吴恩达 改善深层神经网络:超参数调试、正则化以及优化 课程笔记
第一周 深度学习里面的实用层面
1.1 测试集/训练集/开发集
原始的机器学习里面训练集,测试集和开发集一般按照6:2:2的比例来进行划分。但是传统的机器学习的训练数据很少只需要几千到几万的数据就可以训练。但是当前基于深度学习的算法训练网络的数据有几百万张,所以他的开发集和测试集的数量虽然增加了但是由于基数大所以占得比例变小了可能是9:0.5:0.5这样。
1.2 偏差和方差
训练集的错误率是:10%
开发集的错误率是:12%
偏差 = 训练集的错误率
方差 = 开发集 - 训练集 = 2%
1.3 正则化问题
正则化可以解决高偏差和过拟合问题。L1和L2正则化是在损失函数的基础上加上了权重w。λ是正则化参数,通过训练得到。
L1正则化:
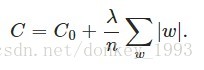
L2正则化:
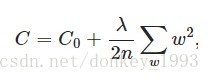
L2正则化又称为 权重衰减。
为什么正则化可以防止过拟合?
直观的理解:当λ增大,w就会变小,一些神经元就会变为0失效。神经元减少了,网络相对简单就会缓解过拟合问题。
客观理解:
如下图所示,λ增大,w减小,z=w*a+b,对应的z也会减小,z减小了取值范围就会变小,取值范围如下图红色区域所示。z的取值范围变小,可以将它的函数看作是一个线性函数(红色区域),当激活函数变成线性函数网络就变得线性更加简单。

1.4 Dropout正则化和其他正则化方法
随机删除网络中的神经元。
数据增强,提前终止
1.5 梯度消失和梯度爆炸

假设网络结构如上图,激活函数使用简单f(x)=x。那么y=w1*w2*w3*...*w9*x。当w>1的时候 y = w^9*x,就会出现梯度爆炸问题,反之当w<1的时候就会出现梯度消失问题。
1.6 梯度检验算法,用来验证网络训练是否出现异常。
双向误差求得的导数比单向求导更加的准确。