DeepLearning.AI 改善深层神经网络:超参数调试、正则化以及优化 Week2 1-5
目录
Mini-batch 梯度下降
指数加权平均以及偏差修正
Mini-batch 梯度下降
Batch 梯度下降vs Mini-batch 梯度下降
-
什么是Batch 梯度下降?
Batch梯度下降就是我们最一般的梯度下降方法,这种方法讲每一组数据作为输入矩阵的一个列向量,将所有的列向量线性组合成一个矩阵,作为神经网络的输入。 -
什么是Mini-Batch梯度下降?
Mini-Batch梯度下降是将数据集分解成N个小的数据集,每个数据集由M条数据组成( , … ),这里面的上角标代表的是一个由第L个数据集(1<=L<=N)的M条数据组成的一个矩阵。每次在进行梯度下降的时候,我们不再像Batch梯度下降那样使用所有数据进行梯度下降,而是依次采用 , … 进行梯度下降,这样减少了内存的使用,提高了计算效率。 -
Batch梯度下降和Mini-Batch梯度下降的优劣
- 因为Batch梯度下降只有一个大的数据集,所以它会每次都沿着每次迭代梯度最大的方向下降,最后达到一个最值;而Mini-Batch梯度下降是由多个较小数据集构成的,不同数据集间存在一定差异,所以表现出的总体效果是“抖动着”的下降,这里的抖动是指这种方法损失函数的下降存在噪声,从而在接近最值的附近可能无法收敛,而是在一个区间内不断抖动,如下图所示:
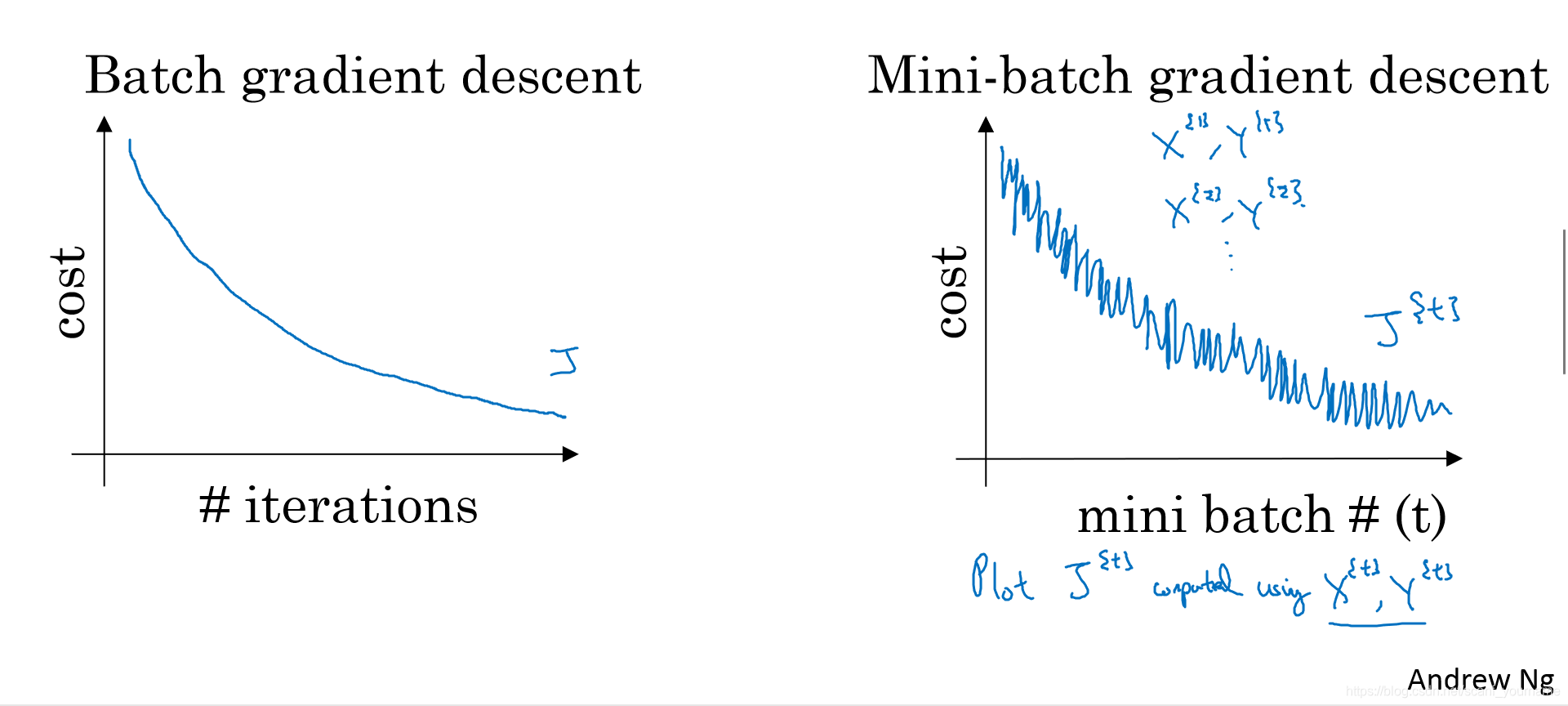
2.Mini-Batch较Batch梯度下降的另一个劣势就是它很难选择一个全局的学习率 ,这种劣势来源于不同数据集之间的差异性,虽然在后续课程中我们会学习一些优化梯度下降的方法,但是这一问题依旧很难避免
3.Batch梯度下降的问题在于在处理大量数据会造成内存不足和计算时间过长的问题,这不得不让我们采用Mini-Batch梯度下降。
Batch-Size的选取
- Batch-Size 选取过大就会产生像Batch梯度下降那样的内存 不足和学习周期过长等问题
- Batch-Size选取过小会产生噪声过大,甚至梯度下降最终无法收敛于极值的问题,这是因为不同数据的存在一定的差异性,每次梯度方向不能很好的代表整体的梯度下降方向。产生的情况如下图紫色线所示:
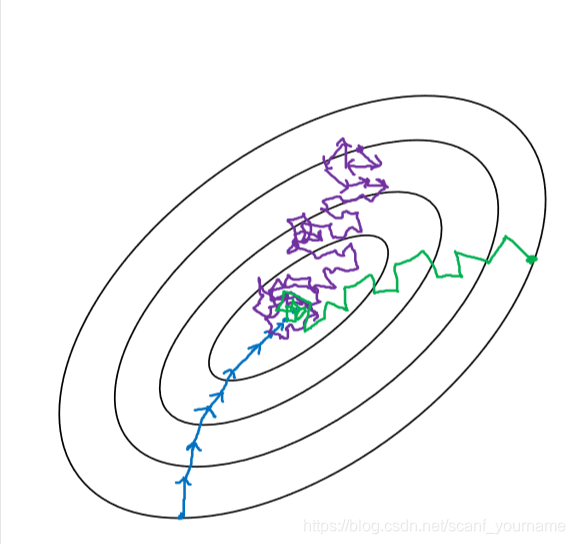
- 所以选取适当的Batch-Size是很必要的,一般我们选取Batch-Size是 (n=6,7,8,9,10)。当然我们也可以根据具体情况调节这个超参数
指数加权平均以及偏差调整
什么是指数加权平均
指数加权平均是一种最初出现在统计学中的加权平均方式,它的目的是让下一个输出的数据和前面若干个状态都相关,考虑到相邻较近的数据影响大,相邻较远的数据影响小的问题,对不同距离的数据进行指数加权,这里我们运用于深度学习中为了优化梯度下降算法。它有一个具体的计算公式,我们会在下面展示这个公式并分析公式的具体意义。
指数加权平均的公式
- 指数加权每一次迭代需要输入一个数据,首先我们规定
代表第i个经过迭代输出的数据,
代表第i次的输入数据。此外我们还有一次参数
,这个参数表征的是我们给的权值,则关于第i次指数加权平均的公式为:
= +(1- )
对于指数加权平局公式的理解
-
为了便于理解我们引入一个关于伦敦一年温度情况的指数加权平均的实例,如下图所示:
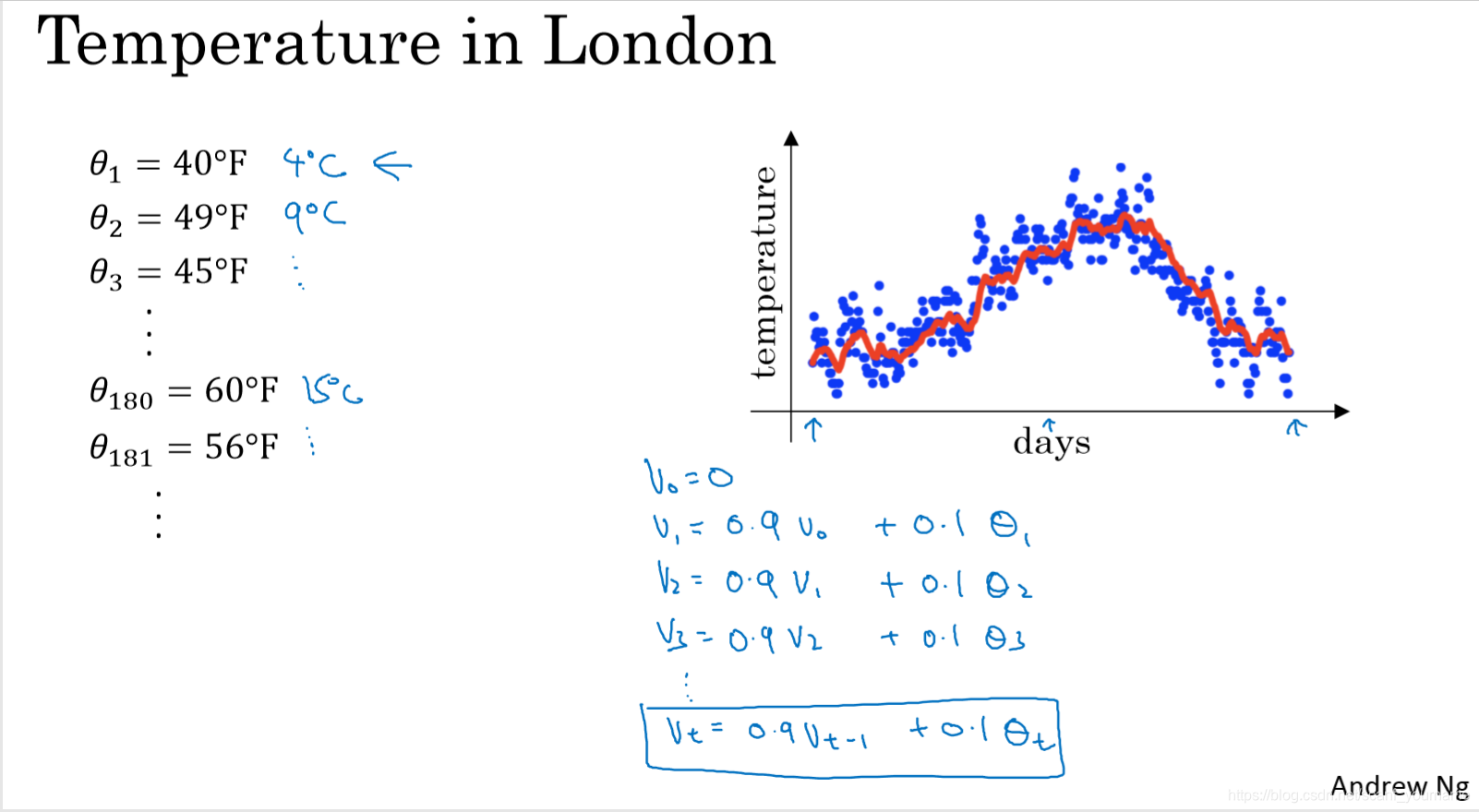
在上图中,蓝色的圆点就是每天温度情况组成的离散点迹,红色线是由指数加权平均拟合出来的指数加权移动平均线。 = F, = F… = F这些就是一些输入数据,左下角是由指数加权平均公式计算出来的数据。 -
参数 表示的是什么?
要回答这个问题我想我们有必要推导一下 的通项公式,我在下面做了一些展开,在这里直接给出结论:
=
注意这里面为什么要将 单独提出来呢?因为 不是来自于输入,其他变量均来自输入。在我们的实际应用中要把 初始化为0,所以经过调整后的公式为:
=
观察上面公式我们发现, 的实际值受到前面所有输入的影响,但是越早出现的变量占比越小,我们考虑一个边界,当小于这个边界值的时候就可以近似忽略这个变量的影响。
在微积分中我们学过一个重要极限:
在我们的问题中如果 取值接近于1,
= =
=
所以我们认为当这一项的权值小于 的时候就忽略这一项以及其之前的输入对于当前值的影响。
所以我们可以得出这样的结论: 越大,则它对应的指数加权平均值受到之前影响的项数就越多,曲线就越趋于平缓。 -
如何调节参数 ?
在前面我们谈论过 的意义,由 的意义我们知道当曲线的 趋近于1的时候曲线受到太多的输入影响,导致曲线过于平缓没有办法很好的表现输入的特征
当 过小的时候,曲线可能会呈现出跳跃的变化,出现好多的毛刺不够平滑。
所以选择一个合适的 是很重要的,万幸在实际测试中 具有比较良好的效果,所以我们在一般情况下可以采用它。
指数加权平均偏差的修正
指数加权偏差产生的原因
不知道你有没有注意到一个问题(我在看这节mooc之前一直有这个疑问),那就是默认初始化
会导致最开始几项的值非常小,和实际偏差巨大。这是为什么呢?
我们假设
,
=
+(1-
)
这里面0.9的值都被
占据了,导致
所占权重很小。
其实后面几项也一直都有这样的问题。
如何修正偏差?
这里所说的修正方法我觉得是一种正则化方法。
我们观察
=
这个式子中
是无效的权重,这种无效权重随着迭代影响越来越小,它所占比例为
,对应的有效成分是
。所以,我们令
这样得到的就完成正则化过程了。