这是吴恩达深度学习第二模块第一周的内容,刚开始学习,文章里应该会有些理解错误的部分,多谢告知,qq: 2690382987
目录
蓝色字体是我自己的理解,红色字体是疑问待补充的,其他内容为对课程知识点的梳理。
训练集、验证集、测试集
在训练集上训练模型,根据验证集的效果选择最好的模型,测试集在最终模型上做模型评估。如果只有一个训练集和一个验证集,大多数人会把验证集称为测试集。
- 小数据量(如1万):训练集、验证集、测试集分别占60%、20%、20%
- 大数据量(如100万):训练集、验证集、测试集分别占98%、1%、1%;过百万的,比例还可以为99.5%、0.25%(0.4%)、0.25%(0.1%)
(验证集和测试集在实际工作中是怎么起作用的)
偏差、方差
高偏差(欠拟合);高方差(过拟合)
| Train set error | 1% | 15% | 15% | 0.5% |
| Dev set error | 11% | 16% | 30% | 1% |
| 过拟合 | 欠拟合 | 主要是因为高偏差造成的,从而带来了高方差 | 偏差和方差都很低 |
- 高偏差并高方差的造成:有可能是训练集中有异常值,过度拟合了异常值。
- 高偏差时增加训练集是没用的,是模型本身不合理
- 在正则适度的情况下,训练一个复杂模型,即可在不影响方差的同时减少偏差。
机器学习基础
构建模型的过程:
- 模型训练后,看偏差高不高?
- 如果高,选择新的网络模型或者优化现有模型的参数,使偏差降低到接受范围后看方差;
- 方差高的话,加正则减少过拟合
- 一直到找到一个低偏差、低方差的框架结束.
实际在做的时候是在损失函数时直接就设置正则,查看训练集在不同参数(学习率等)迭代时候的准确率召回率F1值以及测试集上的准确率召回率F1值来判断最优模型。
如何减少高方差(过拟合)?用正则化
只正则化参数w,因为w已经包含了大多数的参数,b可忽略不计。
为什么正则化有利于预防过拟合?
w过大会带来过拟合,正则化可以防止权重w过大(李弘毅视频里有另一种思路的解释,随后补充)。以激活函数tanh举例,λ增加,w^([l])降低(这个神逻辑我还没有找到缘由),z^([l])取值在0附近,激活函数在0附近趋向于线性,最终我们只能计算线性函数,对于复杂边界以及过度拟合数据集的非线性决策边界不太适用。
所有正则化或者类正则化的方式都是为了得到一个中等大小的恰当的w值,w太大会过拟合,太小神经网络又趋向于线性函数,会带来高偏差。
以逻辑回归为例:
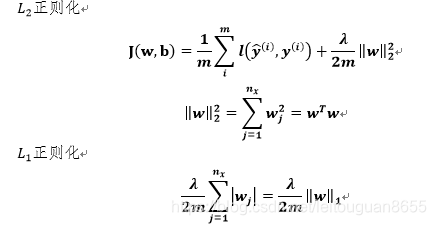
使用L_1正则化时w中会有很多0,但没有减少多少存储空间,约定俗成用L_2正则化。
以神经网络为例(L_2正则化):
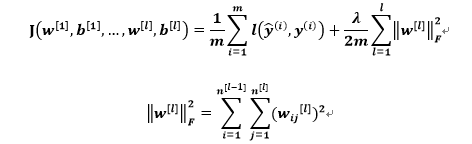
该矩阵范数被称作“弗罗贝尼乌斯范数”,也就是计算矩阵里每个元素的平方和。
权重更新时:
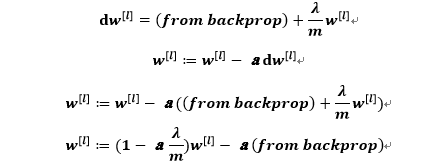
因此L_2范数正则化也被称为“权重衰减”。
dropout 正则化(随机失活)
- 样本分别过网络进行dropout,即不同的训练样本,清除不同的隐藏单元也不同,但对于同一样本,正反传播时用的是同一个d(失活矩阵)。
- 每层可以设置不同的keep-prob来决定该层的每一个节点是否失活,w元素多的层,keep-prob可设置小一点。
- 第0层的激活函数即x(输入特征)不使用dropout函数。
- 不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。
- 测试阶段不使用dropout函数,这样最终计算出来的y ̂不是随机的。
- 吴恩达老师的技巧是除了视觉领域,其他领域dropout用的很少,只有其他领域有过拟合时再用。
- keep-prob:不失活的概率,值为1时即为保留所有节点。
Dropout中最常用的方法是反向随机失活:正向传播时,激活函数计算出来的最后一层数值要除以keep-prob,为了不影响最后一层数值的期望值。
其他正则化方法
除了L_2正则化和随机失活正则化,还有其他的方式:
- 增加更多数据(如图像时可以尝试用gan生成新的图片)
- early stopping
验证集的误差一般会先慢慢降低然后再升高,训练集上的成本函数一般会一直降低,在验证集上的误差升高时,提早停止训练神经网络。是因为一开始w很小,慢慢的w会越来越大,中间停止也是为了得到一个中等大小的w。
early stopping不涉及正则,也就不涉及λ参数的调优,只要在迭代的过程中画一个图看一下就行。
early stopping不能独立地处理高方差和高偏差,“观察训练停止的时刻”这样做会让问题变得很复杂。同时为了减少过拟合,提前停止了训练也就意味着无法再继续优化代价函数,所以一般不用这种方法。
一般用不同的工具分别处理高方差和高偏差,代价函数里包含L_2正则,先优化代价函数,使偏差达到最小,但用正则方法的话,会导致搜索大量λ值的计算成本太高。
归一化输入
输入特征之间数值差距太大,需要做归一化处理,归一化后会加速训练,原因是:
特征之间数值差距大,会使w(w是个高维向量,w1,w2,w3,…)数值之间差距大,则成本函数关于w和b的函数曲面是个狭长的碗的形状,梯度下降时,必须要使用非常小的学习率。
而相反归一化后,w数值差距不大,成本函数关于w和b的曲面看起来很对称,是个圆一点的球形轮廓,梯度下降时,就可以使用大一点的学习率。
归一化方式:
把每一个输入特征都变成0均值,方差为1的向量,训练集和测试集都要用相同的μ和σ^2归一化,和统计上的处理方法一样,不同的是:
- 计算σ^2时除以的是m(样本量),而不是m-1;
- 归一化时课程里给的公式是:
(x-μ)/(σ^2)
(这里应该是个错误,但是暂时保留)
其中μ和σ^2 是在训练集上算出来的,不是把测试集和训练集放在一起估计μ和σ^2的(这个思路很奇葩啊,理解不了为啥不放在一起估计)。
视频里吴老师说他也不确定归一化后能否提高训练速度,但他经常这样做。
梯度消失和梯度爆炸
梯度消失:梯度下降时,导数突然很小
梯度爆炸:梯度下降时,导数突然很大

神经网络的权重初始化
合理的初始化可以减少梯度爆炸和消失,鉴于这样的思想:n(节点数)越大,w越小时,便可以尽量避免梯度爆炸。所以令:

意思就是说初始化w时一定要和w的方差有关系,初始化时给一个方差默认值,比如上面的1/n([l-1]),或者2/n([l-1])等。当然也可以把方差当作超参数来调优。
梯度的数值逼近
在梯度检验时使用双边误差,即用(f(Θ+ε)- f(Θ-ε))/2ε,而不是单边公差(f(Θ+ε)- f(Θ))/ε,因为不够准确。