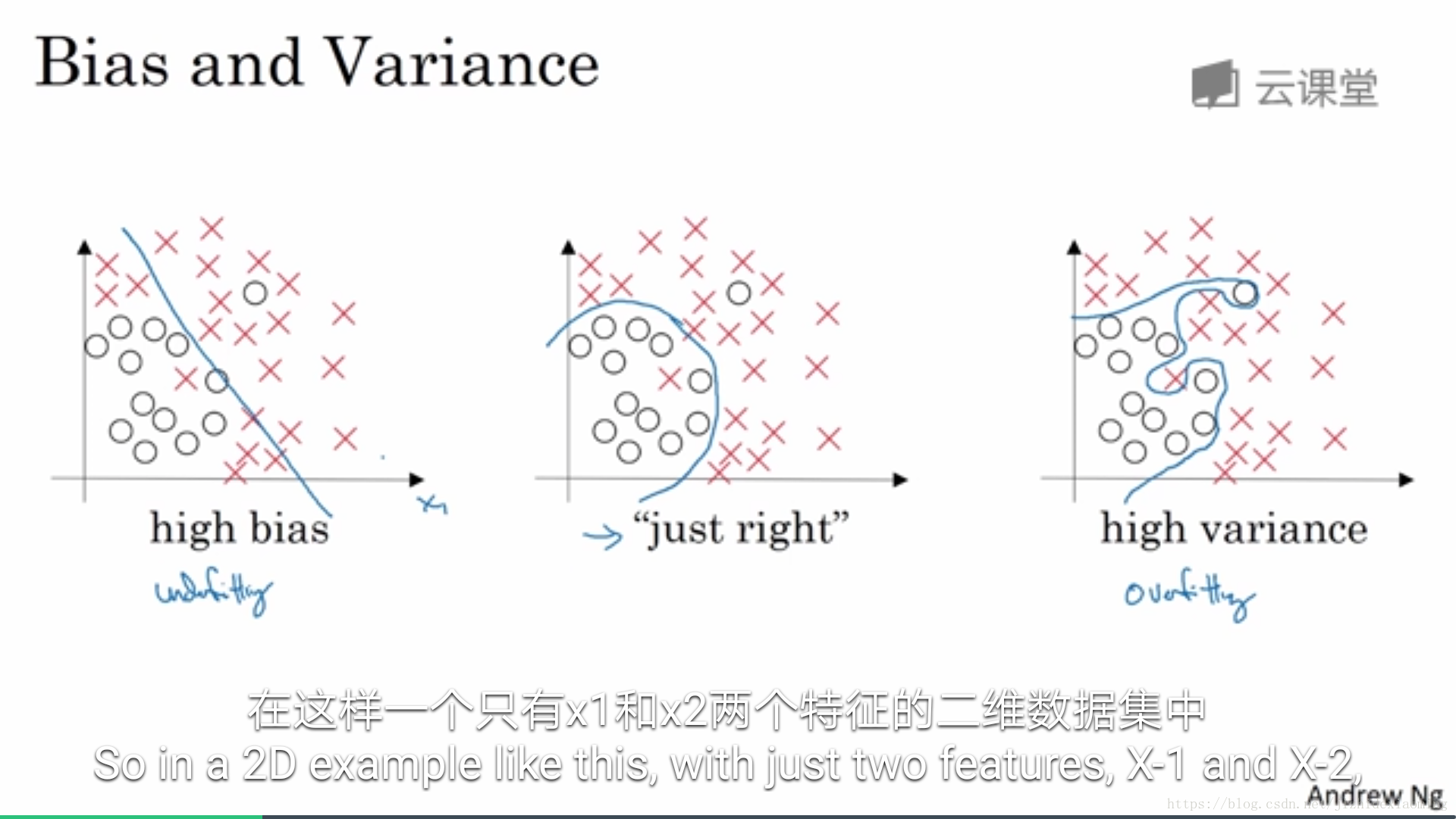
High bias: 训练集上,性能差,也即欠拟合(模型拟合能力)
High variance: 训练集上表现较好, 验证集上,性能差,也即过拟合(模型稳定性)
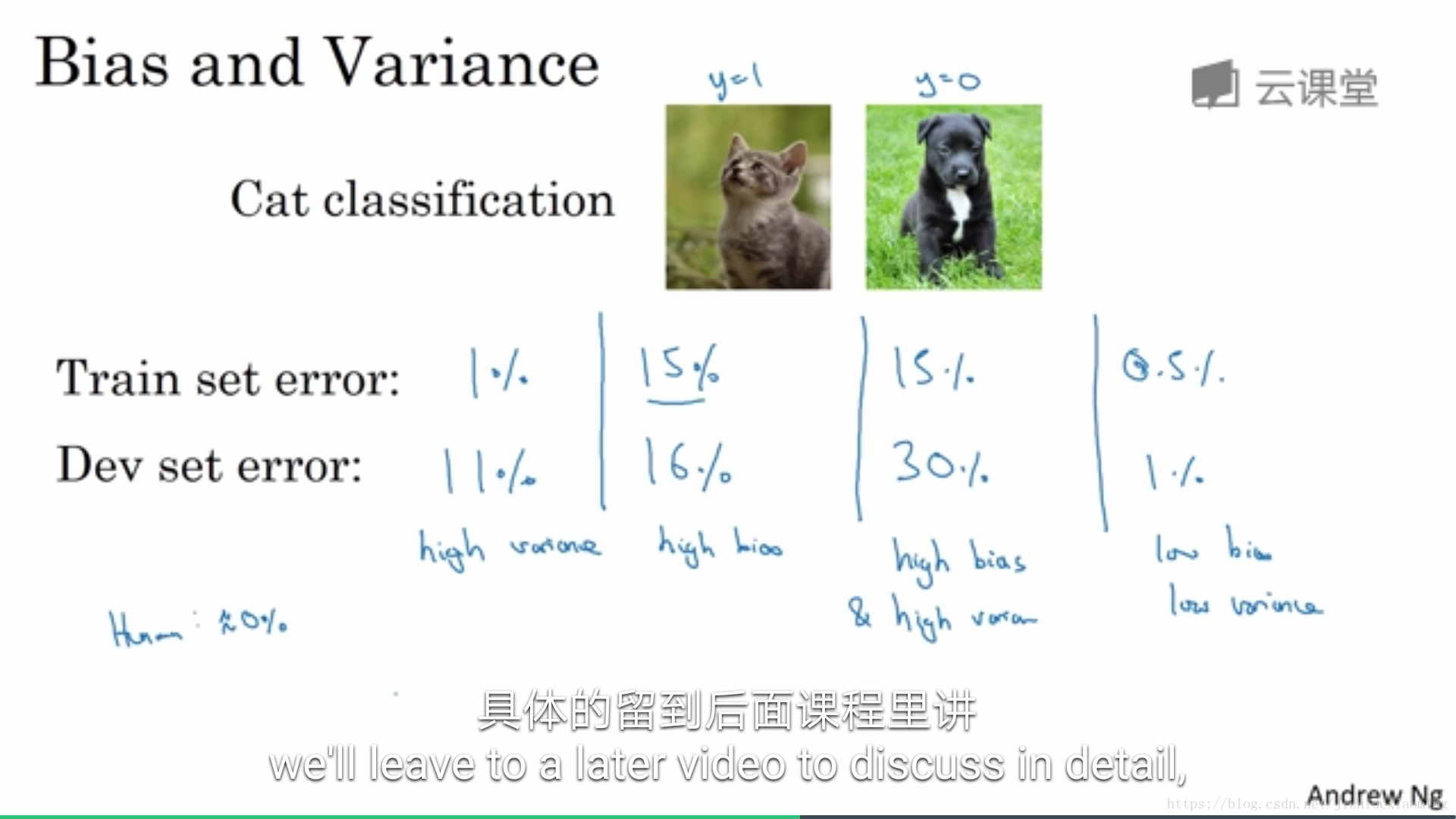
5.1.3 Basic recipe for machine learning
优化模型的第一步是,查看是否具有High bias,即该模型是否欠拟合。

7.1.4 Regularization
如果模型具有High variance,也即过拟合,该模型不够稳定,可以通过增加数据量,正则化或选择其他的NN结构,但如果增加数据可能代价大,所以首先应该是进行正则化。正则化即在原有得loss函数上,加上一个正则化项:所有参数w的平方的和,除以训练集的样本大小m。λ就是正则项系数,权衡正则项与J_0项的比重
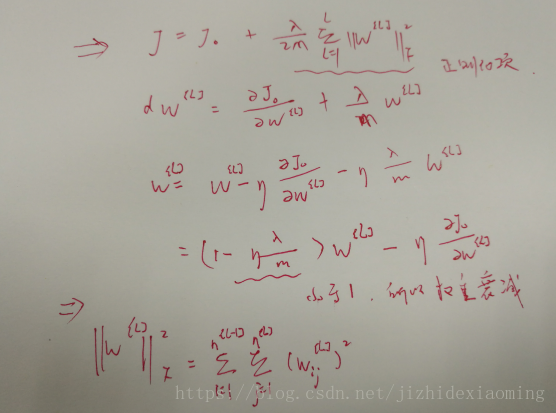
9.1.5 Why regularization reduces overfitting
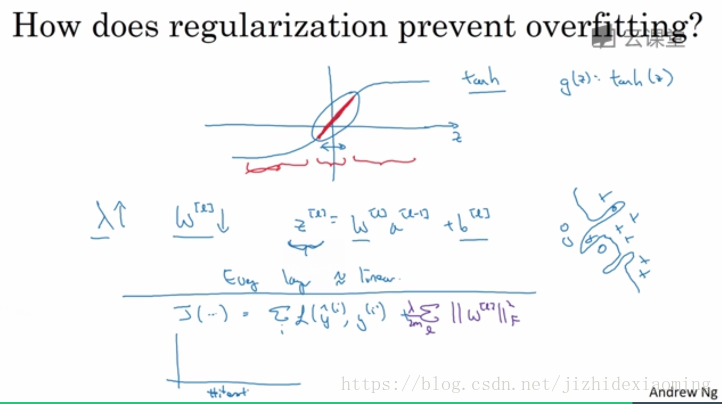
为何正则化可以有效降低过拟合,NG说是可以使得W参数小,进而使得 z = w*x + b小,则激活函数 g(z) = tanh(z),分布在红色范围,如图所示红色区域,接近为直线,此时激活函数基本失效(变为线性函数),学习能力变差,即可避免过拟合。
过拟合的通俗的解释参考
11.1.6 Dropout regularization
防止过拟合,L2正则化是通过修改代价函数来实现的,而Dropout则是通过修改神经网络本身来实现的,具体就是使得网络中部分神经元失活,但测试的时候不使用(测试需要稳定的输出)
Implementing droput:以三层网络为例
keep_prob = 0.8
最后一层a3后加上 dropout
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob # 生成随机数0或1
# d3 有0.8的概率为1, 0.2的概率为0,即大概有百分之20的数为0
a3 = np.multiply(a3, d3) % 使a3的神经元输出20%为0,期望值变为原来的80%
a3 /= keep_prb # 为了使其中20%神经元输出为0,但又不影响总的输出期望值
13.1.7 Understanding dropout
为什么 dropout正则化网络可以减少网络过拟合的风险?
(1)随机的删除神经单元,反映射回去,相当于输入了不用的数据,即增加了训练数据的多样性(数据扩增),使得网络学习到数据中更多一般共同特征;
(2)从网路结构上看,Dropout每次迭代随机删除网络中的神经单元,生成不同的网络结构,这样就相当于训练了多个网络,最后模型输出, 相当于一个平均结果。
14.1.8 Other regularization methods
(1)Data augmentation: 缩放,镜像,裁剪,扭曲(distortion)
(2)Early stopping:
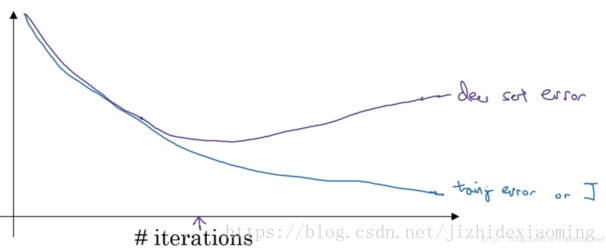
在训练中,我们希望在中间箭头的位置停止训练。而Early stopping就可以实现该功能,这时获得的模型泛化能力较强,还可以得到一个中等大小的w(随着网络的训练,相对于初始化值,w值会不断变大)
可以用L2正则化代替early stopping。L2正则化训练的时间较长,需多试几个lambda,找到得到比较好的结果;early stopping 只需运行一次梯度下降,画出上面曲线,即可找到w的中间值
16.1.9 Setting up your optimization problem / Normalizing inputs
归一化输入:加速训练方法,将数据集归一化为0均值,方差为1
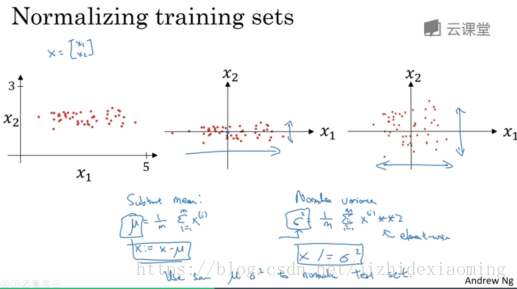
在实际应用中,特征标准化的具体做法是:首先计算每一个维度上数据的均值(使用全体数据计算),之后在每一个维度上都减去该均值。下一步便是在数据的每一维度上除以该维度上数据的标准差。
其中x^i是二维向量,求方差时平方是点乘操作
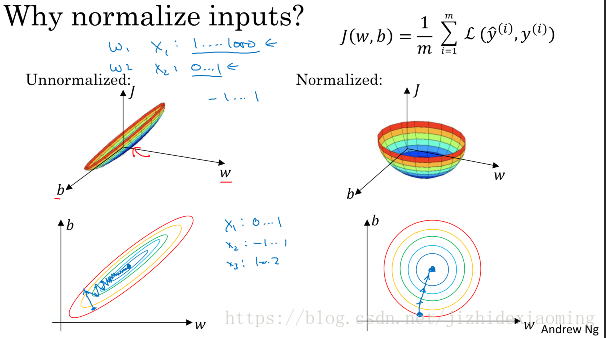
Why normalize inputs?
假设得到的预测函数为:
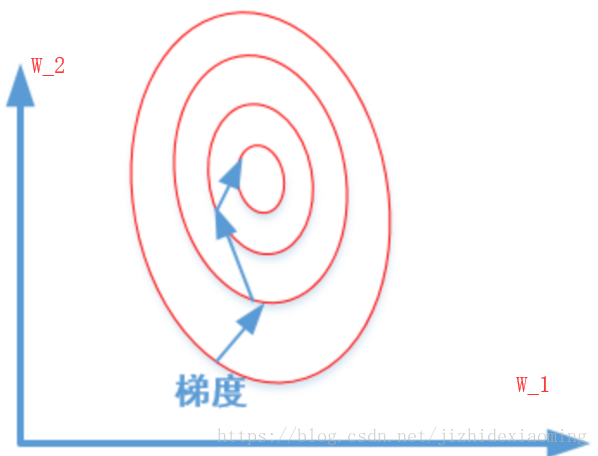
如果不归一化特征,不同特征的值域可能相差较大(特征x1的值域为0-1000,x2的值域为0-1),寻找最优解,即损失函数最小值时,w_1和w_2值也将相差较大,画出损失函数的等高线可能为下图所示,梯度下降过程将走Z字型,速度较慢。
18.1.10 vanishing or exploding gradients
现在假设神经网络如下,简单起见这里没有激活函数,每一层有两个神经元
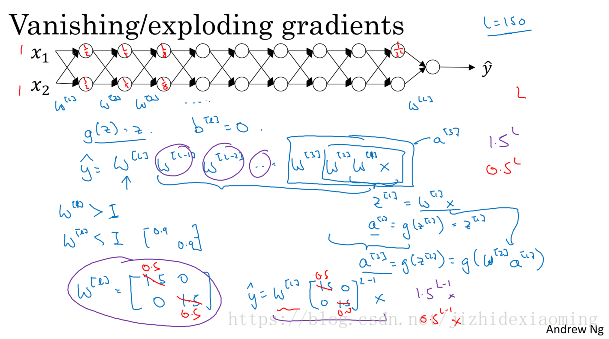
现在假设每一层的权重矩阵为w^l 大于单位矩阵,则连续相乘必然后面的神经元输出非常大,则发生梯度爆炸;每一层的权重矩阵w^l 小于单位矩阵,则连续相乘必然后面的输出非常小,则发生梯度消失
20.1.11 Weight initialization for deep networks
网络输入层为4个神经元,掩藏层有1个神经元,则
如果w过大,z值就会过大更具体地说,在sigmoid(z)和tanh(z)的情况下,如果你的权重很大,z值就会很大,那么梯度将变得很小,从而有效地防止权重改变它们的值。
正确初始化方法:设置权重的方差为2/n; n为输入的神经元个数
26.2.1 Mini-batch gradient descent
Batch vs. mini-batch gradient descent
(1)Batch gradient descent:第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算速度慢,这称为Batch gradient descent,批梯度下降。
(2)stochastic gradient descent:另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
(3)mini-batch gradient decent:为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
Choosing your mini-batch size
(1)如果训练训练集较小,小于2000,则直接batch;
(2)一般的mini-batch size : 64, 128,256,512
30.2.3 Exponentially weighted averages
比梯度下降快,以下是用 指数加权平均值 来拟合趋势
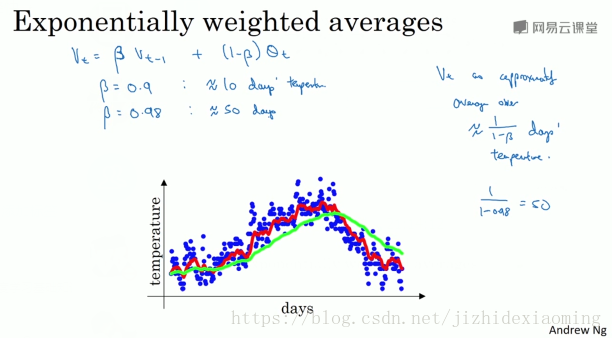
公式:
其中 $\beta=0.9$时,为红色线,$v_{t-1}$是上一天温度,$\theta_t$是当前天的温度,$V_t$是加权后的温度。
当参数为0.9时,接近于平均了1/(1-0.9) = 10天的温度
42.2.9 Learning rate decay
另一个可能加快学习速度的办法是,随时间慢慢减少学习率,即学习率衰减(learning rate decay)
一次遍历全部训练集为一个epoch
学习率:
44.2.10 The problem of local optima
在高维空间,更可能遇到的是鞍点(saddle point),而不是local optima
鞍点是其中几个方向是梯度为0,另一些方向不是;
局部最优是每个方向都是梯度为0;
在高维空间所有梯度方向都为0的概率很小,所以不太可能遇到局部最优问题
真正的问题是 Problem of plateaus
46.3.1 Hyperparameter tuning
超参数调试
,layers, hidden units, learning rate decay, mini-batch size
分级别+网格法
52.3.4 Batch Normalization / Normalizing activations in a network
神经网络每一层z = w*x + b之后,激活函数之前加入Batch Normalizaiton操作:
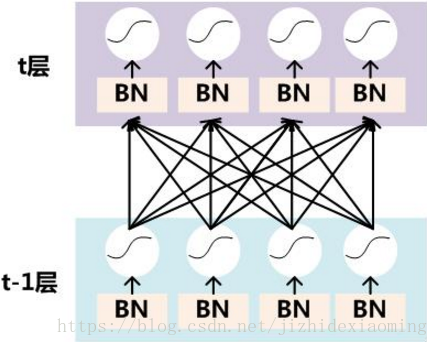
BN可以使某一层的平均值和方差改变。比如激活函数为sigmoid函数,为了不让值总是分布在中间比较线性的区域,通过BN,可以改变横轴 z 的分布区间,以便更好的利用非线性的sigmoid函数;如果,且
,则
,BN后均值为0,方差为1;但如果这两个参数使其他值,则均值和方差就会是其他值;
或者一句话:BN使掩藏单元的均值和方差标准化;
56.3.6 why does Batch Norm work? (为什么batch norm起作用)
58.3.7 Batch Norm at test time
训练时,均值和方差是在整个mini-batch(比如64个样本)上计算出来的;而测试时,可能需要逐一处理样本,方法就是根据训练集估计均值和方差,估计方法有很多,通常会有默认的估算均值和方差的方法。实际操作中,我们通常运用指数加权平均来追踪在训练集中的均值和方差。
60.3.8 Softmax regression
逻辑回归(sigmoid回归)的一般形式,Softmax回归,应用于多分类问题。
65.3.10 Deep learning frameworks
- Caffe/Caffe2
- CNTK
- DJ4J
- Keras
- Lasagne
- mxnet
- PaddlePaddle
- Tensorflow
- Theano
- Torch
待续。。。