参考:
吴恩达视频课
深度学习笔记
1. Mini-batch 梯度下降
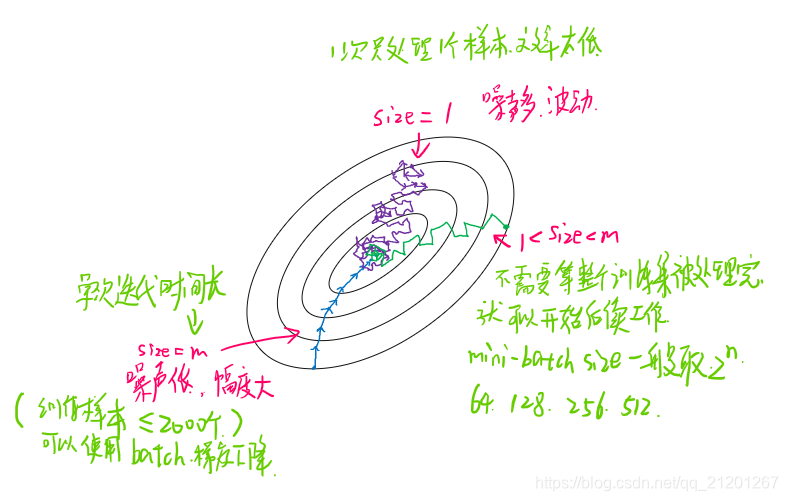
在巨大的数据集上进行训练,速度非常慢,如何提高效率?
前面我们学过向量化可以较快的处理整个训练集的数据,如果样本非常的大,在进行下一次梯度下降之前,你必须完成前一次的梯度下降。如果我们能先处理一部分数据,算法速度会更快。
- 把训练集分割为小一点的子集(称之 mini-batch)训练
batch 梯度下降法:指的就是前面讲的梯度下降法,可以同时处理整个 训练集
mini-batch:每次处理的是单个的 mini-batch 训练子集
2. 理解 mini-batch 梯度下降
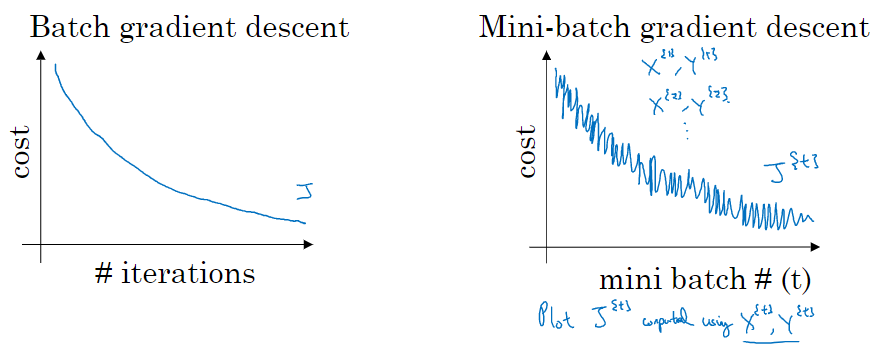
mini-batch 梯度下降,每次迭代后 cost 不一定是下降的,因为每次迭代都在训练不同的样本子集,但总体趋势应该是下降的
mini-batch 的 size 大小:
- 大小 = m,就是batch梯度下降法
- 大小 = 1,就是随机梯度下降
3. 指数加权平均数

假设,
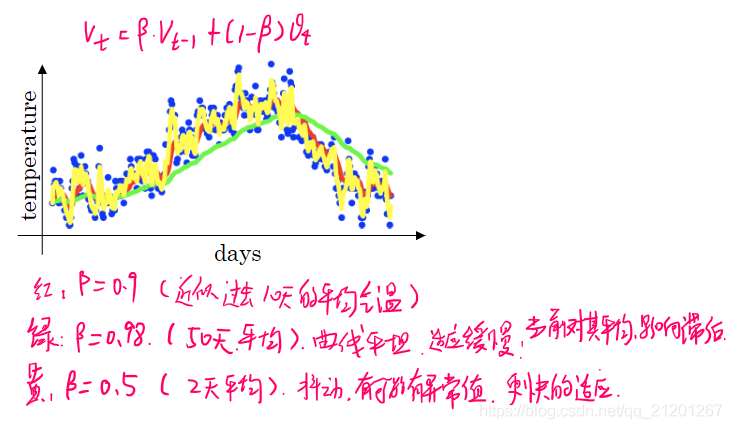
v0=0,vt=β∗vt−1+(1−β)∗θt
选取不同的
β 值,得到相应的气温曲线
4. 理解指数加权平均数
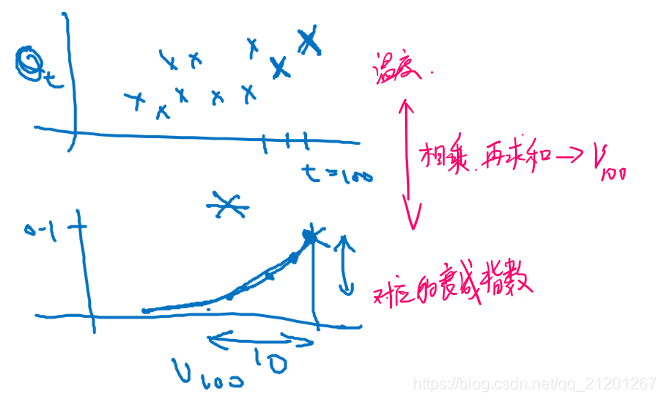
假如
β=0.9,t=100,将上面的带进去求
v100
v100=0.1θ100+0.9(0.1θ99+0.9(0.1θ98+0.9v97))0v100=0.1θ100+0.1×0.9θ99+0.1×(0.9)2θ98+0.1×(0.9)3θ97+0.1×(0.9)4θ96+…
好处:代码简单,占用内存极少
vθ=0,vt:=β∗vθ+(1−β)∗θt
当然,它并不是最好、最精准的计算平均数的方法
5. 指数加权平均的偏差修正
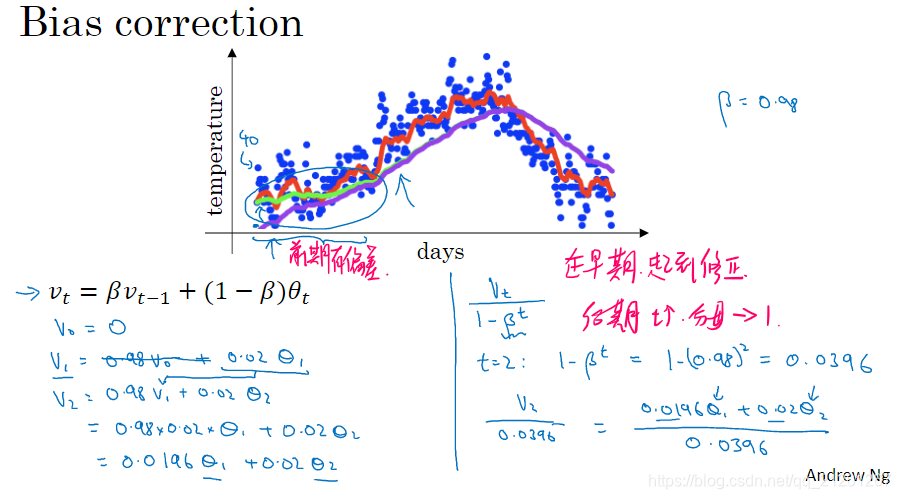
6. 动量Momentum梯度下降法
思想:计算梯度的指数加权平均数,利用该梯度更新权重

上图情况下,标准的梯度下降会上下波动,且要使用较小的学习率,否则会偏离更远。
如果我们使用过去梯度的加权平均,纵向的就抵消了一些,横向的叠加了一些,可以更平滑的快速找向最优点
vdW=βvdW+(1−β)dWvdb=βvdb+(1−β)db
W:=W−α∗vdWb:=b−α∗vdb
- 超参数有
α,
β=0.9(
β 经常取 0.9)
- 如果想偏差修正,
vdW,vdb 还要除以
1−βt,实际上人们不这么做,10次迭代之后,偏差就基本很小了
动量梯度下降法,并不是对所有情况都有效,它对碗状的优化效果较好
7. RMSprop
全称是 root mean square prop 算法,它也可以加速梯度下降
微分平方的加权平均数:
SdW=βSdW+(1−β)(dW)2Sdb=βSdb+(1−β)(db)2
W:=W−α∗SdW
+EdW b:=b−α∗Sdb
+Edb
E=1e−8 保证分母不为 0
RMSprop 跟 Momentum 有很相似的一点,可以消除梯度下降和mini-batch梯度下降中的摆动,并允许你使用一个更大的学习率,从而加快你的算法学习速度。
8. Adam 优化算法
Adam (Adaptive Moment Estimation) 优化算法基本上就是将 Momentum 和 RMSprop 结合在一起
- 初始化:
vdW=0,SdW=0,vdb=0,Sdb=0
- t 次迭代
Momentum:
vdW=β1vdW+(1−β1)dW
vdb=β1vdb+(1−β1)db
RMSprop:
SdW=β2SdW+(1−β2)(dW)2
Sdb=β2Sdb+(1−β2)(db)2
偏差修正:
vdWcorrected =1−β1tvdW
vdbcorrected =1−β1tvdb
SdWcorrected =1−β2tSdW
Sdbcorrected =1−β2tSdb
更新权重:
W:=W−α∗SdWcorrected
+εvdWcorrected
b:=b−α∗Sdbcorrected
+εvdbcorreted
Adam算法结合了 Momentum 和 RMSprop 梯度下降法,并且是一种极其常用的学习算法
其被证明能有效适用于不同神经网络,适用于广泛的结构
超参数:
- 学习率
α
-
β1=0.9,常用
-
β2=0.999,作者推荐
-
ε=1e−8
9. 学习率衰减
慢慢减少 学习率 的本质在于,在学习初期,使用较大的步伐,开始收敛的时候,用小一些的学习率能让步伐小一些
- 对不同的 mini-batch 进行训练,一次称之为 epoch
α=1+decayRate∗epochNum1∗α0
还有些其他的方法:
α=0.95epochNumα0α=epochNum
kα0α=t
kα0,t为mini-batch的数字
还有离散下降学习率,即 不是每步都下调学习率
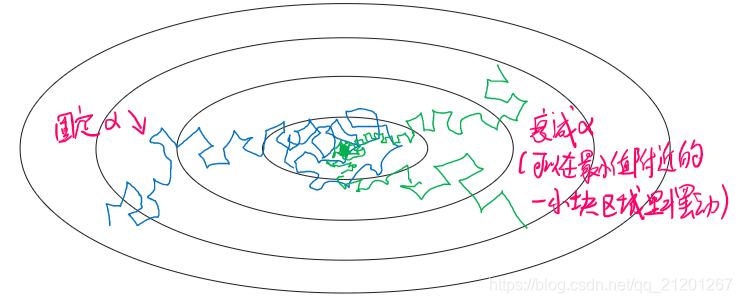
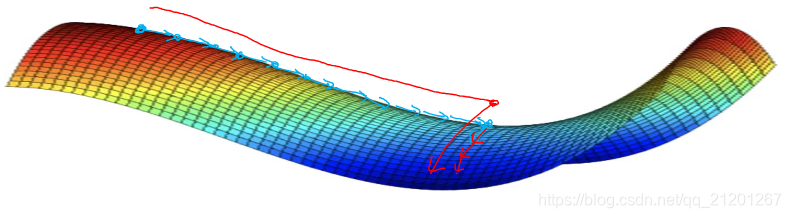
10. 局部最优的问题
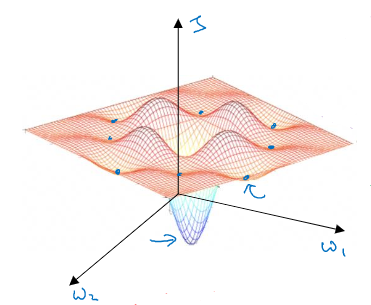
高维度空间中,我们不太可能遇见(概率很低)如上图所示的局部最优点,因为需要这么多的维度方向上都梯度为 0(概率很低)
所以更有可能遇到的是鞍点
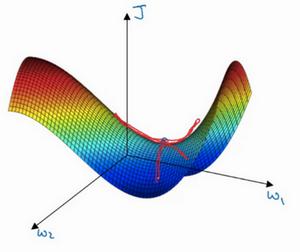
基本不会遇见局部最优问题,可能遇见的是平稳段减缓了学习速度,该区域梯度接近于 0 ,要很长时间才能走出去。Momentum 或 RMSprop,Adam 能够加快速度,让你尽早 走出平稳段。
作业
02.改善深层神经网络:超参数调试、正则化以及优化 W2.优化算法(作业:优化方法)
我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!
