选择最佳的训练集(Training sets)、验证集(Development sets)、测试集(Test sets)对神经网络的性能影响非常重要。除此之外,在构建一个神经网络的时候,我们需要设置许多超参数,例如神经网络的层数、每个隐藏层包含的神经元个数、学习速率、激活函数的选择等等。
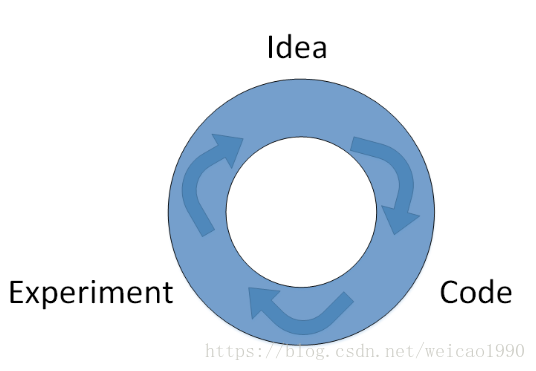
实际上很难在第一次设置的时候就选择到这些最佳的参数,而是需要通过不断地迭代更新来获得。这个循环迭代的过程是这样的:我们先有个想法,先选择初始的参数值,构建神经网络模型结构;然后通过代码实现这个神经网络;最后,通过实验验证这些参数对应的神经网络的表现性能。根据验证结果,我们对参数进行适当的调整优化,再进行下一次的Idea->Code->Experiment迭代。通过很多次的迭代,不断调整参数,选定最佳的参数值,从而让神经网络性能最优化。
深度学习已经应用于许多领域中,比如NLP,CV,Speech Recognition等等。通常来说,最适合某个领域的深度学习网络往往不能直接应用在其它问题上。解决不同问题的最佳选择是根据样本数量、输入特征数量和硬件配置(GPU或者CPU)等,来选择最合适的模型。即使是最有经验的深度学习专家也很难第一次就找到最合适的参数。因此,应用深度学习是一个反复迭代的过程,需要通过反复多次的循环训练得到最优化参数。决定整个训练过程快慢的关键在于单次循环所花费的时间,单次循环越快,训练过程越快。而设置合适的Train/Dev/Test sets数量,能有效提高训练效率。
一般地,我们将所有的样本数据分成三个部分:Train sets(训练集) 、Dev sets(验证集) 、Test sets(测试集)。Train sets用来训练你的算法模型;Dev sets用来验证不同算法模型的表现情况,从中选择最好的算法模型;Test sets用来测试最好算法模型的实际表现,作为该算法的无偏估计。
之前人们通常设置Train sets和Test sets的数量比例为70%和30%。如果有Dev sets,则设置比例为60%、20%、20%,分别对应Train sets、Dev sets、Test sets。这种比例分配在样本数量不是很大的情况下,例如样本数量是100,1000,10000,是比较科学的。但是如果数据量很大的时候,例如100万,这种比例分配就不太合适了。科学的做法是要将Dev sets和Test sets的比例设置得很低。因为Dev sets的目标是用来比较验证不同算法的优劣,从而选择更好的算法模型就行了。因此,通常不需要所有样本的20%这么多的数据来进行验证。对于100万的样本,往往只需要10000个样本来做验证就够了。Test sets也是一样,目标是测试已选算法的实际表现,做无偏估计。对于100万的样本,往往也只需要10000个样本就够了。因此,对于大数据样本,Train sets、Dev sets、Test sets的比例通常可以设置为98%、1%、1%,或者99%、0.5%、0.5%。样本数据量越大,相应的Dev sets、Test sets的比例可以设置的越低一些。
深度学习还有个重要的问题就是训练样本和测试样本分布上不匹配,意思是训练样本和测试样本来自于不同的分布。举个例子,假设你开发一个手机app,可以让用户上传图片,然后app识别出猫的图片。在app识别算法中,你的训练样本可能来自网络下载,而你的验证和测试样本可能来自不同用户的上传。从网络下载的图片一般像素较高而且比较正规,而用户上传的图片往往像素不稳定,且图片质量不一。因此,训练样本和验证/测试样本可能来自不同的分布。解决这一问题的比较科学的办法是尽量保证Dev sets和Test sets来自于同一分布。值得一提的是,训练样本非常重要,通常我们可以将现有的训练样本做一些处理,例如图片的翻转、假如随机噪声等,来扩大训练样本的数量,从而让该模型更加强大。即使Train sets和Dev sets、Test sets不来自同一分布,使用这些技巧也能提高模型性能。
最后提一点的是如果没有Test sets也是没有问题的。Test sets的目标主要是进行无偏估计。我们可以通过Train sets训练不同的算法模型,然后分别在Dev sets上进行验证,根据结果选择最好的算法模型。这样也是可以的,不需要再进行无偏估计了。如果只有Train sets和Dev sets,通常也有人把这里的Dev sets称为Test sets,我们要注意加以区别。