这是吴恩达深度学习第二模块第二周的内容,刚开始学习,文章里应该会有些理解错误的部分,多谢告知,qq: 2690382987
蓝色字体是我自己的理解, 红色字体是疑问待补充的,其他内容为对课程知识点的梳理。
为了加快训练速度,使用一些优化算法。
Mini-batch 梯度下降
- batch梯度下降法(梯度下降法):同时处理整个训练集。
- mini-batch梯度下降法:同时处理的是单个Mini-batch里的样本
- 随机梯度下降:一次处理一个样本
- epoch :遍历训练集的次数 batch梯度下降法:epoch=1,做一次梯度下降
mini-batch梯度下降法:epoch=1,做很多次梯度下降
mini-batch尺寸:
- 训练集较小(小于2000个样本):使用batch梯度下降法
- 样本数目较大:mini-batch大小为:64-512,一般设置为64,128,256,512,设为1024比较少见。
mini-batch的符号表示,令每个Mini-batch包含的样本量为1000,总样本量500万,则:

下面介绍几个比梯度下降速度更快的优化算法,在这之前先介绍指数加权平均数。
指数加权平均数(在统计上被称作指数加权移动平均值)

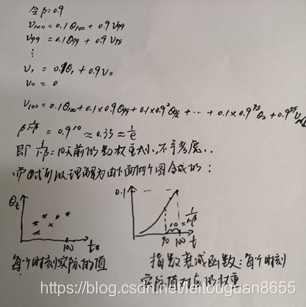
指数加权平均的偏差修正
用上面的方式计算出来的指数加权平均数,在开始那些数据上偏差较大,如果你的功能关心初始时候的偏差,那便需要对初始的计算结果做偏差修正。
修正公式:

动量梯度下降法
目的是为了使纵轴方向的摆动幅度小些,横轴方向运动地更快,所以和梯度下降相比,这种方式学习速度更快。它不像梯度下降法每一迭代都只和当前有关,和上一个迭代无关,动量梯度下降法的每一步是当前和之前步的加权平均计算出来的。

计算公式:

上图里有两个超参数,吴老师建议β取0.9,即平均了近十次迭代的梯度。一般不需要做偏差修正,因为迭代10次后移动平均已经过了初始阶段。
v_dw的初始值是和w相同维数的零矩阵。
v_db的初始值是和b相同维数的零向量。
扫描二维码关注公众号,回复:
11646520 查看本文章

RMSprop
一个加速梯度下降的方法,加速的方式是:使纵轴方向的摆动幅度小些,横轴方向运动地更快(至少不是减缓)。计算公式(费解):

Adam 优化算法
Adam是动量梯度下降法和RMSprop的结合,计算方法:

超参数调试:

学习率衰减
随着时间慢慢减少学习率(学习率衰减)的本质是,在训练初期可以接受较大的波动,但当算法开始收敛时,小一些的学习率会让波动小一些。具体的操作,即计算公式:


局部最优的问题
很小的概率会困在很差的局部最优里,在高维空间更有可能碰到鞍点,而不会碰到局部最优。(这一节很费解)