少年,光看是不行的,我的github在这里,跟着做吧:https://github.com/singgel/NoSql-SkillTree
logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
以下以mysql为例,log同理
一、首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.3.1
下载后使用logstash-plugin install logstash-input-jdbc 命令安装jdbc的数据连接插件
二、新增mysqltoes.conf文件,配置Input和output参数如下,连接jdbc按照规则同步指定的数据到es
大家注意这里的配置有很多种用法,包括同步时间规则和最后更新时间的用法就不详细展开了
input {
stdin { }
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/star"
jdbc_user => "root"
jdbc_password => "123456"
jdbc_driver_library => "/Users/yiche/.m2/repository/mysql/mysql-connector-java/8.0.12/mysql-connector-java-8.0.12.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
statement => "SELECT * FROM channel_data_detail_month"
schedule => "* * * * *"
}
}
output {
stdout {
codec => json_lines
}
elasticsearch {
hosts => "localhost:9200"
index => "star"
document_type => "channel_data_detail_month"
document_id => "%{id}"
}
}使用logstash按照conf文件执行 ./bin/logstash.bat -f ./config/mysqltoes.conf
注意这里可能有执行不成功的坑,主要是把配置设置好,还有文件和名称编码的问题 output es的配置用hosts

这时候我们可以看到MYSQL中的表数据已成功导入ES

---
log日志的
1. 定义数据源
写一个配置文件,可命名为logstash.conf,输入以下内容:
input {
file {
path => "/data/web/logstash/logFile/*/*"
start_position => "beginning" #从文件开始处读写
}
# stdin {} #可以从标准输入读数据
}定义的数据源,支持从文件、stdin、kafka、twitter等来源,甚至可以自己写一个input plugin。如果像上面那样用通配符写file,如果有新日志文件拷进来,它会自动去扫描。
2. 定义数据的格式
根据打日志的格式,用正则表达式进行匹配
filter {
#定义数据的格式
grok {
match => { "message" => "%{DATA:timestamp}\|%{IP:serverIp}\|%{IP:clientIp}\|%{DATA:logSource}\|%{DATA:userId}\|%{DATA:reqUrl}\|%{DATA:reqUri}\|%{DATA:refer}\|%{DATA:device}\|%{DATA:textDuring}\|%{DATA:duringTime:int}\|\|"}
}
}由于打日志的格式是这样的:
2015-05-07-16:03:04|10.4.29.158|120.131.74.116|WEB|11299073|http://quxue.renren.com/shareApp?isappinstalled=0&userId=11299073&from=groupmessage|/shareApp|null|Mozilla/5.0 (iPhone; CPU iPhone OS 8_2 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Mobile/12D508 MicroMessenger/6.1.5 NetType/WIFI|duringTime|98||
以|符号隔开,第一个是访问时间,timestamp,作为logstash的时间戳,接下来的依次为:服务端IP,客户端的IP,机器类型(WEB/APP/ADMIN),用户的ID(没有用0表示),请求的完整网址,请求的控制器路径,reference,设备的信息,duringTime,请求所花的时间。
如上面代码,依次定义字段,用一个正则表达式进行匹配,DATA是logstash定义好的正则,其实就是(.*?),并且定义字段名。
我们将访问时间作为logstash的时间戳,有了这个,我们就可以以时间为区分,查看分析某段时间的请求是怎样的,如果没有匹配到这个时间的话,logstash将以当前时间作为该条记录的时间戳。需要再filter里面定义时间戳的格式,即打日志用的格式:
filter {
#定义数据的格式
grok {#同上... }
#定义时间戳的格式
date {
match => [ "timestamp", "yyyy-MM-dd-HH:mm:ss" ]
locale => "cn"
}
}在上面的字段里面需要跟logstash指出哪个是客户端IP,logstash会自动去抓取该IP的相关位置信息:
filter {
#定义数据的格式
grok {#同上}
#定义时间戳的格式
date {#同上}
#定义客户端的IP是哪个字段(上面定义的数据格式)
geoip {
source => "clientIp"
}
}同样地还有客户端的UA,由于UA的格式比较多,logstash也会自动去分析,提取操作系统等相关信息
#定义客户端设备是哪一个字段
useragent {
source => "device"
target => "userDevice"
}
哪些字段是整型的,也需要告诉logstash,为了后面分析时可进行排序,使用的数据里面只有一个时间
#需要进行转换的字段,这里是将访问的时间转成int,再传给Elasticsearch
mutate {
convert => ["duringTime", "integer"]
}
3. 输出配置
最后就是输出的配置,将过滤扣的数据输出到elasticsearch
output {
#将输出保存到elasticsearch,如果没有匹配到时间就不保存,因为日志里的网址参数有些带有换行
if [timestamp] =~ /^\d{4}-\d{2}-\d{2}/ {
elasticsearch { host => localhost }
}
#输出到stdout
# stdout { codec => rubydebug }
#定义访问数据的用户名和密码
# user => webService
# password => 1q2w3e4r
}我们将上述配置,保存到logstash.conf,然后运行logstash
在logstash启动完成之后,输入上面的那条访问记录,logstash将输出过滤后的数据:
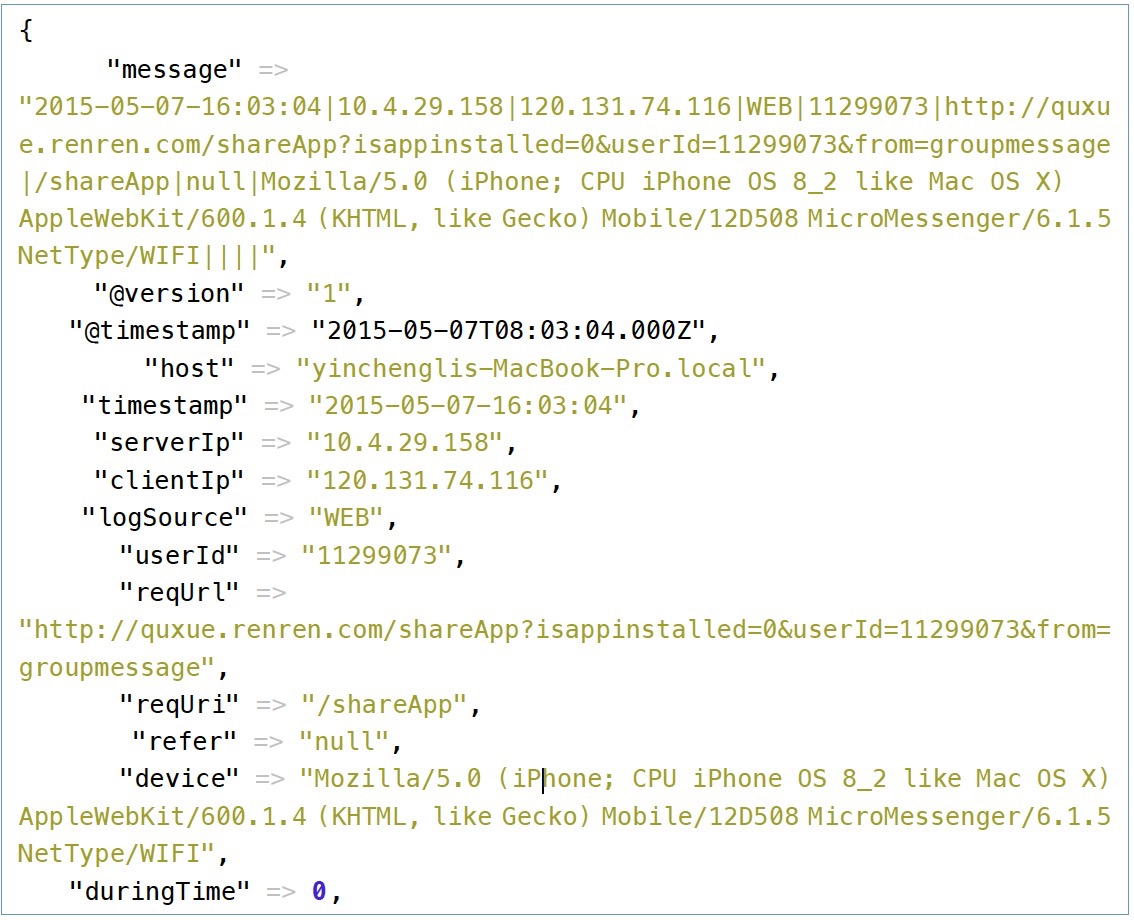

可以看到logstash,自动去查询IP的归属地,并将请求里面的device字段进行分析。