1.2 偏差 / 方差(Bias / Variance)
最优误差(也被称为贝叶斯误差)很小的情况下:
通过查看训练集误差,我们可以判断数据拟合情况,可以判断是否有偏差问题。然后查看验证集错误率有多高,我们可以判断方差是否过高。
高偏差:不能很好地拟合训练集
高方差:能很好的拟合训练集,但不能很好地拟合测试集,另一种说法是过度拟合某些数据
下面分别是高偏差和高方差
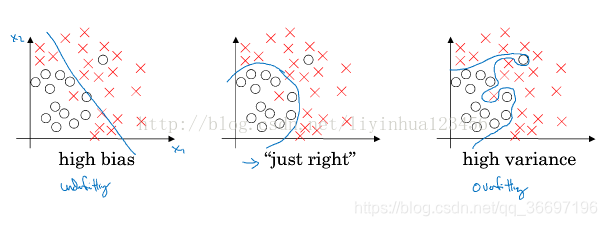
举个例子:下面是一个猫的识别的例子,y=1,代表图片上是猫,y=0,代表图片上不是猫,下面的例子具体给出什么叫高偏差,什么叫高方差

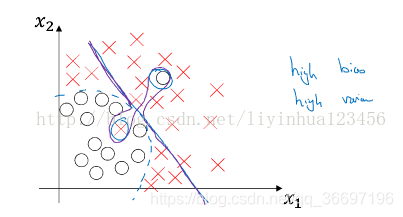
高偏差与高方差同时具备的例子:
1.3 机器学习基础(Basic Recipe for Machine Learning)
训练神经网络时常用的基本方法
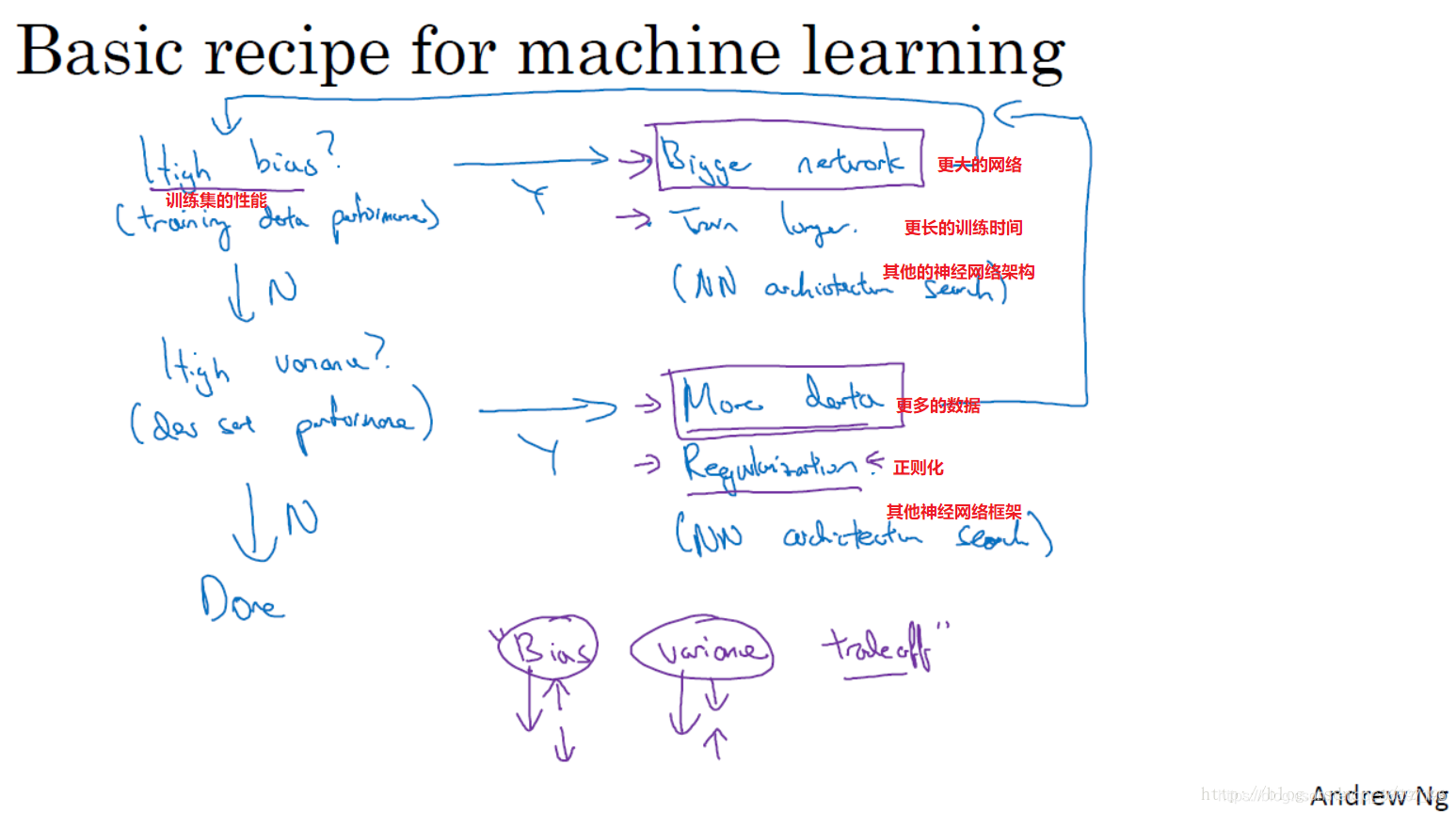
如何解决高偏差和高方差的问题
当初始模型训练完成后,首先要知道算法的偏差高不高,偏差高(无法拟合训练集)的解决办法有:
1)选择一个新网络,比如含有更多隐层或者隐层单元的网络
2)花费更多时间训练算法,或者尝试更先进的优化算法
当结果很好地拟合训练集时,就要查看是否在验证集上也表现很好,即检查是否有高方差问题(过度拟合),高方差的解决方法有:
1)采用更多的数据(可能很难)
2)通过正则化(等下介绍)来减少过拟合
不断迭代,直到找到一个低偏差,低方差的模型
1.4 正则化(Regularization)
如果你的神经网络过度拟合了数据, 防止过拟合的一种方法是采用更多数据,另一种是降低模型的复杂度(加正则化项),如何降低模型的复杂度?
一种方式是在cost函数中加入正则化项,正则化项可以理解为复杂度,cost越小越好,因此cost加入正则化项后,为了使cost小,则不能使正则项大,也就是不能让模型复杂,这样就降低了模型的复杂度,也就降低了过拟合,这就是正则化。
首先介绍的是在logoistic regression上的正则化(也就在在损失函数后面加上正则化项)

然后是在神经网络上的正则化,加入正则项后,损失函数变化,因此反向传播中参数也发生了变化
7
1.5 为什么正则化可以减少过拟合?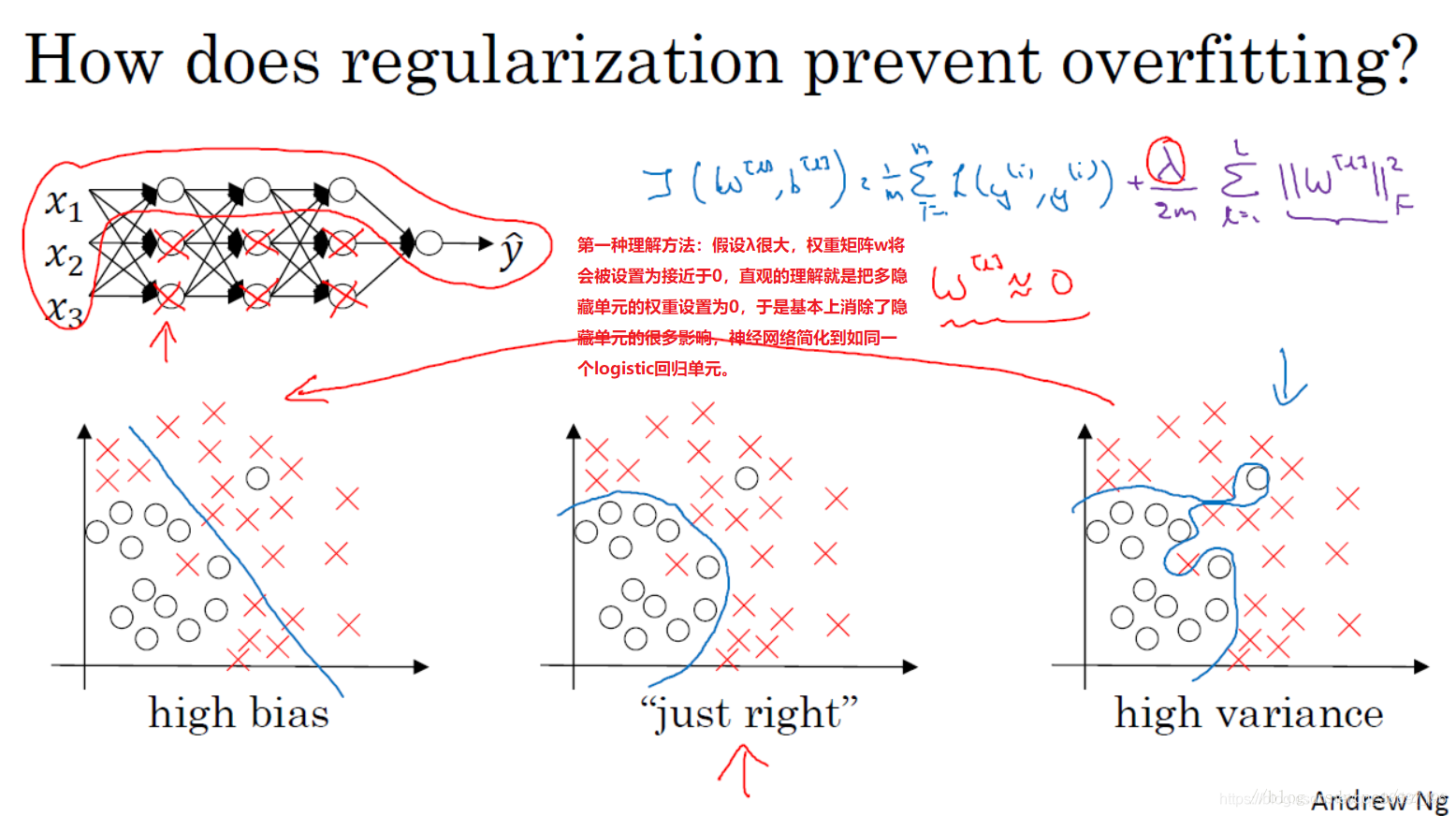
下面给出一个直观的例子来解释为什么正则化可以减少过拟合
假设我们采用的激活函数是tanh,当z很小时,也就是处于中间的线性区域内。此时若lambd很大,则因为代价函数的参数变大了使得w很小,则z也很小,几乎处于中间的线性区域内,几乎每层都是线性的,则整个网络就是一个线性网络,即使是很深的深层网络,因具有线性激活函数的特征,最终我们只能计算线性函数,因此,不适用于非常复杂的决策以及过度拟合数据集的非线性决策边界,也就减少了过拟合。

1.6 Dropout 正则化(Dropout Regularization)
除了L2正则化(我们上面使用的),还有一个非常实用的正则化方法,dropout 方法
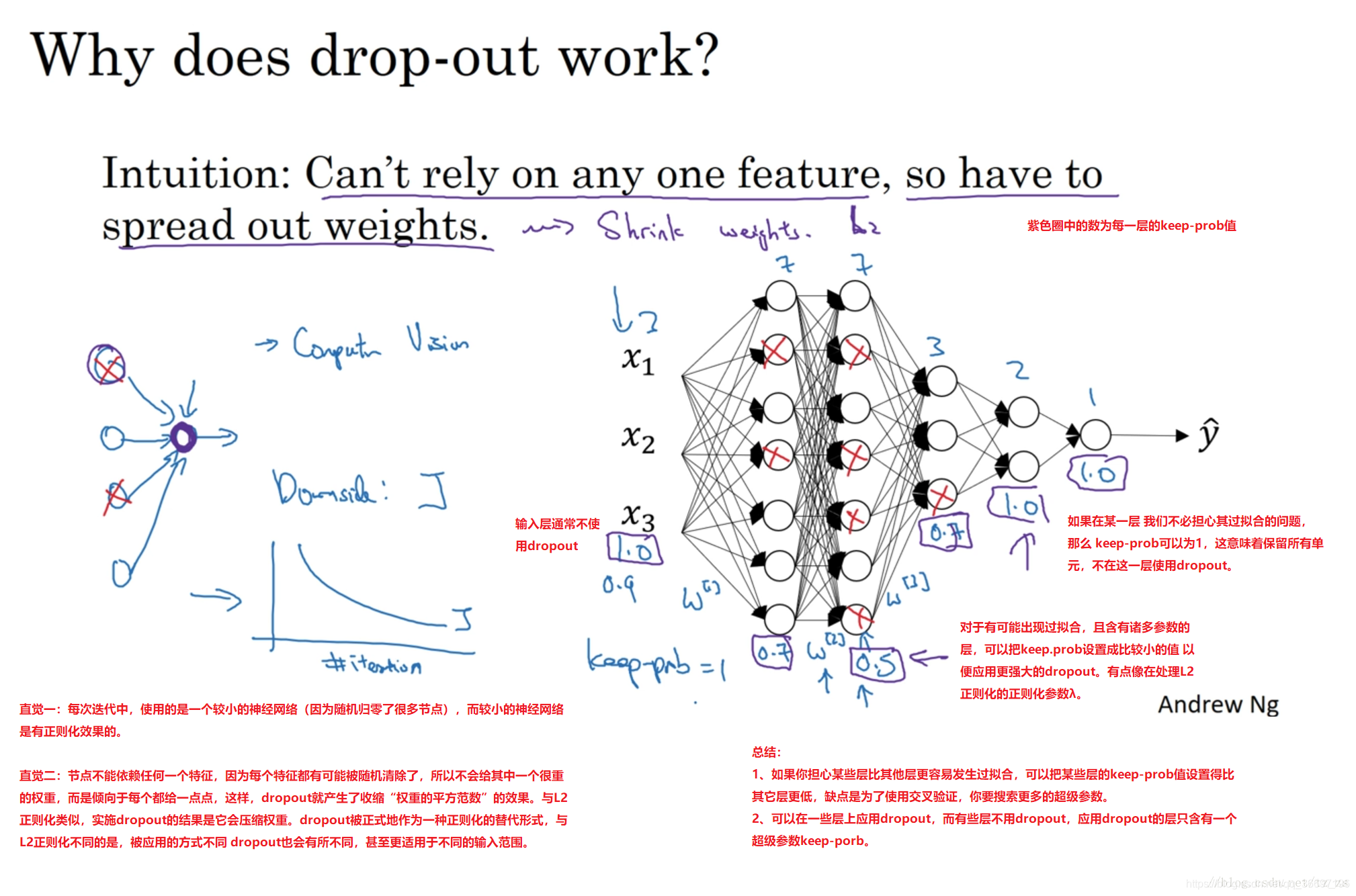
dropout工作原理:
假设左边的网络存在过拟合,这是dropout所要处理的,dropout会遍历神经网络的每一层,并设置消除神经网络节点的概率,假设,神经网络的每一层的每一个节点都以抛硬币的方式设置概率,每个节点得以消除和保留的概率都是0.5,设置完节点概率,我们会消除一些节点,然后删掉从该节点进出的连线,最后得到一个节点更少,规模更小的网络,然后用反向传播进行训练,右边就是网络节点精简后的一个样本,对于每一个样本,我们都采用精简后的神经网络来训练它

Inverted dropout(反向随机失活)的代码实现
第一步中d^3返回的是随机矩阵,每个样本和每个隐藏单元,在d3中对应值为1的概率为0.8,里面是false,true,与a3相乘会编程0,1,
第二步中a3返回的是过滤d3中所有等于0的元素
第三步中a3/=keep-prob: 第二步中a[3]减少20%,也就是a[3]中20%的元素被归为0,为了不影响z[4]的期望值,a3/0.8,能够弥补丢失的20%,保持a3的期望值不变


1.7.理解dropout
从另一角度再次理解为什么dropout有效
通过dropout,该单元的输入几乎被消除,因此,输出不能依靠任何一个特征,因此该单元的任何一个输入都有可能被随机清除,我不愿意把所有的赌注都放在一个节点上,
不愿意给任何一个输入加入太多的权重,因为它有可能被删除,因此该神经网络将以这种方式传播,并为每个单元的四个输入增加一点权重,通过传播所有权重,dropout会产生收缩权重的平方范数的效果,和之前的L2范式类似,dropout的结果是它会压缩权重,并完成一些预防过拟合的外层正则化,
为了防止过拟合,当某一层的节点数过多(更容易过拟合),设置keep-prob较低,对于最后一层,keep-prob=1,意味着保留其所有的节点
现实中,我们对输入层也不用dropout。
总结:
1、如果你担心某些层比其他层更容易发生过拟合,可以把某些层的keep-prob值设置得比其它层更低,缺点是为了使用交叉验证,你要搜索更多的超级参数。
2、可以在一些层上应用dropout,而有些层不用dropout,应用dropout的层只含有一个超级参数keep-porb。
提醒:
计算视觉中的输入量非常大,输入了太多的像素,以至于没有足够的训练数据,从而一直存在过拟合,所以dropout在计算机视觉中应用得比较频繁。有些计算机视觉研究人员非常喜欢用它,几乎成了默认的选择,但是要牢记一点:dropout是一种正则化方法,除非过拟合,否则不要使用。所以它在其它领域应用得比较少。
dropout一大缺点就是代价函数J不再被明确定义,因为每次迭代都会随机移除一些节点。老师的方法:我通常会关闭dropout函数,将keep.prop的值设为1,运行代码,确保J函数单调递减,调试成功后,然后再打开dropout函数。
1.8.其他的减少过拟合方法
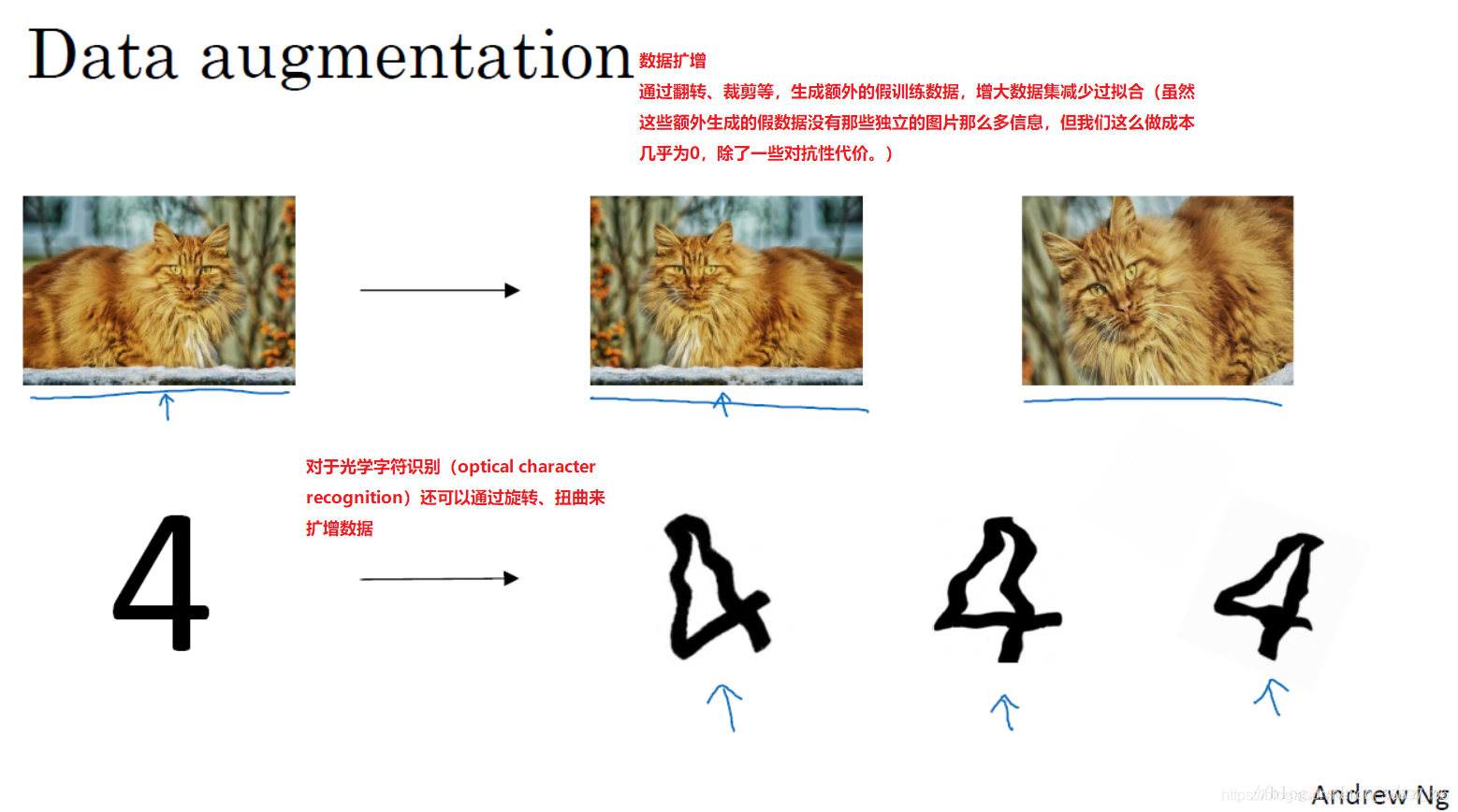
1.数据扩增(水平翻转,。。。)
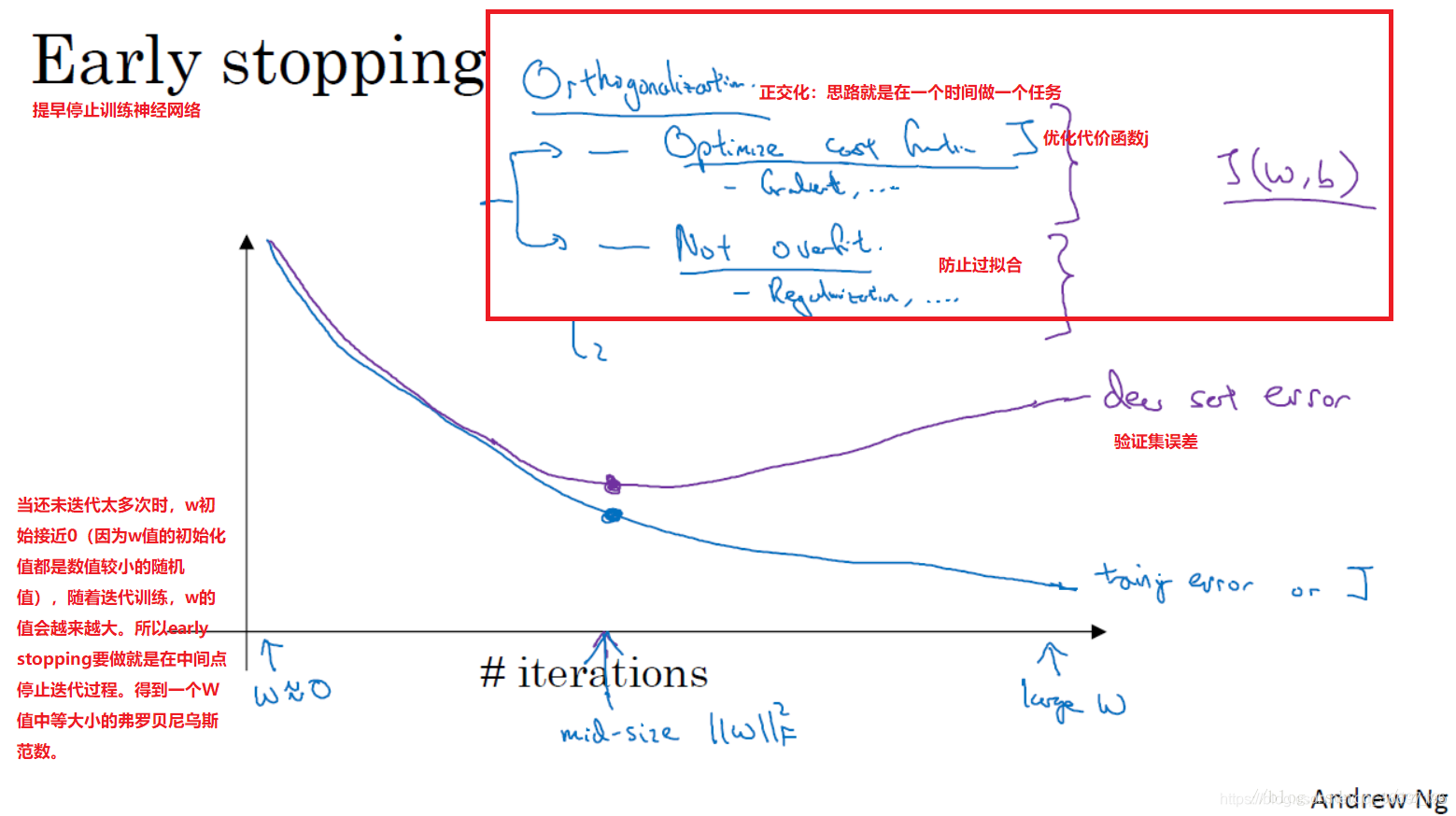
2.early stopping(提早停止训练神经网络)
L2正则化和early stopping的对比
early stopping与L2正则化相似,都是选择参数W范数较小的神经网络来防止过拟合。
early stopping的优点是:只运行一次梯度下降,你可以找出W的较小值、中间值和较大值,而无需像L2正则化那样尝试超级参数λ的很多值。缺点是:你不能独立地处理优化代价函数j和防止过拟合这两个问题。因为提早停止梯度下降,也就是停止了优化代价函数J(这时有可能j还不是最优),同时停止了过拟合进程,你没有采用多钟方法分别处理两个问题,而是用一种方法同时解决两个问题。这样导致要考虑的东西变的更复杂了。
L2正则化缺点是:你必须尝试很多正则化参数λ的值(这也导致搜索大量λ值的计算代价太高)训练神经网络的时间可能很长。
虽然L2正则化有缺点,我个人更倾向于使用L2正则化,尝试许多不同的λ值,假如你可以负担大量计算的代价。使用early stopping也能得到相似结果,而且不用尝试这么多λ值。
优化问题(setting up your optimization problem)
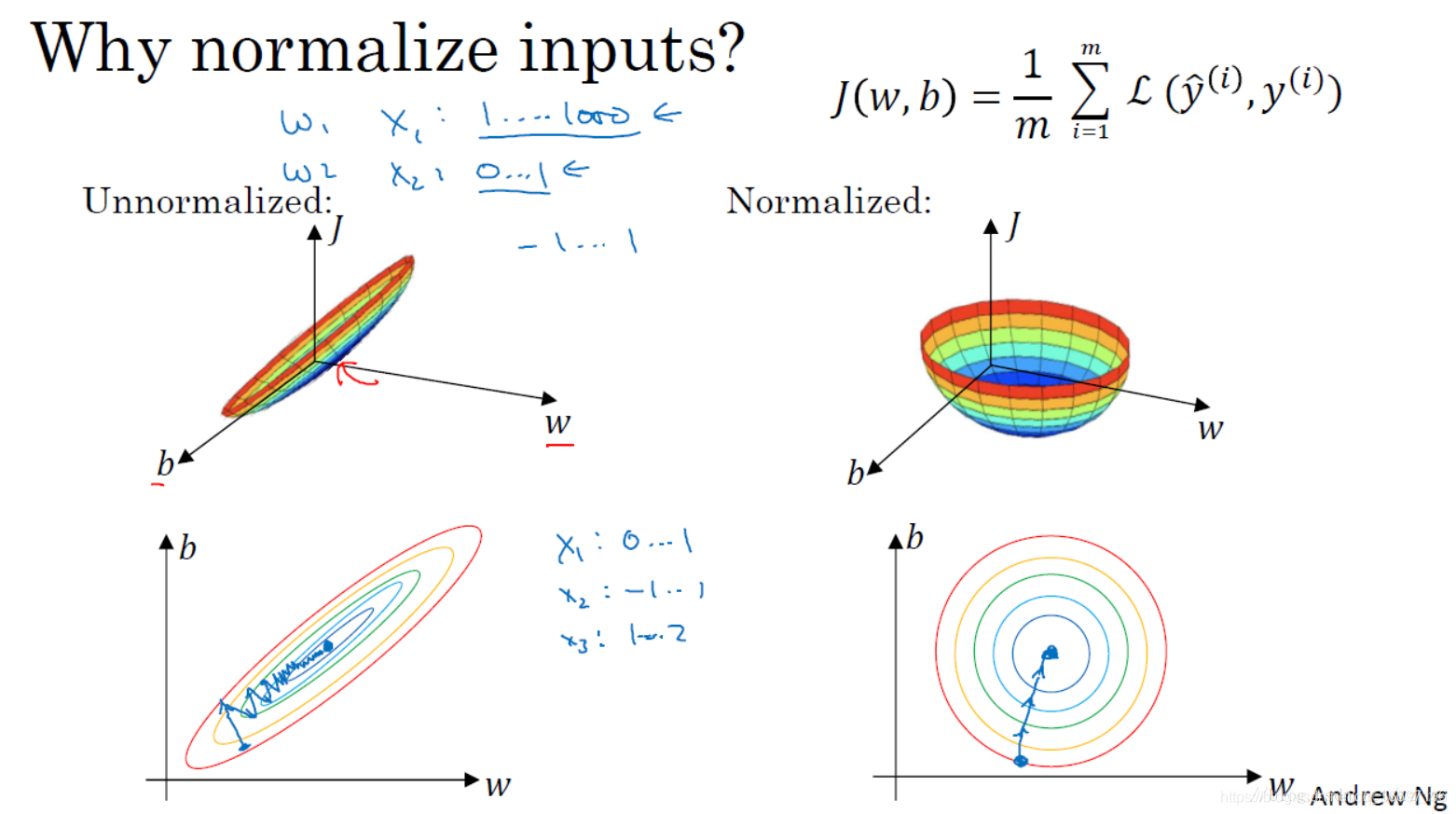
1.9 归一化输入(Normalizing inputs)
归一化输入:提高训练速度
首先进行零均值化,再进行归一化方差
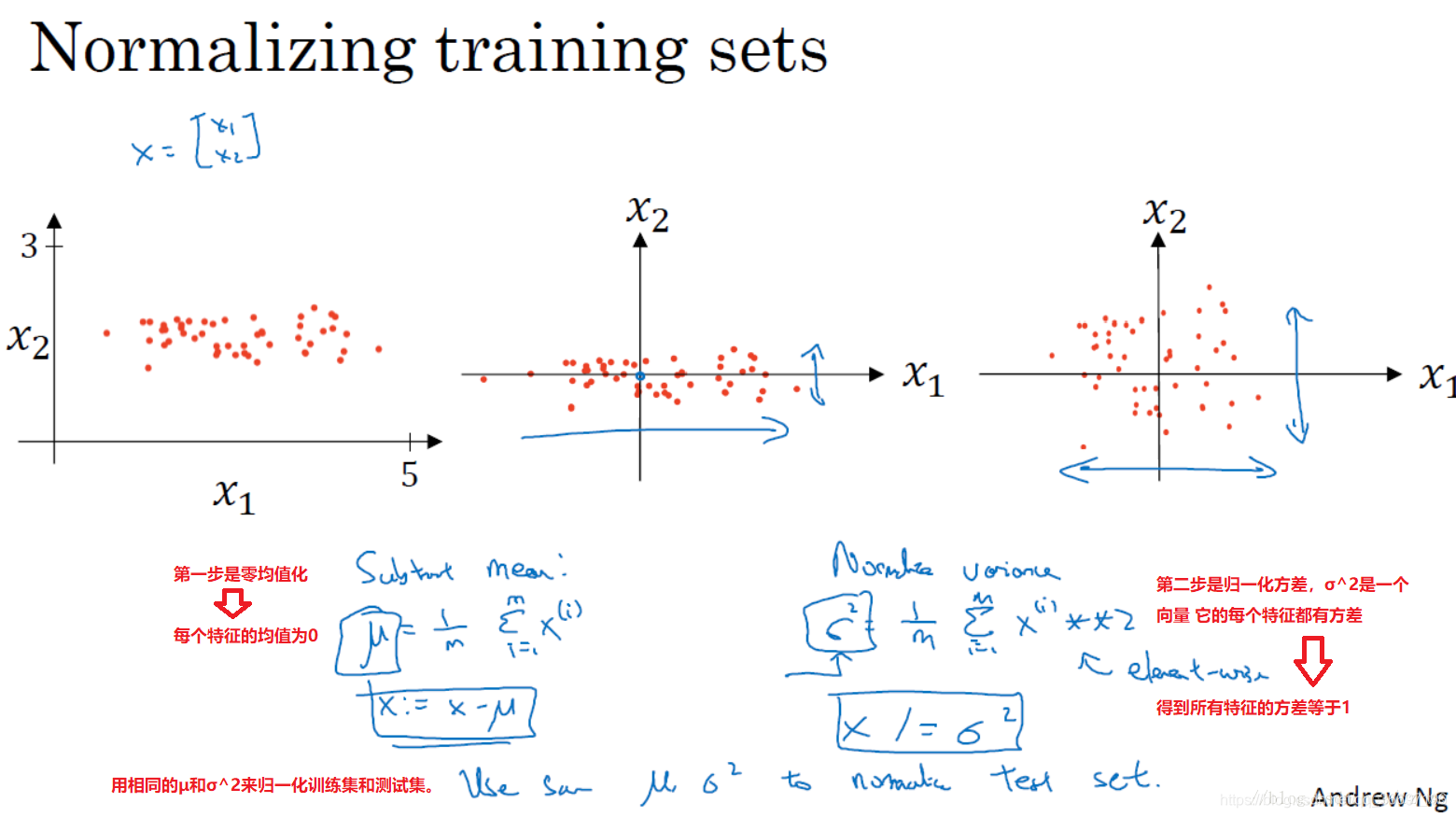
归一化处理后的数据训练的速度更快,能够很快到达损失最小的地方
1.10.梯度消失与梯度爆炸(Vanishing / Exploding gradients)
梯度消失:
假设激活函数为(g(z)=z),当w【l】<1时,激活函数y hat的值以指数型迅速变得特别的小,
梯度爆炸:
当w[l]>1时, 激活函数的值以指数形式迅速变大,
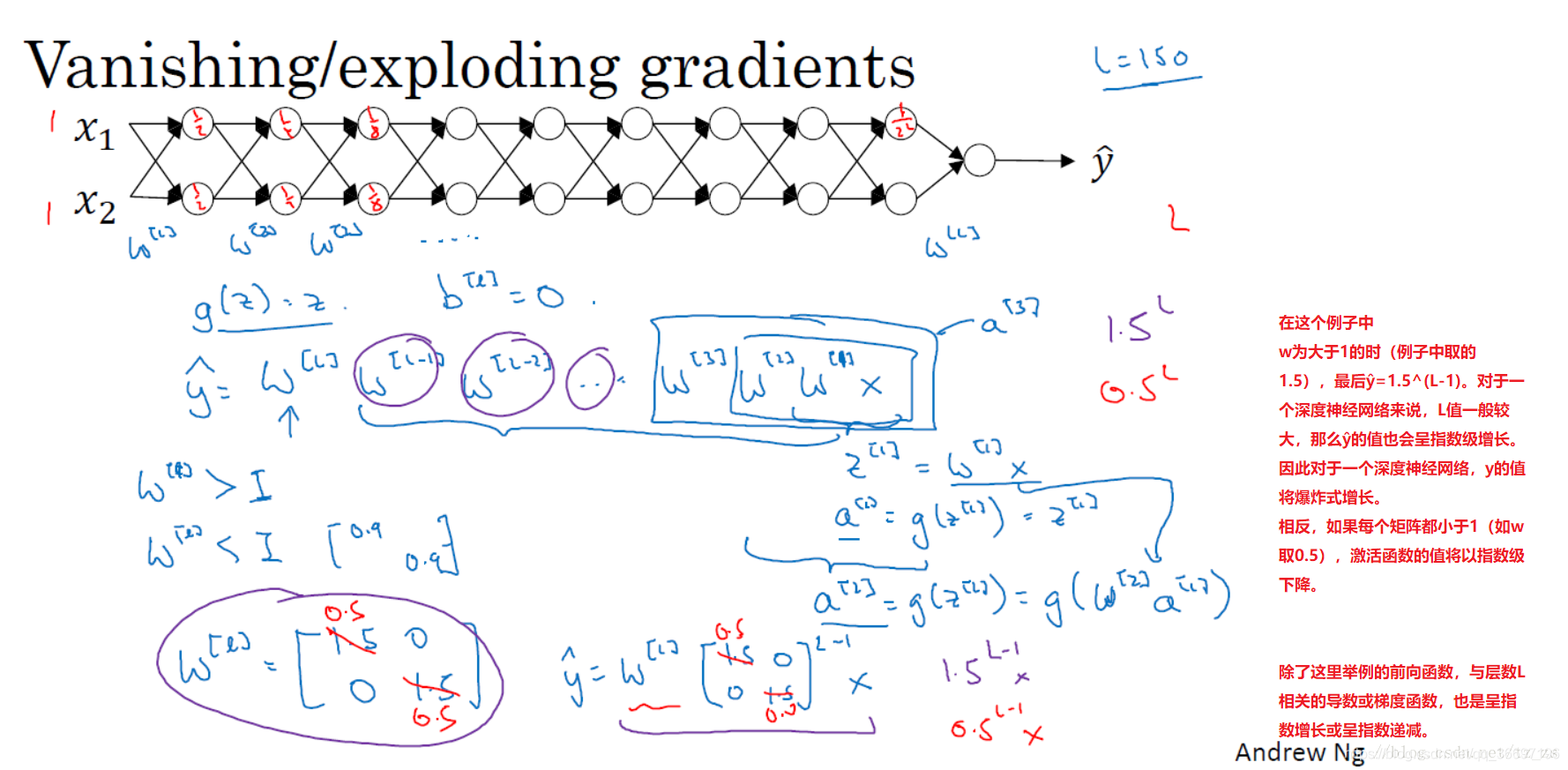
从上面可以看出,初始化w方式非常的重要
1.11 神经网络的权重初始化(Weight Initialization for Deep Networks)
针对梯度消失和梯度爆炸问题的一个不完整的解决方案(虽然不能彻底解决问题,但它确实降低了坡度消失和爆炸问题):谨慎地选择随机初始化参数,为权重矩阵初始化合理的值,使他既不会增长过快,也不会太快下降到0,从而得到权重或梯度不会增长或消失过快的深度网络。
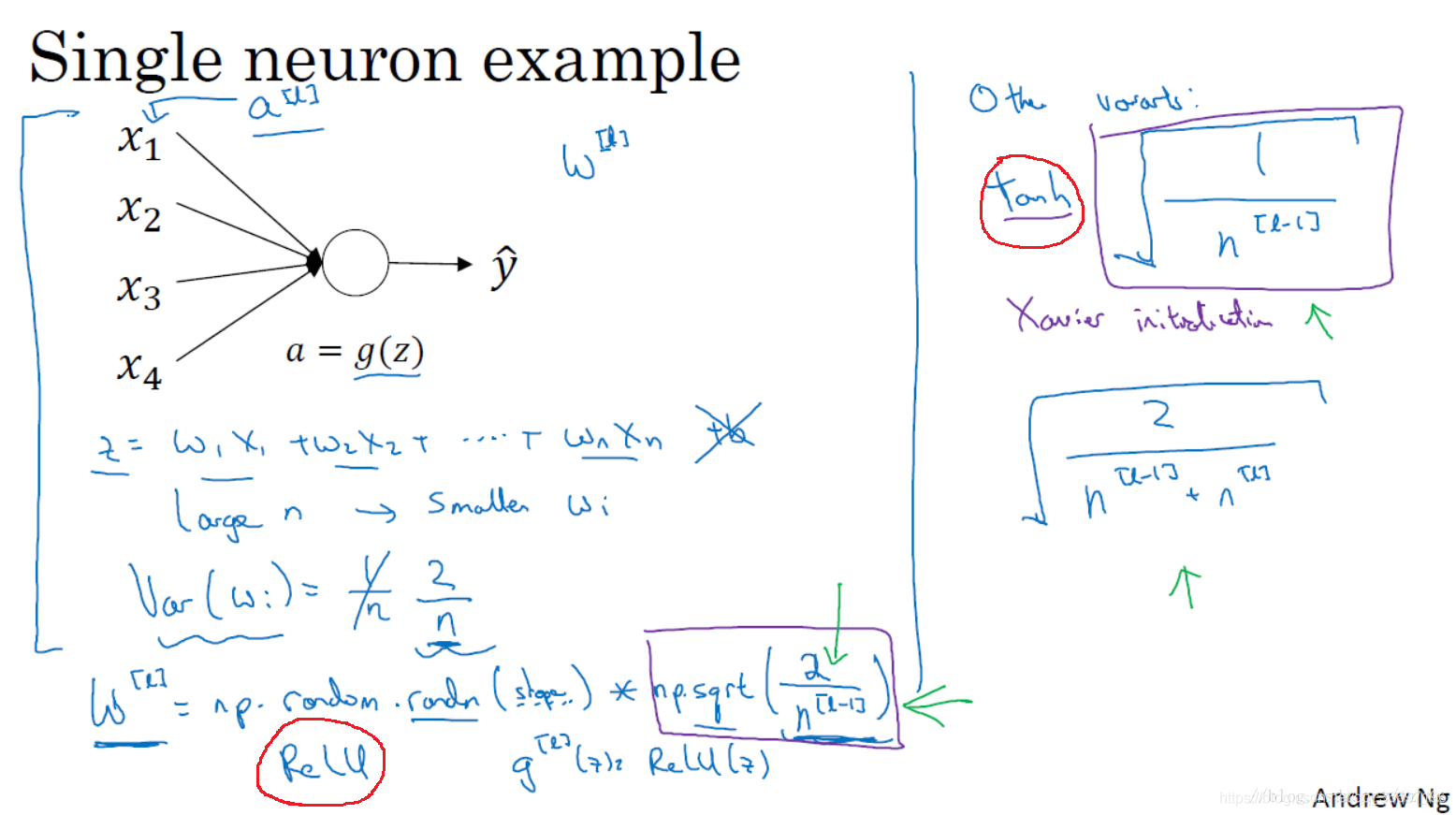
使用sigmoid方差设为1/n,使用relu的时候方差设为2/n,如果使用的是tanh则可以使用右上方的两种方差开方形式
1.12 梯度的数值逼近(Numerical approximation of gradients)
双边误差公式的结果更准确

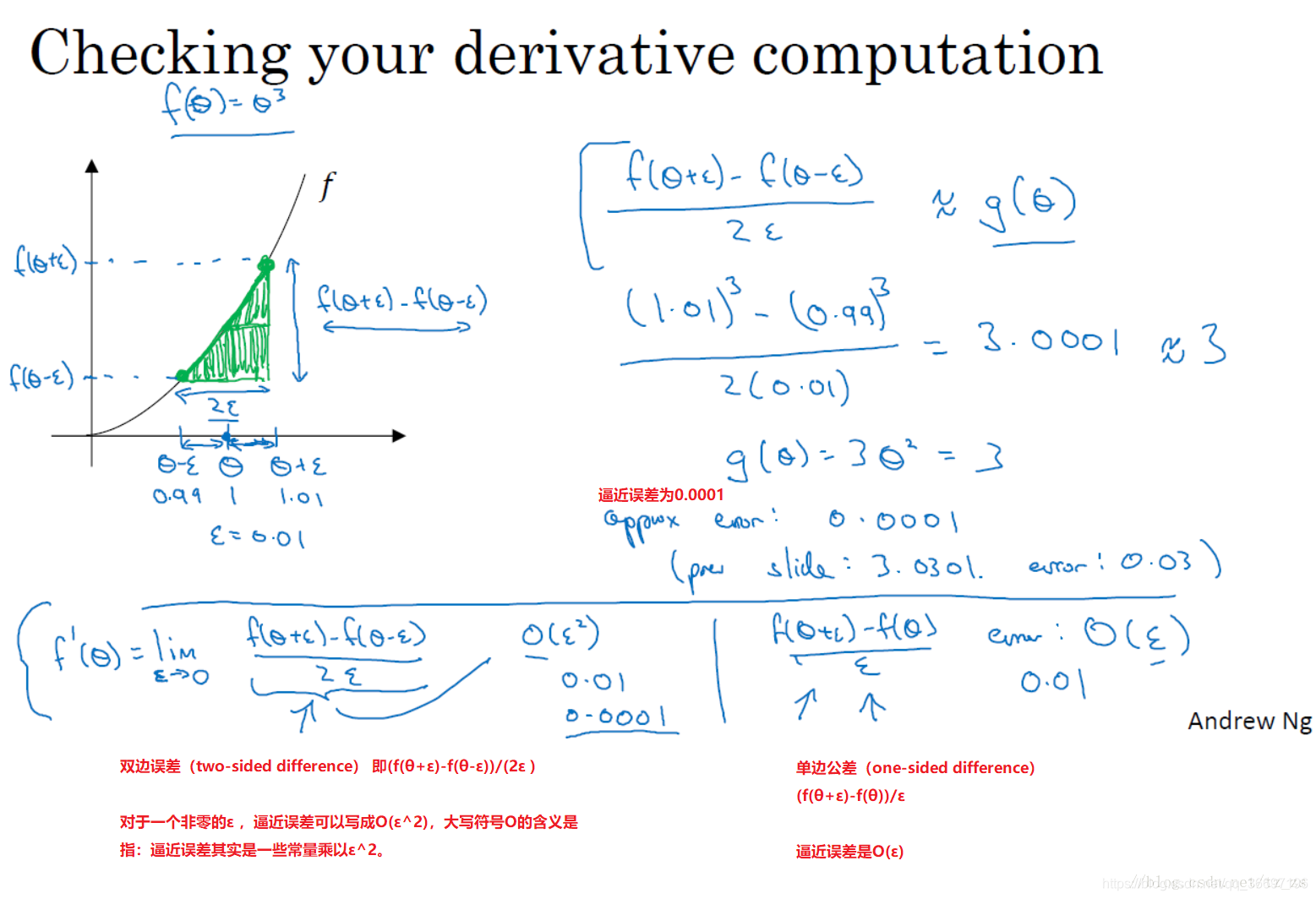
1.13 梯度检验(Gradient checking)
梯度检验帮我节省了很多时间,也多次帮我发现backprop实施过程中的bug,接下来,我们看看如何利用它来调试或检验backprop的实施是否正确。


1.14 实现梯度检验的笔记(Gradient Checking Implementation Notes)
神经网络实施梯度检验的实用技巧和注意事项
