调试处理
一般情况下,需要调试的超参数顺序:
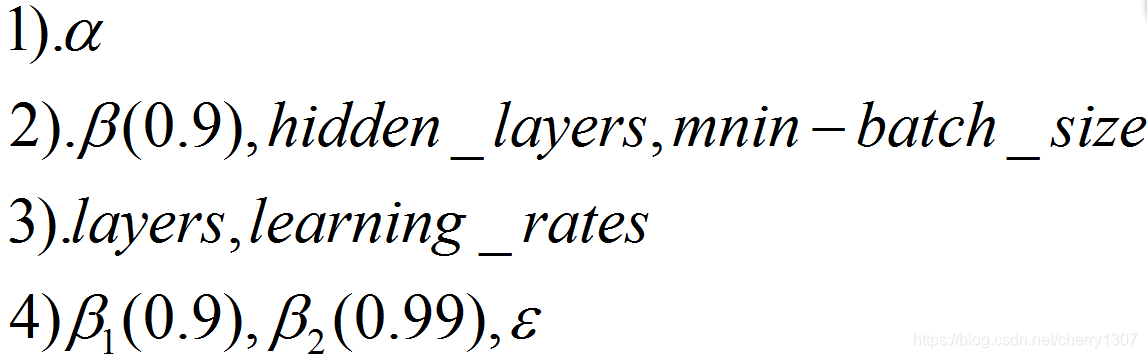
怎样调试:
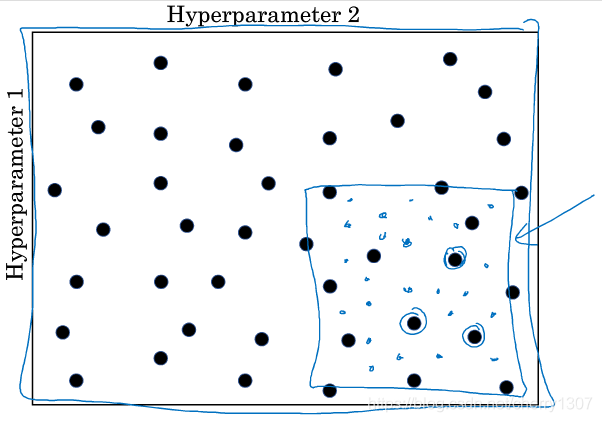
在一个范围内,随机取值

先大范围随机取值,然后局部取值
为超参数选择合适的范围
1.节点个数、网络层数——>随机均匀取值
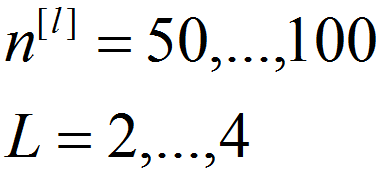
2.α——>随机对数取值
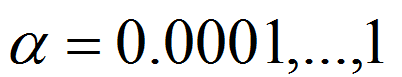
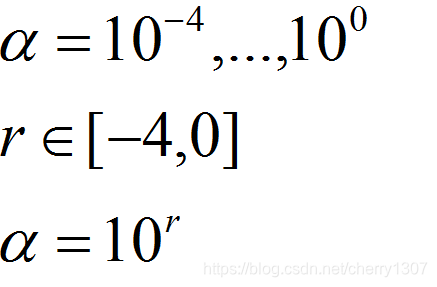
r=-4*np.random.rand()
alpha = 10^r
3.β
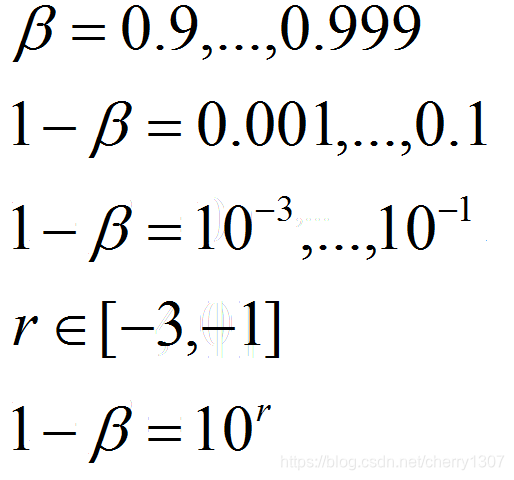
β在接近1的时候会很敏感,可以更密集的取值
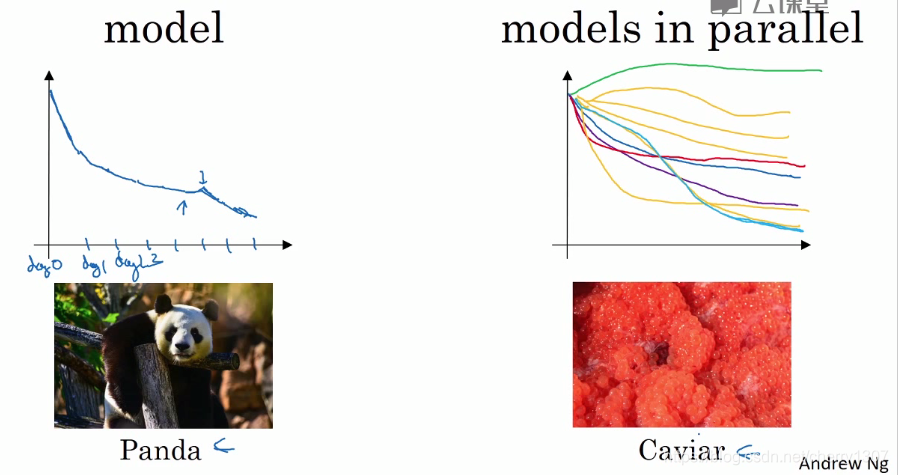
超参数的网络实践:pandas VS caviar
pandas:照料一个模型,观察他的表现啊,耐心的调试学习率,但通常因为没有足够的计算能力,不能在同一时间试验大量的模型时使用
train many models in parallel:同时试验多种模型,设置一些超参数,让他们运行一天或几天,你会获得他们的学习曲线,然后选择工作效果最好的那一个。
正则化网络的激活函数
在Logistic回归中,我们用归一化网络输入来加速学习:
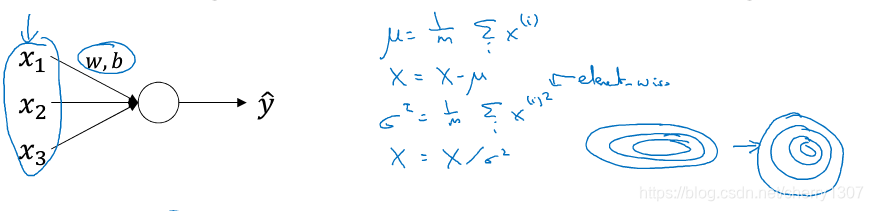
在如下深度神经网络中,若想训练W[3],b[3],归一化A[2] (Z[2])
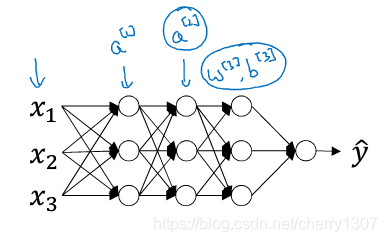

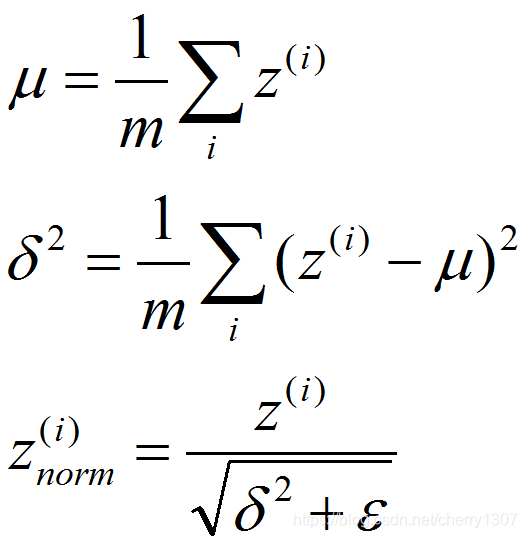
不想让隐藏单元总是均值为0,方差为1
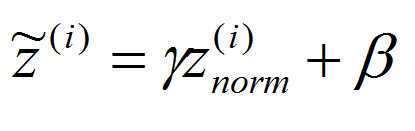
其中:
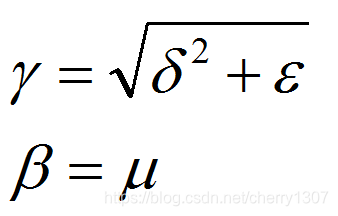
使用γ和β构造含有其他均值和方差的隐藏单元

batch归一化不只适用于输入层还适用于隐藏层
将batch norm拟合进神经网络
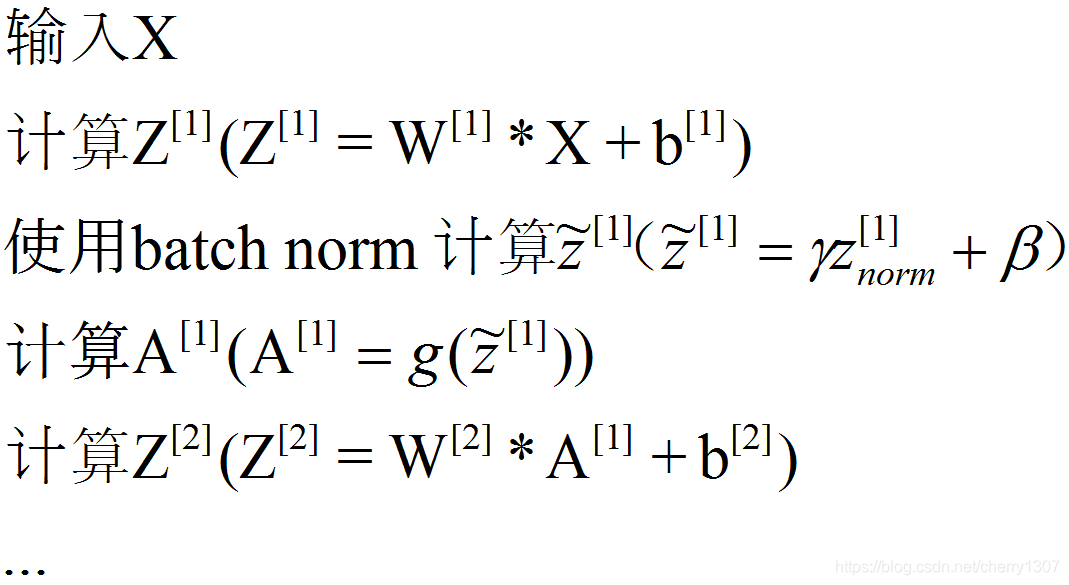
参数:W[1],γ[1],β[1],…,W[l].b[l],γ[l]
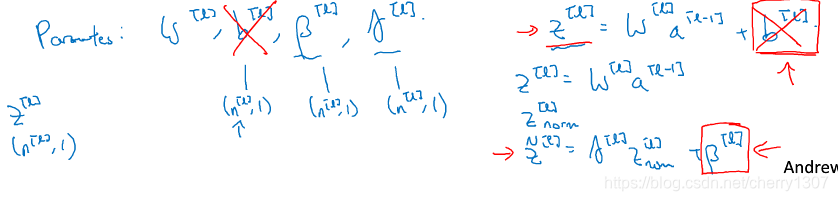
在tensorflow中:
tf.nn.batch_normalization
for t = 1 ......mini-batch:
前向传播:
X^{t}j进行前向传播,应用于每个隐藏层,将Z^[l]转换为Z~^[l]
反向传播:
计算dW[l],dβ[l],dγ[l]
W[l] = W[l]-alpha*dW[l]
β[l] = β[l] -alpha*β[l]
γ[l] = γ[l]-alpha*γ[l]
也适用于momentum,RMSprop,Adam
batch Norm 为什么有效?
batchNorm一次处理一个mini_batch
1.加速学习
2.减少前层参数与后一次的联系(均值和方差不变)
测试时的batch Norm
测试一般为单个样本测试,但单个样本的均值和方差无意义。
使用训练样本估计均值和方差,再应用于测试。
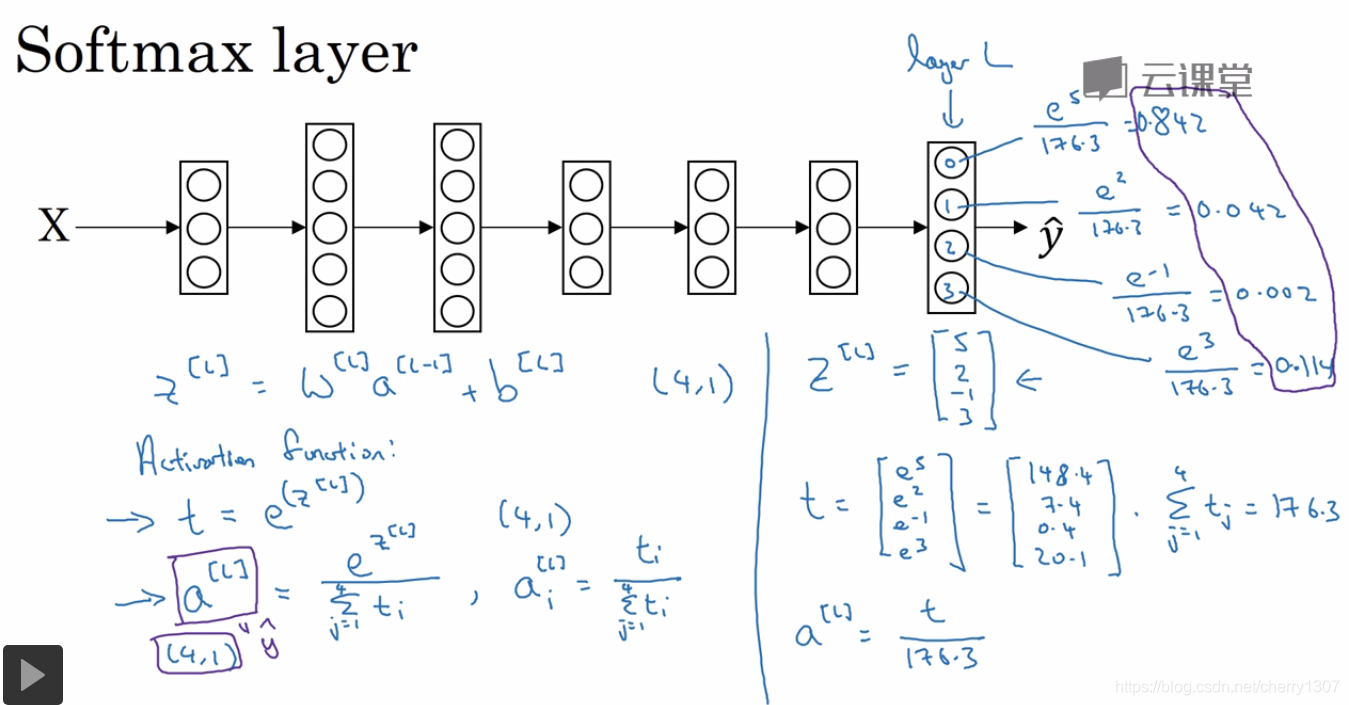
softmax回归