第二周:优化算法 (Optimization algorithms)
2.1 Mini-batch 梯度下降(Mini-batch gradient descent)
2.2 理解mini-batch梯度下降法(Understanding mini-batch gradient descent)
2.3 指数加权平均数(Exponentially weighted averages)
2.4 理解指数加权平均数(Understanding exponentially weighted averages)
2.5 指数加权平均的偏差修正(Bias correction in exponentially weighted averages)
2.6 动量梯度下降法(Gradient descent with Momentum)
2.8 Adam 优化算法(Adam optimization algorithm)
2.9 学习率衰减(Learning rate decay)
2.10 局部最优的问题(The problem of local optima)
2.1 Mini-batch 梯度下降(Mini-batch gradient descent)
本周将学习优化算法,这能让你的神经网络运行得更快。机器学习的应用是一个高度依赖经验的过程,伴随着大量迭代的过程,你需要训练诸多模型,才能找到合适的那一个,所以,优化算法能够帮助你快速训练模型。
其中一个难点在于,深度学习没有在大数据领域发挥最大的效果,我们可以利用一个巨大的数据集来训练神经网络,而在巨大的数据集基础上进行训练速度很慢。因此,你会发现,使用快速的优化算法,使用好用的优化算法能够大大提高你和团队的效率,那么,我们首先来谈谈mini-batch梯度下降法。





使用batch梯度下降法,一次遍历训练集只能让你做一个梯度下降,使用mini-batch梯度下降法,一次遍历训练集,能让你做5000个梯度下降。当然正常来说你想要多次遍历训练集,还需要为另一个while循环设置另一个for循环。所以你可以一直处理遍历训练集,直到最后你能收敛到一个合适的精度。
如果你有一个丢失的训练集,mini-batch梯度下降法比batch梯度下降法运行地更快,所以几乎每个研习深度学习的人在训练巨大的数据集时都会用到,下一个视频中,我们将进一步深度讨论mini-batch梯度下降法,你也会因此更好地理解它的作用和原理。
2.2 理解mini-batch梯度下降法(Understanding mini-batch gradient descent)
在上周视频中,你知道了如何利用mini-batch梯度下降法来开始处理训练集和开始梯度下降,即使你只处理了部分训练集,即使你是第一次处理,本视频中,我们将进一步学习如何执行梯度下降法,更好地理解其作用和原理。
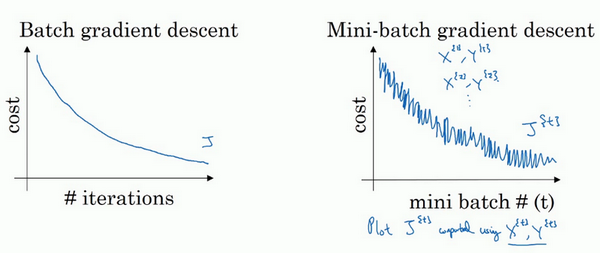



相反,如果使用随机梯度下降法,如果你只要处理一个样本,那这个方法很好,这样做没有问题,通过减小学习率,噪声会被改善或有所减小,但随机梯度下降法的一大缺点是,你会失去所有向量化带给你的加速,因为一次性只处理了一个训练样本,这样效率过于低下,所以实践中最好选择不大不小的mini-batch尺寸,实际上学习率达到最快。你会发现两个好处,一方面,你得到了大量向量化,上个视频中我们用过的例子中,如果mini-batch大小为1000个样本,你就可以对1000个样本向量化,比你一次性处理多个样本快得多。另一方面,你不需要等待整个训练集被处理完就可以开始进行后续工作,再用一下上个视频的数字,每次训练集允许我们采取5000个梯度下降步骤,所以实际上一些位于中间的mini-batch大小效果最好。
用mini-batch梯度下降法,我们从这里开始,一次迭代这样做,两次,三次,四次,它不会总朝向最小值靠近,但它比随机梯度下降要更持续地靠近最小值的方向,它也不一定在很小的范围内收敛或者波动,如果出现这个问题,可以慢慢减少学习率,我们在下个视频会讲到学习率衰减,也就是如何减小学习率。

2.3 指数加权平均数(Exponentially weighted averages)
我想向你展示几个优化算法,它们比梯度下降法快,要理解这些算法,你需要用到指数加权平均,在统计中也叫做指数加权移动平均,我们首先讲这个,然后再来讲更复杂的优化算法。 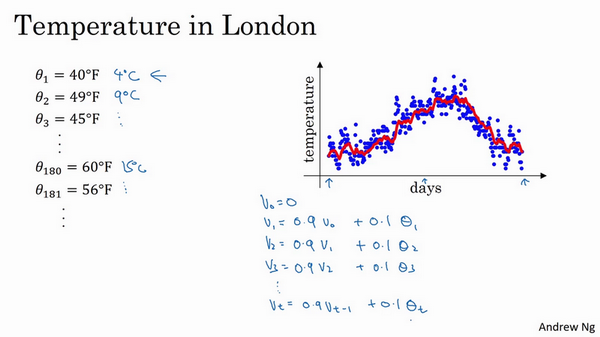 虽然现在我生活在美国,实际上我生于英国伦敦。比如我这儿有去年伦敦的每日温度,所以1月1号,温度是40华氏度,相当于4摄氏度。我知道世界上大部分地区使用摄氏度,但是美国使用华氏度。在1月2号是9摄氏度等等。在年中的时候,一年365天,年中就是说,大概180天的样子,也就是5月末,温度是60华氏度,也就是15摄氏度等等。夏季温度转暖,然后冬季降温。
虽然现在我生活在美国,实际上我生于英国伦敦。比如我这儿有去年伦敦的每日温度,所以1月1号,温度是40华氏度,相当于4摄氏度。我知道世界上大部分地区使用摄氏度,但是美国使用华氏度。在1月2号是9摄氏度等等。在年中的时候,一年365天,年中就是说,大概180天的样子,也就是5月末,温度是60华氏度,也就是15摄氏度等等。夏季温度转暖,然后冬季降温。
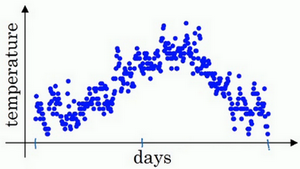
你用数据作图,可以得到以下结果,起始日在1月份,这里是夏季初,这里是年末,相当于12月末。
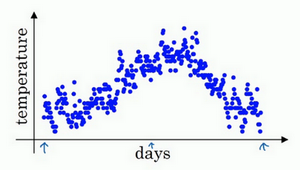
这里是1月1号,年中接近夏季的时候,随后就是年末的数据,看起来有些杂乱,如果要计算趋势的话,也就是温度的局部平均值,或者说移动平均值。
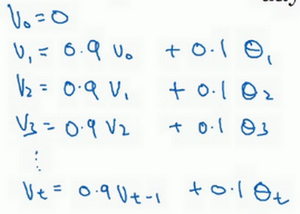

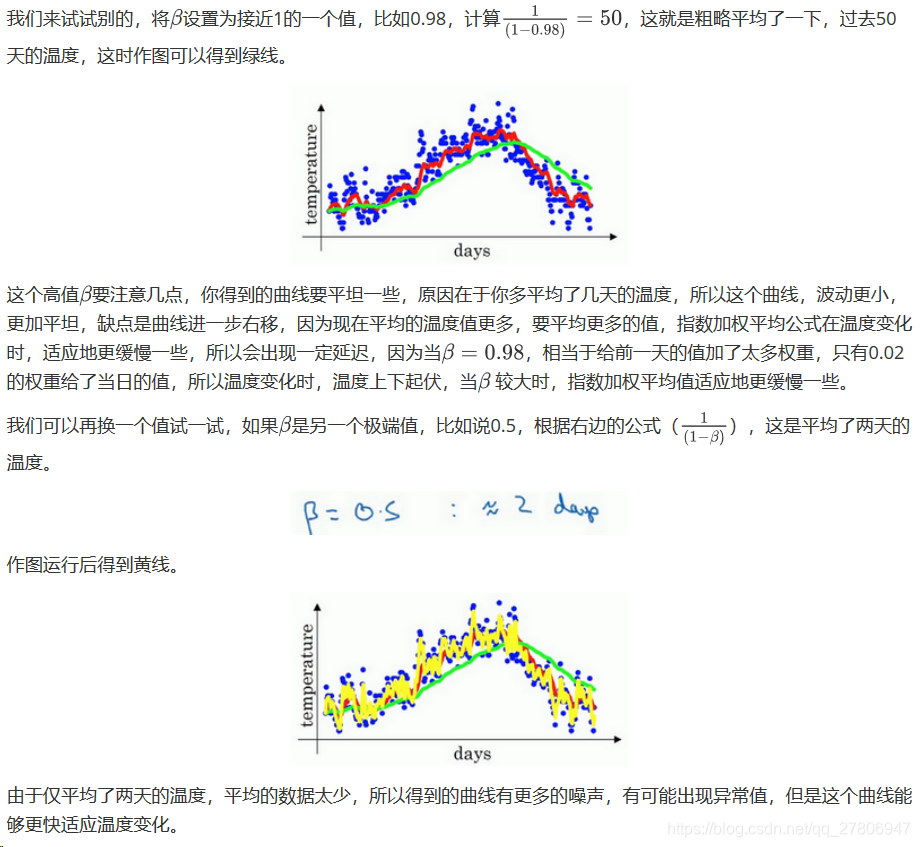

2.4 理解指数加权平均数(Understanding exponentially weighted averages)
上个视频中,我们讲到了指数加权平均数,这是几个优化算法中的关键一环,而这几个优化算法能帮助你训练神经网络。本视频中,我希望进一步探讨算法的本质作用。
回忆一下这个计算指数加权平均数的关键方程。






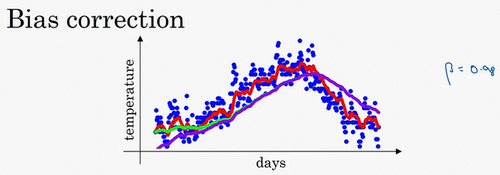
2.5 指数加权平均的偏差修正(Bias correction in exponentially weighted averages)
你学过了如何计算指数加权平均数,有一个技术名词叫做偏差修正,可以让平均数运算更加准确,来看看它是怎么运行的。


2.6 动量梯度下降法(Gradient descent with Momentum)
还有一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法,简而言之,基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重,在本视频中,我们呢要一起拆解单句描述,看看你到底如何计算。
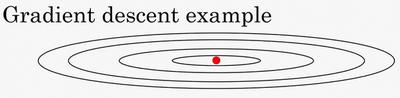
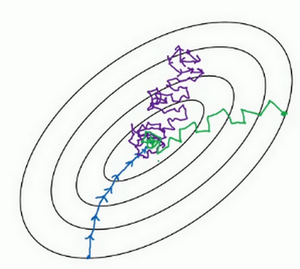
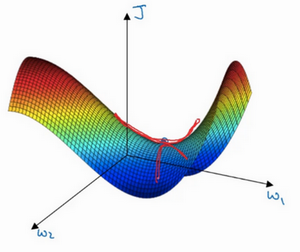
例如,如果你要优化成本函数,函数形状如图,红点代表最小值的位置,假设你从这里(蓝色点)开始梯度下降法,如果进行梯度下降法的一次迭代,无论是batch或mini-batch下降法,也许会指向这里,现在在椭圆的另一边,计算下一步梯度下降,结果或许如此,然后再计算一步,再一步,计算下去,你会发现梯度下降法要很多计算步骤对吧?

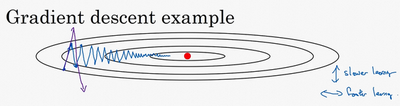
慢慢摆动到最小值,这种上下波动减慢了梯度下降法的速度,你就无法使用更大的学习率,如果你要用较大的学习率(紫色箭头),结果可能会偏离函数的范围,为了避免摆动过大,你要用一个较小的学习率。




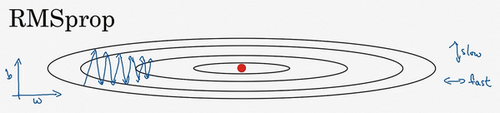
2.7 RMSprop
你们知道了动量(Momentum)可以加快梯度下降,还有一个叫做RMSprop的算法,全称是root mean square prop算法,它也可以加速梯度下降,我们来看看它是如何运作的。



2.8 Adam 优化算法(Adam optimization algorithm)
在深度学习的历史上,包括许多知名研究者在内,提出了优化算法,并很好地解决了一些问题,但随后这些优化算法被指出并不能一般化,并不适用于多种神经网络,时间久了,深度学习圈子里的人开始多少有些质疑全新的优化算法,很多人都觉得动量(Momentum)梯度下降法很好用,很难再想出更好的优化算法。所以RMSprop以及Adam优化算法(Adam优化算法也是本视频的内容),就是少有的经受住人们考验的两种算法,已被证明适用于不同的深度学习结构,这个算法我会毫不犹豫地推荐给你,因为很多人都试过,并且用它很好地解决了许多问题。
Adam优化算法基本上就是将Momentum和RMSprop结合在一起,那么来看看如何使用Adam算法。




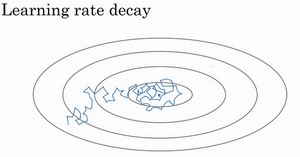
2.9 学习率衰减(Learning rate decay)
加快学习算法的一个办法就是随时间慢慢减少学习率,我们将之称为学习率衰减,我们来看看如何做到,首先通过一个例子看看,为什么要计算学习率衰减。




2.10 局部最优的问题(The problem of local optima)
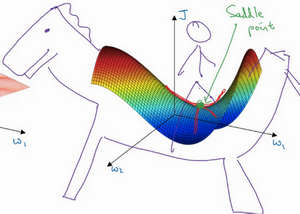
在深度学习研究早期,人们总是担心优化算法会困在极差的局部最优,不过随着深度学习理论不断发展,我们对局部最优的理解也发生了改变。我向你展示一下现在我们怎么看待局部最优以及深度学习中的优化问题。
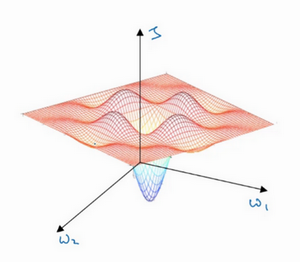

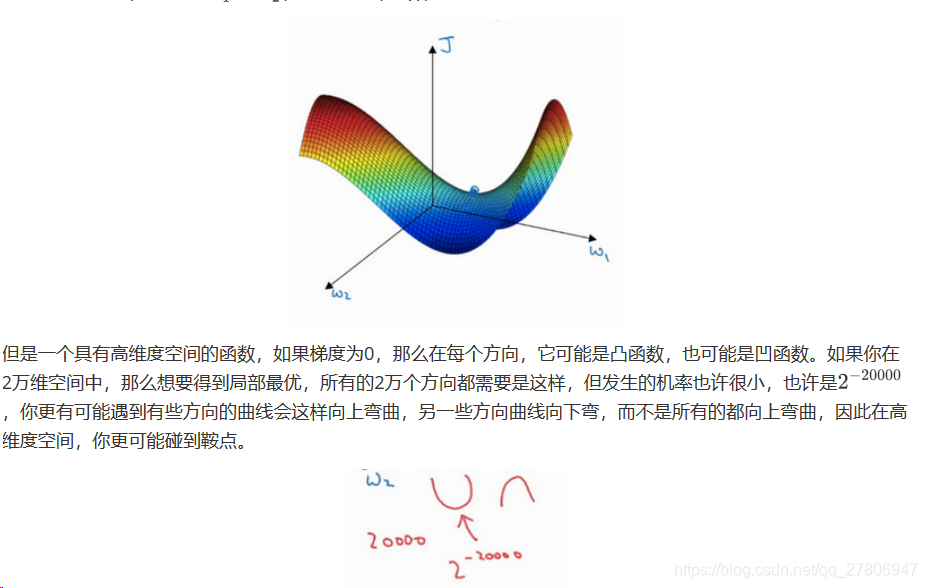
就像下面的这种:
而不会碰到局部最优。至于为什么会把一个曲面叫做鞍点,你想象一下,就像是放在马背上的马鞍一样,如果这是马,这是马的头,这就是马的眼睛,画得不好请多包涵,然后你就是骑马的人,要坐在马鞍上,因此这里的这个点,导数为0的点,这个点叫做鞍点。我想那确实是你坐在马鞍上的那个点,而这里导数为0。