正则化
通常而言,深度学习的Regularization 方法包括:
1. L2正则化
2. Dropout
3. Data Augmentation
4. Early stopping
L2 正则化
“Weight decay”

L2正则为什么会有效果,为什么会regularization?
1. 当

2. 神经网络中

dropout
Inverted dropout, 为了保证输入、输出值的期望不发生变化,即

dropout的regularization效果:
1. 神经网络神经元数量减少,网络结构变简单,和正则化效果相同;
2. 解耦(具体可阅读《Improving neural networks by preventing co-adaptation of feature detectors》等论文);
3. 和L2正则化的效果相同(产生收缩权重的平方范数的效果shrinking the squared norm of the weights);
4. 添加乘性噪声。
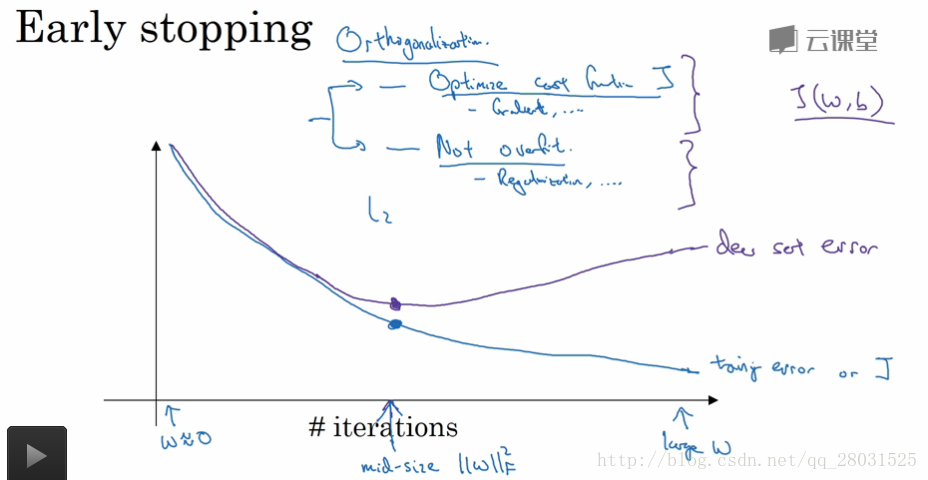
early stopping
early stopping的特性(缺点)
通常对于任何机器学习系统的学习可分为两步:
1、优化成本函数J,最优化包括RMSProp、Adam或其他包含momentum的方法等;
2、预防过拟合,包括一些正则化步骤。
但是early stopping将两者同时进行,无法保证学习的充分性。
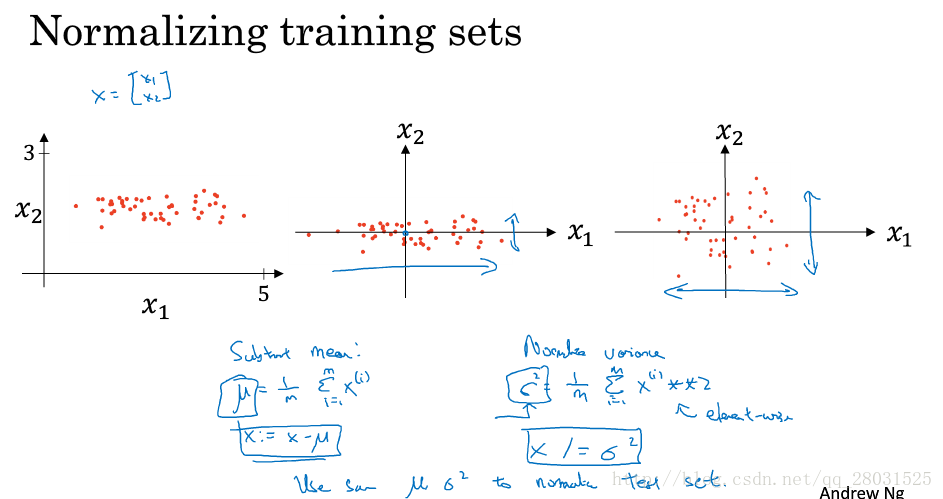
Normalizing inputs
使用0均值和方差为1的Normalization方法,在训练集上得到均值和方差并将其用到测试集上。
为什么使用Normalizing? 使得特征都在相似的范围内变化,加快训练速度。
神经网络初始化
在使用不同激活函数时,选择不同的初始化权重设置,但是一般这种加速训练的方法优先级不高。
下图He et al初始化方法配合Relu使用能够更好的更快的收敛。



第一周作业
forward-propagation:

back-propagation:(其中标红为relu激活函数反向求导的方法)

不同初始化参数效果
参数initialization的不同效果:
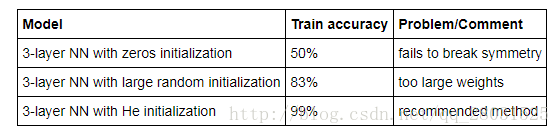
以上三种不同的参数初始化方法为:



其中可以看到,1、不同参数的初始化结果不同;2、随机初始化打破了参数对称性,使得不同的神经元学习到不同的知识;3、当随机初始化较大的参数值时,效果不好,收敛速度较慢;4、He initialization方法针对Relu激活函数效果较好。
Inverted Dropout
训练的时候采用dropout,在正向传播和反向传播时都需要采用dropout,在测试集上和正常的预测采用相同的方法。
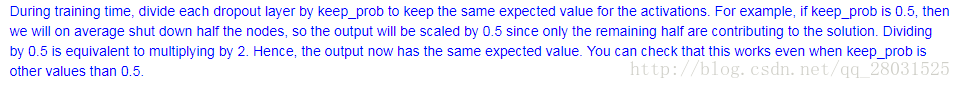
forward_propagation: 通过D1和D2将A1和A2进行部分关闭,然后Dropout(Inverted Dropout),需要通过A1/keep_prob得到和没有dropout相同的输入输出期望值。

back_propagation: 因为在前向传播的时候已经除以了keep_prob,那么在反向传播的时候为了保持相同的值也需要除以keep_prob,反向传播剩余部分和其他的相同。