所插入图片仍然来源于吴恩达老师相关视频课件。仍然记录一下一些让自己思考和关注的地方。
第一周 训练集与正则化
这周的主要内容为如何配置训练集、验证集和测试集;如何处理偏差与方差;降低方差的方法(增加数据量、正则化:L2、dropout等);提升训练速度的方法:归一化训练集;如何合理的初始化权重矩阵来缓解梯度消失和梯度爆炸的问题;在debug过程中应用梯度检验可以很好解决一些bug。
1.应用深度学习是一个多次迭代的过程,实际应用中每一次迭代的效率很关键。
2.Train\dev\test sets的划分:
小数据量(万级别):60/20/20 。
大数据量(百万级别):98/1/1或者 99.5/0.4/0.1。
深度学习需要大量的数据进行学习,导致train\dev\test可能来自于不同的分布,此时应该确保验证集和测试集来自于同一分布。如果不需要无偏估计的话,没有测试集也是可以接受的。如果验证集与测试集来自于同一分布,在验证集上表现良好往往在测试集上也表现良好。
3.通过训练集误差和验证集误差来判断模型的偏差与方差情况。
注意下图存在着两个前提条件:(1)训练集与验证集来自于同一分布。(2)数值相对于最优误差(也成为贝叶斯误差)来看,下图最优误差为0。训练误差较高,那么偏差肯定也高,这是毋庸置疑的。验证误差相对于训练误差高,那么该模型的方差就高。因为方差其实影响着该模型的泛化能力,一个模型的泛化能力弱表现在对于新的样本的拟合程度低,方差高的模型泛化能力必然较弱。

4.一种降低模型方差的方法是准备更多的数据,当没有更多的数据时,还可以采用正则化。这也不难理解,当一个模型存在高方差,也就是过拟合的问题时,往往就是该模型太过于复杂,学习了一些我们并不想要其学习的特征,在不变更模型的基础上,正则化所要做的便是通过调整参数来做到降低模型复杂度的目的。在成本函数后添加正则化项,例如L2正则项,例如超参数进行调节,使参数的权重降低,便可以起到降低某些参数作用的目的。使用L2正则化的一个缺点在于,得不断的尝试超参数,这会负担较大的计算代价。
5.Dropout(随机失活)正则化 ,顾名思义,随机删除一些网络中节点,达到精简网络、改善过拟合的目的。常用的Dropout方法之一便是反向Dropout(Inverted Dropout),这一方法在删除节点后,注意使该层的激活值除以keep-prob,目的是为了保持下一层输出的期望与删除节点之前保持一致。这样做同时也保证在测试阶段中的网络不使用dropout,输出的结果也能保持合理性。
6.数据增强,解决数据量较小的问题。方法较多。
7.EarlyStopping,观察训练误差和验证误差的曲线,选择适当的位置,停止迭代过程。简单方便,但是试图一次性解决使代价函数最小和使模型方差变小这两个问题,结果可想而知,并不会很好。
8.吐槽一下,1.8节明明讲的是其他降低过拟合的方法,但是标题却是其他正则化方法。
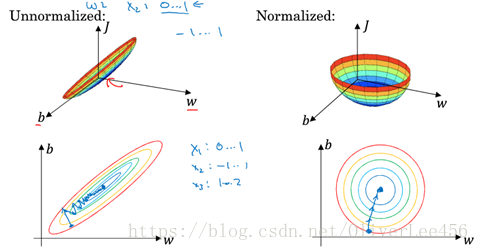
9.归一化训练集(Normalize train sets):减去均值,并除以方差。当输入特征的尺度差距很大时,如x1~(0,1),x2~(1,10000),此时归一化训练集可以起到加速学习过程的目的。具体参见下图便很清晰了。例如左边的图,需要多次迭代寻找最小值,因为需要设置较低的学习率避免跳过局部最小值。
10.梯度消失(vanishing gradient)和梯度爆炸(exploding gradient),如果此时利用梯度下降法进行训练,那会非常的慢。这成为了训练神经网络的一个阻力。合理的初始化权重矩阵(不能太大,也不能太小)是作为缓解这个问题的方法。例如Xavier初始化等等。关于Xavier初始化参见 2010_[Xavier Glorot]_Understanding the difficulty of training deep feedforward neural networks。
梯度检验(gradient checking),梯度检验是作为检测神经网络在后向传播中是否存在bug的一种实用的手段。由几个注意事项:
(1)不要在神经网络训练中应用,仅仅在debug中应用。
(2)注意正则项。
(3)不能与dropout一起使用。
第二周 优化算法
1.mini batch梯度下降。
算法每遍历一次训练集称为一个epoch。
Mini-batch 是batch 和 stochastic(永远不会收敛,只会在最小值附近波动,所以一般都不会使用)的折中,如何确定mini-batch的大小呢,有一些参考。
(1)当小样本情况下,(m<2000),使用批梯度下降。
(2)一般选择大小符合计算机的内存习惯,常见大小的选取:64,128,256,512。
2.指数加权平均,统计中称为指数加权移动平均,并不是很清楚其原理,但是可以记下结论。

注意参数的取值。
以及根据的值,可以大约推测平均了(1/1-
)的数据。
由于初始值V0=0,这样操作的话便会生成一个问题,使最初的几个计算不准确,因此需要加一个偏差修正来解决:
这里,讨论较深的数学意义不太有意义,形式上看,便是以指数的形式进行加权,权值依次为,
^2,
^3 其实将公式展开便可以大概看出是什么情况。使用指数加权平均的一大优势便是在电脑计算中占据很小的内存,而且只需要很少的代码,因此计算的效率高。
3.动量梯度下降法(momentum),简而言之,基本的想法就是计算梯度的指数加权平均数代替原有的梯度,并利用新计算的梯度来更新你的权重。

采用了一个新的参数vdw和vdb来代替之前的dw和db来进行参数的更新,因此,vdw与dw同维度,vdb与db同维度。常取值0.9,具备较好的鲁棒性。当
=0.9时,根据上面的内容,此时大致采用的是利用前10次进行更新,因此可以不考虑偏差修正。
4.RMSprop(root mean square prop)

仍然是在更新参数这一块做文章。这里应注意几个细节:
(1)dw的平方,db的平方。至于为什么是平方,也就是说利用指数平均计算的是原有梯度的平方,没有明白。这里有一个疑问是,指数平均的每次原有梯度的平方值,原有梯度有正有负,这样弄得话,那么岂不是把负的和正的都一视同仁了?
(2)在进行更新权重时,加了一个根号分之一的权重,这样的目的是为了减缓参数更新时的震荡,使震荡大的变小一些,震荡小的变大一些。
(3)注意根号内加一个较小值 ,常选10的负8次方,目的是为了防止根号内的值太小。
(4)经过RMSprop,更新中参数的震荡幅度变小,因此学习率就可以适当增加。
5.Adam(adaptive moment estimation 适应性矩估计),Momentum + RMSprop

注意几个细节:
(1)参数都进行了偏差调整。
(2)超参数的选择,常选用=0.9,
=0.999。
(3)既然跟矩有关系,可以发现,momentum利用指数平均计算的是一阶矩,RMSprop利用指数平均计算的二阶矩。具体数学原理不清楚。
6.学习率衰减 随着迭代过程的进行,逐步的减少学习率。之所以能够加快学习的速度,是因为在学习的后期,当参数向着局部最小值收敛时能够减少在局部最小值周围摆动的过程。
最常见的学习率衰减函数,其中衰减率和都为超参数:
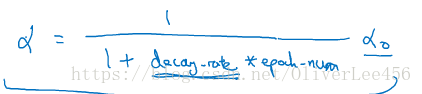
还有一些学习率衰减的策略:指数式、开方式、离散式(一段时间设置一个值)以及纯人工设置。

7.最后一讲的视频,吴恩达老师加深了我们对于局部最小值的理解。在学习算法中,我们常常会担心自己的梯度下降算法会陷入到局部最小值内而无法达到全局最小值,这在例如2维的低维空间是会存在这个问题,但是在高维的空间内,因为我们常常处理的是高维空间的问题,很少会遇到局部最小值的点,而常常为遇到鞍点。这是因为局部最小值的点即梯度为0的点,要求这个点各个方向上的导数都为0,在高维空间中这很难满足;而鞍点则满足在一些方向,导数为0,但是在另一些则不为0,梯度下降则会从不为0的方向继续算法。因此在高维空间时,不必过于担心会陷入局部最小值的境地(这非常少,但也可能出现)。
第三周 超参数选择策略、Batch Normalization、Softmax
1.超参数选择策略:
(1)随机取值而不是网格取值,随机取值代表着有更多的可能性探究不同的超参数的潜在值。
(2)还有一种思路是从粗略到精细的选择超参数,
(3)调整超参数的尺度更好的进行超参数的选择。(例如实数轴转换为对数轴、指数轴等)。例如学习率的取值。
2.Batch归一化(batch normalization),我也不清楚翻译成Batch归一化对不对,总感觉怪怪的,但是先姑且按照这样翻译。如下图所示:
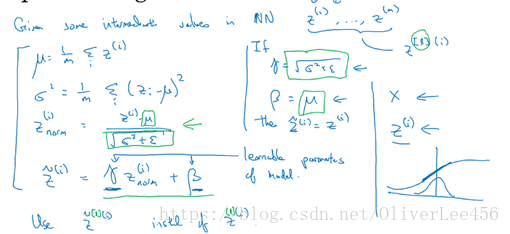
在进行训练时,常常会对训练的数据进行一个参数归一化的过程,而同样,直观上看batch归一化要做的是对隐藏层的归一化操作,注意这里是对隐藏层节点激活前的z值进行的归一化。但是与常规的归一化操作不同的是,在进行归一化操作后,还存在一个类似于线性映射的步骤,即(注意与Adam等算法中超参数区分)。形式上看,这个操作是归一化操作的逆过程。为什么要有这个过程,因为要注意到,在归一化操作的过程中,我们将这些z值全部映射到均值为0,方差为1的空间中,有时候这样做,可能缩小了参数z变化的可能性,所以增加这个逆过程。注意
和
是可学习的参数。通过batch归一化和逆归一化(逆归一化这个词可能用的不对,只是形式上面是这个意思)这个流程,我的理解是增强了对于隐藏层的控制程度。
不难看出,利用batch normalization不仅会增加计算量,而且在训练网络时还增加了新的参数和
,但是其还是会加速神经网络的学习进程,并且能使训练更深的网络。因为从其做的操作来看,其本身通过归一化和归一化后尺度改变操作,增强了自身本层的独立性,限制了前面层的更新值对该层的影响程度,从而减少了前面层网络对后面层网络的影响,增加了层本身的独立性,从而使层更健壮。Andrew提到,batch normalization也可看做是一个轻微的正则化过程,因为在mini-batch上进行操作时,其batch normalization无疑是给处理中的数据增加了一些噪声,这不难理解。
关于提到的batch normalization是解决Covariate shift的一个方案,参考https://blog.csdn.net/guoyuhaoaaa/article/details/80236500
3.Softmax(名字来源于hardmax的对比,例如hardmax输出[1,0,0,0],softmax输出[0.8,0.1,0.05,0.05])。注意softmax激活函数输入一个向量,输出一个向量。注意在处理过程中进行了一个非线性的映射,即取指数e。我想一是为了解决输入softmax中存在着负值的问题,二是为了使输出的分类打破线性关系的制约。同时,softmax也可以看做是将逻辑回归推广到多种分类。

观察其损失函数,只与待分的正确的类有关系。即找到需要分的正确的类,并使该类的分类概率最大化。