第一周:深度学习的实用层面
1.数据集的划分:过程一般是训练集进行训练,验证集进行模型的迭代验证寻找最好的模型,最后在测试集上无偏评估。
当需要无偏估计时:划分为训练集,验证集,测试集
不需要无偏估计时:也可以划分为训练集和验证集
2.对于偏差和方差的问题,高偏差对数据的拟合不够好-欠拟合,高方差则是过拟合。
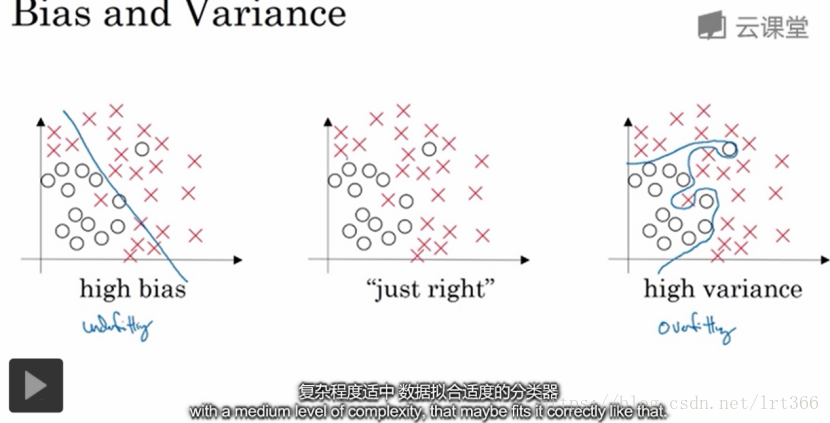
为了理解偏差和方差,需要理解训练集错误率和验证集错误率。

如果最优误差(贝叶斯误差,比如说人眼的误差)为0,且训练集和验证集来自同一分布,如图:
(1)高方差:如果训练集上的错误率很低但验证集上很高,则我们过拟合了训练集的数据,而验证集没有充分交叉验证
(2)高偏差:训练集上的错误率高,验证集上错误率只比训练集高一点点,我们欠拟合训练集
(3)高方差,高偏差:训练集上的错误率高,验证集上的错误率更高
(4)低方差,低偏差:训练集,验证集上的错误率都很低
3.不同解决方法:
(1)检查训练集性能,对于高偏差(欠拟合):需要重新选择算法,扩大网络规模(选择深度的隐藏单元更多的神经网络等),或花更多时间训练
(2)解决了欠拟合之后,一旦偏差降到可接受范围,再检查验证集方差,如果验证集的方差高(过拟合),解决方法一般是寻找更多的数据,或者正则化来减少过拟合
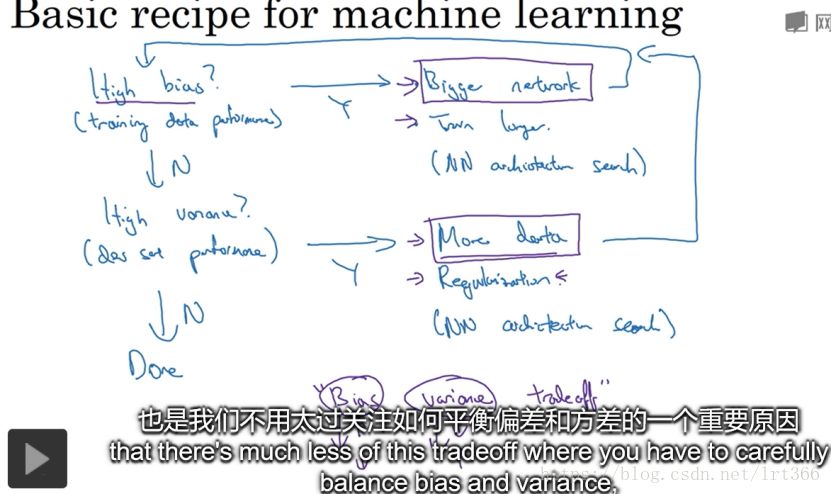
4.正则化一般是给W做约束,因为W是一个包含了绝大部分的参数的权重矩阵,b则是一个参数,对结果没什么影响,logistic回归一般用L2范数,而神经网络的L2范数则叫做弗罗贝尼乌斯范数(frobenius)
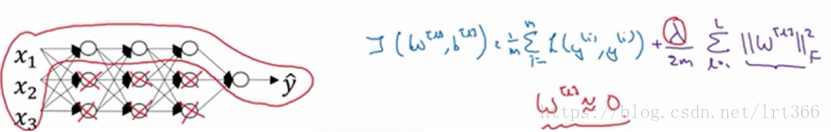
为什么设置正则化可以防止过拟合?直观上理解就是如果正则化参数λ设置地足够大,权重矩阵W被设置为接近于零的值,直观上说就是把各个隐藏单元的权重设为0,于是消除了这些权重单元的许多影响,于是这个网络则被简化为一个较小的网络,小到如同一个逻辑回归单元,但深度却很深,于是可以把模型向高偏差的状态引导,我们要寻找一个λ,让模型适度拟合。
5.dropout正则化(随机失活):
(1)反向随机失活(inverted dropout)如下,通过除keep_prob保持a[3]的期望不变

Dropout在一般在训练阶段采用,而测试阶段不用,因为我们需要测试的预测值是一个固定的而不是随机的值。
6.其他的一些正则化方法
(1)人工扩充训练集(data augmentation),比如对图片进行翻转,裁剪。但要保证猫的图片翻转后还是猫(所以只能水平翻转),以及裁剪后猫还在图片上。
()提早停止训练神经网络(early stopping),但有一个缺点是如果提早停止训练神经网络,那么cost也停止下降了。但比L2正则化的优点是只需一次梯度下降,而L2需要多次训练寻找合适的λ。
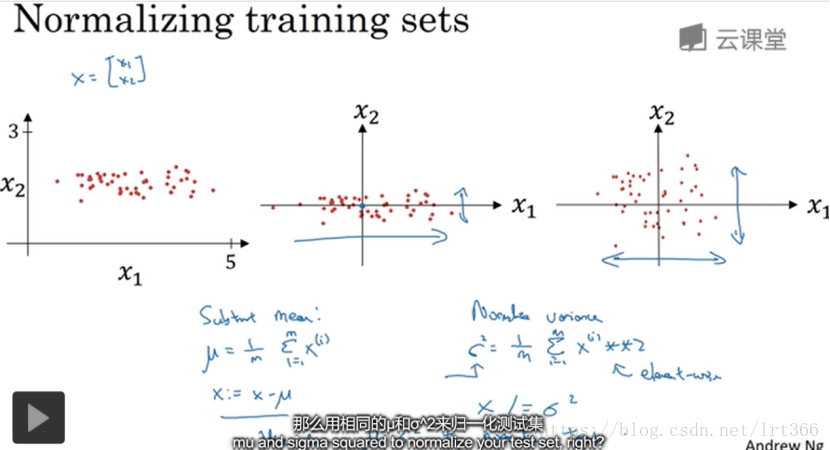
6.归一化训练数据(normalizing training sets):首先让训练数据零均值化,然后让训练数据方差归一化,记得测试集也要这样做。归一化输入能够让代价函数更对称更圆更好优化(前提是特征的输入范围相似,比如x1:1~2, x2:3~4)
7.梯度消失和梯度爆炸,是指激活函数以指数增长(W > I[单位矩阵])或下降(W < I[单位矩阵])的情况

为了处理这个问题,一个不能完全解决但有效果的方法是进行W权重初始化的正则

8.进行梯度检验时,双边误差比单边误差误差小,梯度检验能够帮助我们发现反向传播是否正确,但不要在训练过程中使用梯度检验,梯度检验仅用于调试。如果dθapprox[i]和dθ的值相差很大,则要查找不同的i值,看看是哪个导致的,检查bug

进行梯度检验时有几个要注意的要点:

第二周:优化算法
1.怎么选择mini-batch大小:
mini-batch=m(样本总数)------batch梯度下降法
mini-batch=1------随机梯度下降法

2.指数加权平均:占用的内存小,不用储存很多数据,只要不断覆盖原有数据就行。β =0.9时相当于计算了当前值的前十个之内的值的平均值(0.9^10《0.34的权重视为无足轻重)

3.指数加权平均的初期误差很大,如果在乎初期的误差,可以用偏差修正的方法来减少初期的误差。偏差修正如下

4.优化算法动量梯度下降法(momentum梯度下降法),用指数加权平均的思想,可以减少梯度下降法的下降时的波动,使下降的速度更快。算法如下

5.RMsprop(均方根):为了防止b方向上的波动过大,可以通过计算S值,让梯度下降值除S的平方根,如果b方向的波动大则S的平方根也大,则b方向的梯度下降减少的值变小,这样就实现了让波动平缓的目的。
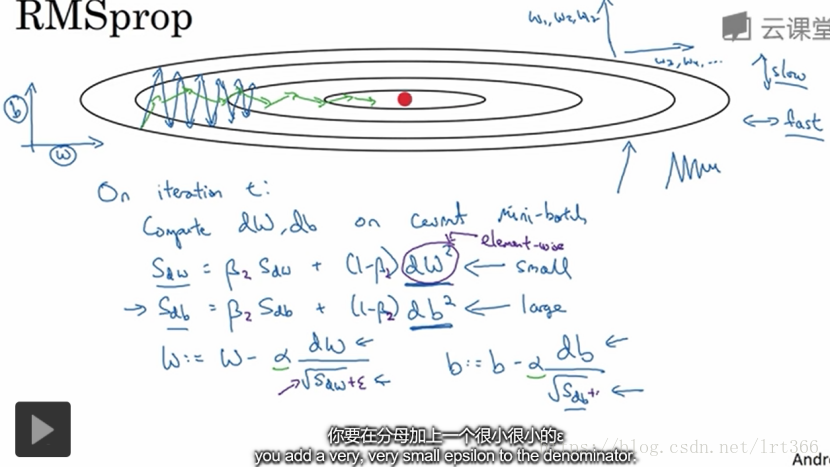
6.Adam优化算法:Adam基本就是将RMsprop和momentum结合起来

7.学习率衰减可以防止优化算法无法到达最低点
8.优化算法面临的问题:鞍点,局部最优解,平缓部分的训练过慢等。
第三周:超参数调试、Batch 正则化和程序框架
1.对于需要调整的参数,红色框住的是最重要的,橙色是其次重要的,紫色是第三重要的参数。无疑学习率a是最重要的。
2.对于超参数的取值验证,采用随机取点大方法比网格的方法更容易找到效果好的取值。
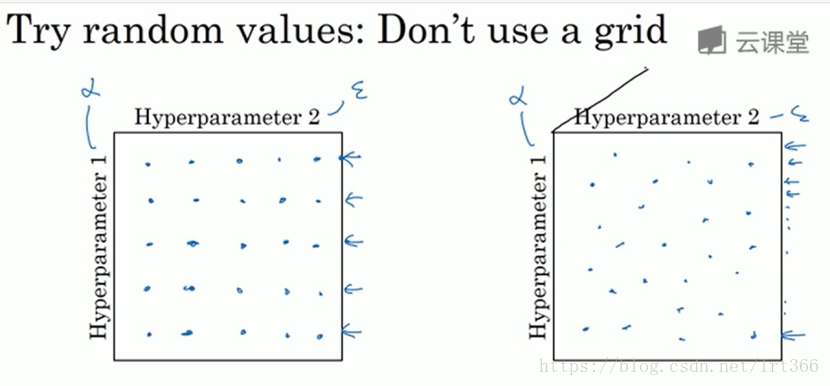
在深度学习中我们一般采用由粗到细的取值范围,先在较大范围内取值,然后在取得较优值的地方划更小范围的取值区域。

2.在超参数搜索的过程中,我们要根据参数的性质选择合适的标尺,因为参数在不同的范围内的敏感度有可能不一样,比如β用指数坐标尺就比较合适

3.batch正则化

它使得前层参数的改变对后层的影响变小了,使后层更稳定,使得网络各层都可以自己学习,稍稍独立于其他层,有助于加速整个训练的过程。
另外,它还有轻微的正则作用

在batch正则化方法中,b不起作用,注意,这里的β和momentum的β没有任何关系。

相对的,b的偏置作用由β代替

4.softmax激活函数和别的激活函数区别在于softmax函数的输出是一个n*1的向量,别的则是一个值,因此 softmax激活函数可以用于多分类任务,softmax将logistic回归推广到了多分任务
