文章目录
1. 训练,验证,测试集
深度学习是一个典型的迭代过程,迭代的效率很关键
创建高质量的训练数据集,验证集和测试集有助于提高循环效率
- 切分标准:
小数据量时代,常见做法是三七分,70%验证集,30%测试集;也可以 60%训练,20%验证和20%测试集来划分。
大数据时代,数据量可能是百万级别,验证集和测试集占总量的比例会趋于变得更小。
我们的目的就是验证不同的算法,检验哪种算法更有效,不需要拿出20%的数据作为验证集,很少的一部分占比的数据就已经足够多了。 - 数据来源:
最好要确保 验证集 和 测试集 的数据来自同一分布,因为要用验证集来评估不同的模型,如果验证集和测试集来自同一个分布就会很好
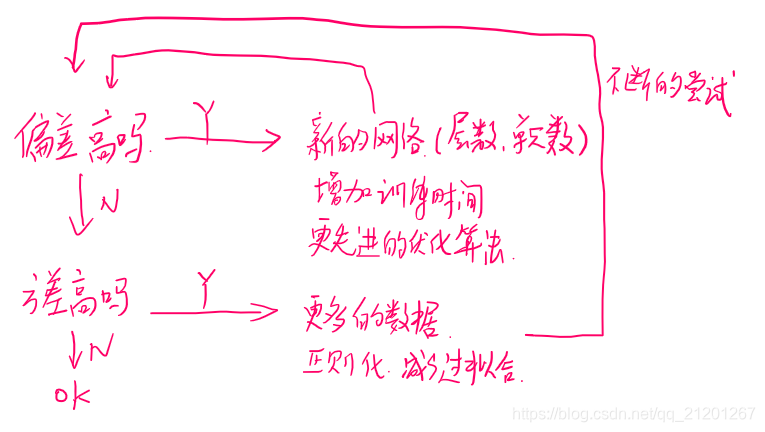
2. 偏差,方差
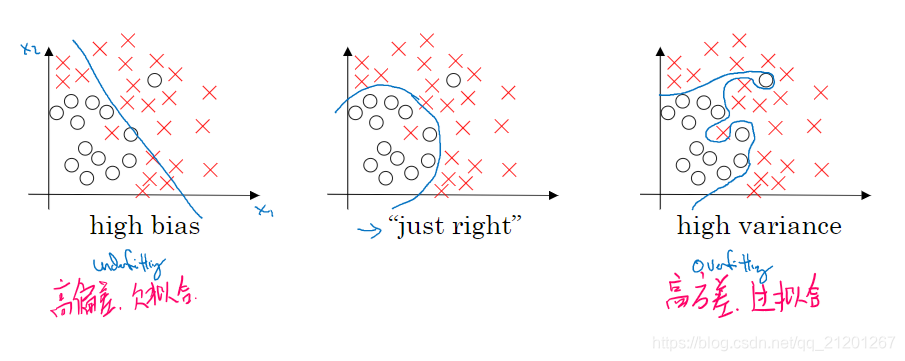
关键数据:
训练集误差、验证集误差

如果最优误差(贝叶斯误差,人分辨的最优误差)非常高,比如15%。那么上面第二种分类器(训练误差15%,验证误差16%),15%的错误率对训练集来说也是非常合理的,偏差不高,方差也非常低。
(以上基于假设:基本误差很小,训练集和验证集 来自相同分布)
根据这两个指标,更好的优化算法。
3. 机器学习基础
4. 正则化
正则化有助于防止过拟合,降低方差
- L1 范数: 表示非零元素的绝对值之和
- L2 范数:
表示元素的平方和再开方
矩阵的范数叫做:弗罗贝尼乌斯范数,所有元素的平方和
加上 L2 正则化 的损失函数:
- L1 正则,权重 w 最终变得稀疏,多数变成 0
- L2 正则,使得权重衰减
权重不但减少了,还乘以了小于1的系数进行衰减
5. 为什么正则化预防过拟合
当 设置的很大的时候,最终 会变得很接近于 0,神经网络中的很多单元的作用变得很小,整个网络越来越接近逻辑回归
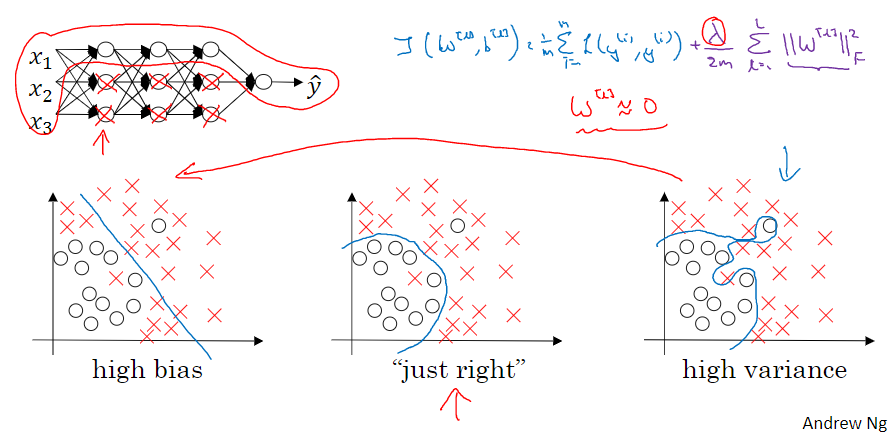
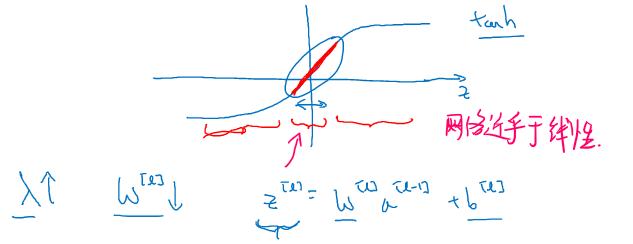
增大时,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,不是复杂的高度非线性函数,不会发生过拟合
L2 正则化是 训练深度学习模型时最常用的一种方法
6. dropout(随机失活)正则化
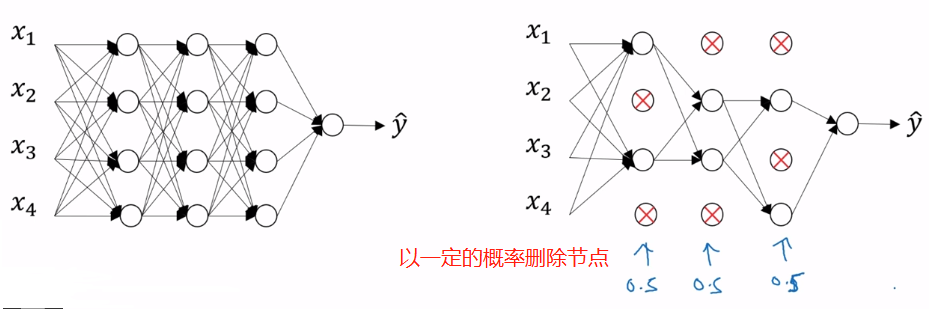
以上是一个样本的过程,其他样本也是同样的过程。
实施 dropout 举例:最常用的方法 - inverted dropout(反向随机失活)
用一个三层网络举例
- 定义向量
,
表示一个三层的 dropout 向量
d3 = np.random.rand(a3.shape[0],a3.shape[1]),对于元素小于 keep-prob 的,对应为 0,其概率为1 - keep_prob - 获取激活函数
,
a3 = np.multiply(a3, d3),使得 中为 0 的元素把 对应元素归零 - 向外扩展
,
a3 /= keep_prob
反向随机失活(inverted dropout)方法通过除以keep-prob,确保
的期望值不变
7. 理解 dropout
- 其功能类似于 L2 正则化
- 对于参数集多的层,可以使用较低的
keep-prob值(不同的层,可以使用不同的值),缺点是:需要交叉验证更多的参数
dropout 一大缺点就是:代价函数不再被明确定义,每次迭代,都会随机移除一些节点,想检查梯度下降的性能,实际上是很难进行复查的
- 可以先关闭
dropout,将keep-prob设置为 1,确保 J 函数单调递减 - 然后再尝试打开
dropout
8. 其他正则化
- 数据扩增,假如是图片数据,扩增数据代价高,我们可以:
水平翻转;随意剪裁旋转放大(这种方式扩增数据,进而正则化数据集,减少过拟合成本很低)

对于数字识别图片,我们可以进行旋转,扭曲来扩增数据集

- early stopping
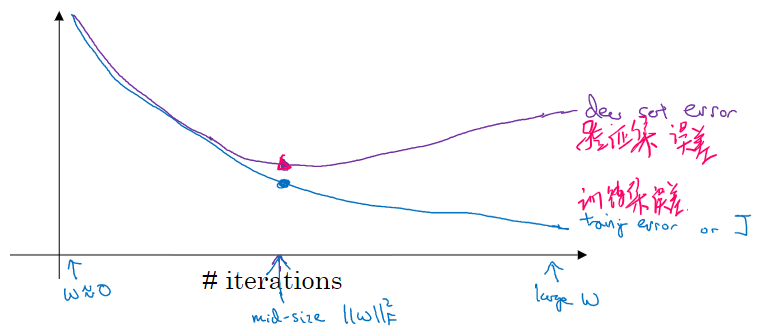
在验证集误差变坏的时候,提早停止训练
early stopping 缺点:不能同时处理 过拟合 和 代价函数不够小的问题
- 提早停止,可能代价函数 J 不够小
- 不提早结束,可能会过拟合
不使用 early stopping ,那么使用 L2 正则,这样训练时间可能很长,参数搜索空间大,计算代价很高
early stopping 优点:只运行一次梯度下降,可以找出 w 的较小值,中间值,较大值,无需尝试 L2 正则化超参数 的很多值
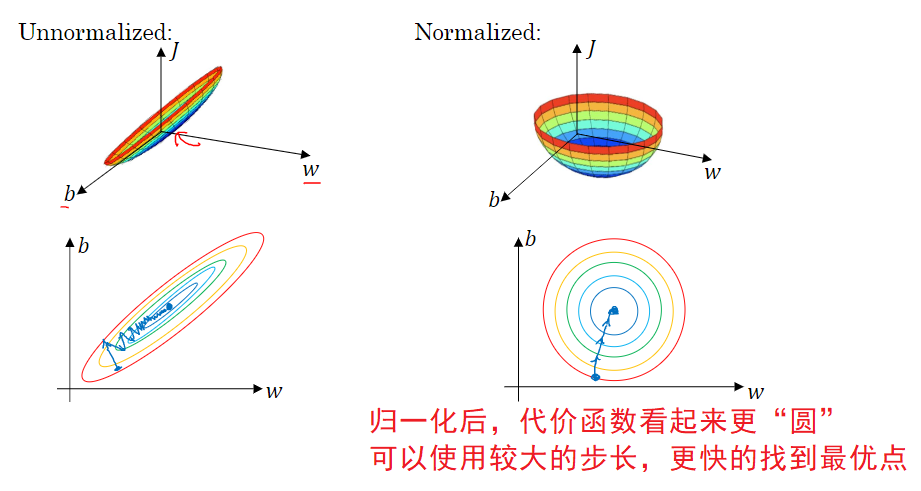
9. 归一化输入
归一化输入,可以加速训练
- 零均值(所有的数据减去均值)
- 归一化方差(所有数据除以方差)
注意:
是由训练集得到,然后用于其他所有数据集
10. 梯度消失 / 梯度爆炸
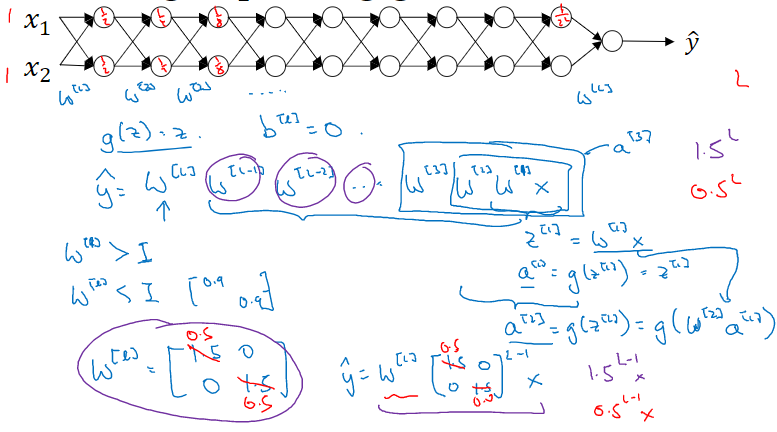
在非常深的神经网络中,权重只要不等于 1,激活函数将会呈指数级递增或者递减,导致训练难度上升,尤其是梯度与 L 相差指数级,梯度下降算法的步长会非常非常小,学习时间很长。
11. 神经网络权重初始化
上面讲到了梯度消失/爆炸,如何缓解这个问题?
为了预防 z 的值 过大 或 过小,n 越大时,你希望 wi 越小,合理的方法是
,n 是输入特征数量
, 是给第 层输入的特征数量
- 如果使用
ReLu激活函数(最常用), - 如果使用
tanh激活函数, ,或者
这样设置的权重矩阵既不会增长过快,也不会太快下降到 0
从而训练出一个权重或梯度不会增长或消失过快的深度网络
我们在训练深度网络时,这也是一个加快训练速度的技巧
12. 梯度的数值逼近
在反向传播时,有个测试叫做梯度检验
我们使用双边误差,
不使用单边误差,因为前者更准确。
13. 梯度检验
梯度检验帮助我们发现反向传播中的 bug
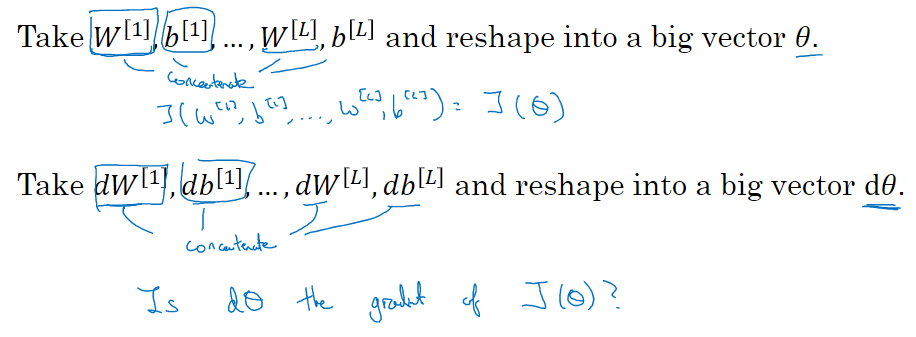
检验
检查上式的值是否
14. 梯度检验的注意事项
- 不要在训练中使用梯度检验,它只用于调试
- 如果算法的梯度检验失败,要检查所有项,检查每一项,并试着找出bug
- 如果使用了正则化,计算梯度的时候也要包括正则项
- 梯度检验不能与
dropout同时使用,可以关闭dropout,进行梯度检验,检验正确了,再打开dropout
作业
02.改善深层神经网络:超参数调试、正则化以及优化 W1.深度学习的实践层面(作业:初始化+正则化+梯度检验)
我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!
