机器学习的应用是一个高度依赖经验的过程,伴随着大量的迭代过程,你需要训练大量的模型才能找到合适的那个,优化算法能够帮助你快速训练模型。
难点:机器学习没有在大数据发挥最大的作用,我们可以利用巨大的数据集来训练网络,但是在大数据下训练网络速度很慢;
使用快速的优化算法大大提高效率
mini-batch梯度下降法
向量化能让你有效的对所有的m个例子进行计算,允许你处理整个训练集而无需某个明确的公式。
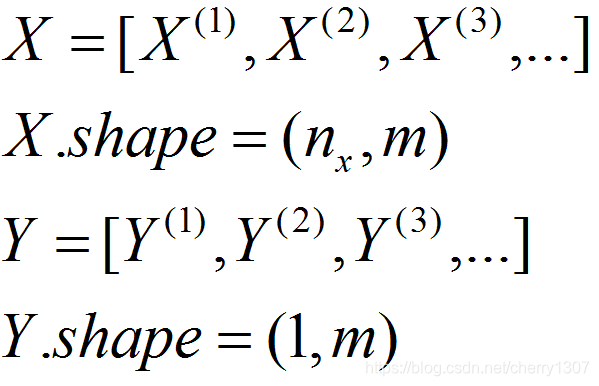
m很大时,处理速度非常慢
在对整个训练集进行梯度下降时,必须处理整个训练集,才能进行下一步梯度下降。
假设有500万个数据,必须处理完500万个数据,才能进行下一步梯度下降。
mini—beach
将训练集分成小一点的子集
将500万个数据没1000个分为一组,分为5000个子集
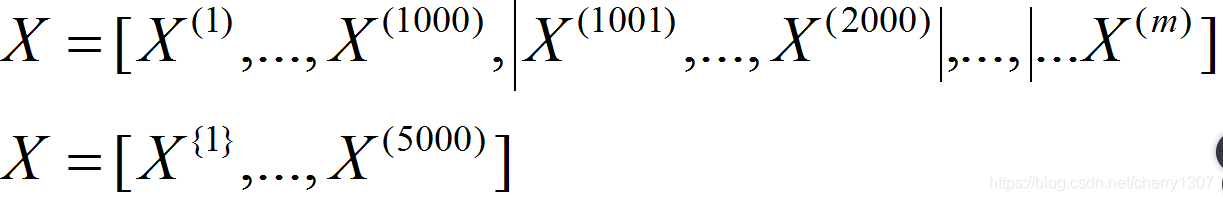
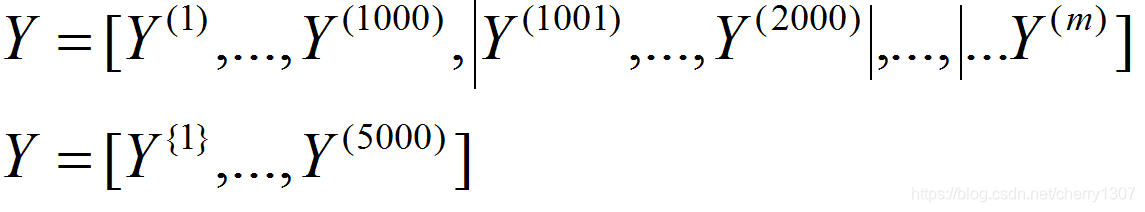
mini—beach的数据集就变成了X^{t},Y^{t}
X^{1}Y^{1}中有1000个样本
同时处理单个mini-batchX^{t},Y^{t}
#算法
{
for t = 1,...,5000{
#forward propagation on X^{t}
#向量化处理1000个样本
Z^[l] = W^[l]*A^[l-1]+b^[l]
A^[l] = g^[l](Z^[l])
#cost function
cost = 1/1000*sum(L(yhat{t}-y{t}))+lamabd/(2*1000)*sum||w^[t]||^2
`#backward propagation
dAL = dL(AL,Y)/dAL
dZ^[l]=g'^[l]*dAL
dW^[l]=dZ^[l]*A^[l-1]T
db^[l]=dZ^[l]
dA_prev = dZ^[l]T*W^[l]
#mini-batch
W^[l]=W^[l]-alpha*dW^[l]
b^[l]=b^[l]-alpha*db^[l]
}
}
梯度下降:一次遍历训练集,只能让你做一个梯度下降
mini-batch:一次遍历训练集,做5000个梯度下降
多次遍历训练集,最外层还需要一个while/for循坏,使能收敛到一个合适的精度。
理解mini-batch剃度下降法
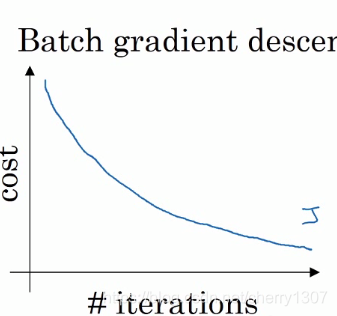
梯度下降法
mini-batch梯度下降法
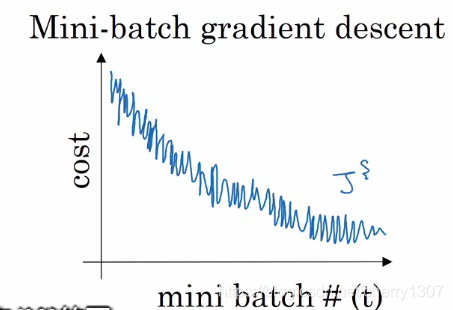
趋势向下
mini-batch的size
if mini-batch size = m --> 梯度下降法
相对噪音低,幅度大,单次迭代耗时长
if mini-batch size = 1 -->随机梯度下降法
噪音大,最终靠近最小值有时偏离,因为它永不收敛
失去向量化带来的加速
mini-batch size 介于1,m之间
怎样寻选择m?
if small train set:(<2000)
梯度下降
typical mini-batch size:
64(2^6) 128(2^7),256(2^8),512(2^9)
x^{t},Y^{t}符合CPU、GPU内存
指数加权平均
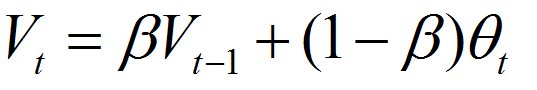
V^theta = 0
repeat{
get next theta^t
V^theta := bata*V^theta + (1-bata)*theta^t
}
指数加权平均的偏差
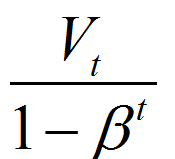
动量梯度下降法
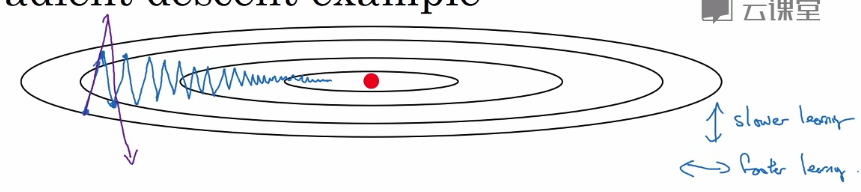
在纵轴上,希望学习慢一点
在横轴上,希望学习快一点
动量梯度下降法:
V_dW= 0
V_db = 0
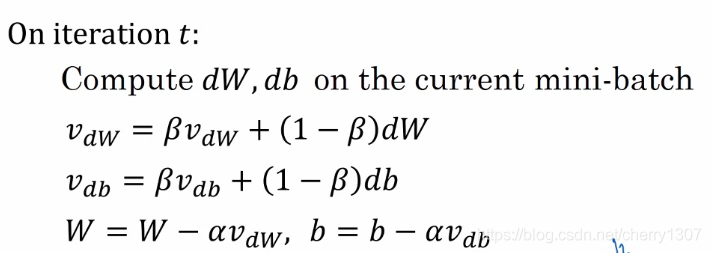
超参数:alpha,bata
bata一般取0.9
RMSprop
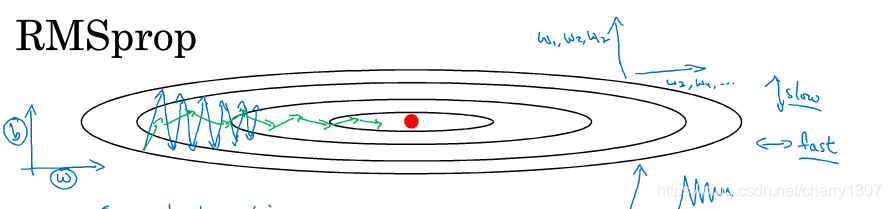
消除摆动
允许使用更大的学习率
On iteration t:
compute dW,db on current mini-batch
S_dw = bata_2*S_dW + (1-bata_2)*(dW)^2
S_db = bata_2*S_db + (1-bata_2)*(db)^2
W := W - alpha*dW/(sqrt(S_dW)+e)
b:= b - alpha*db/(sqrt(S_db)+e)
adam优化器
S_dW =0,S_db = 0,V_dW =0,V_db = 0
On iteration t:
compute dW,db on current mini-batch
V_dW = bata_1*V_dW + (1-bata_1)*(dW)^2
V_db = bata_1*V_db + (1-bata_1)*(db)^2
S_dW = bata_2*S_dW + (1-bata_2)*(dW)^2
S_db = bata_2*S_db + (1-bata_2)*(db)^2
V^vorrect_dW = V_dW/(1-bata_1^t) V^vorrect_db = V_db/(1-bata_1^t)
S^vorrect_dW = S_dW/(1-bata_2^t) S^vorrect_db = S_db/(1-bata_2^t)
W := W - alpha*V^vorrect_dW/(sqrt(S^vorrect_dW)+e)
b := b - alpha*V^vorrect_db/(sqrt(S^vorrect_db)+e)
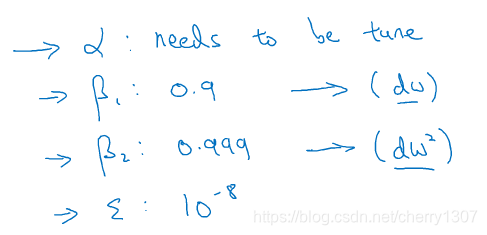
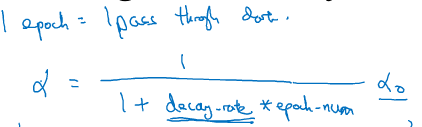
学习率衰减
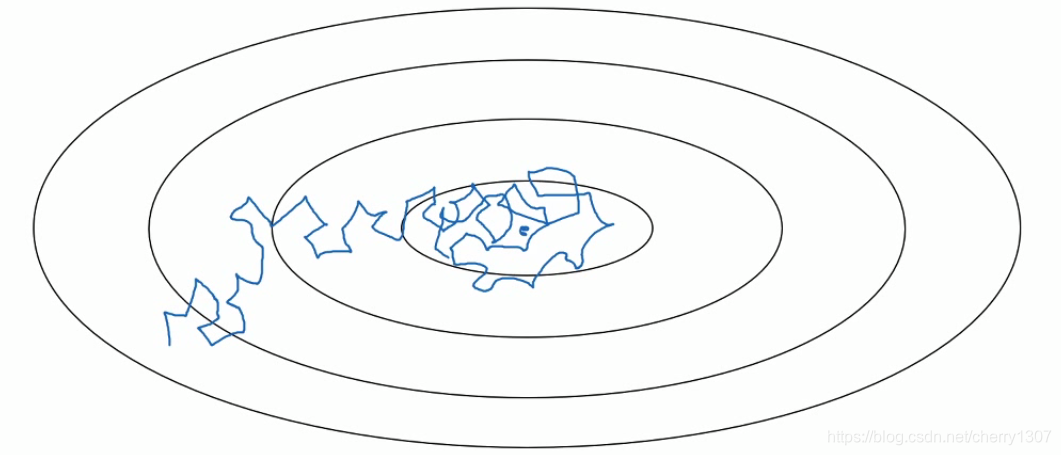
有时候使用固定学习率,在不会收敛
使用衰减的学习率,在学习初期,能承受较大的步伐,但当开始收敛的时候,小的学习率会让步伐变小